| |

Java Big Data FrameworksBig Data is a huge volume of data collection, which is growing exponentially with time. Traditional database management tools can not handle big data. So, a large size of data is managed and processed using big data tools. There are several Big Data tools available to manage a huge amount of data efficiently. Nowadays, technologies are evolving very quickly and replacing the previous ones. But, Java technology is available for more than two decades and still a favorable choice for developers. It is used by millions of developers around the Globe and running efficiently on billions of devices. The main reason behind its stability is its updations; Java is updating itself with time. If we look up the Java version history, we can see that almost every year, a new version of Java is released with some updates and enhancements. If we look closely at the evolution of technologies, operating systems, and databases over the years, many things are changed. Nowadays, tech developers mainly focusing on the space with big data and IoT. When it comes to big data, Java is still the backbone for many big data frameworks. Java is naturally good for big data as some major core modules of popular Big data tools are written in Java. Also, one of the major advantages of using big data tools in Java is that some leading big data tools are open-source for Java developers. In this section, we will discuss the future of Java in big data and some popular big data frameworks for Java developers. Future of Java in Big DataIf we make a statement that "Java is the future of big data", it is worth it. Let's discuss why? As we have discussed earlier in this topic, the core parts of leading big data tools are written in Java. So, the root of big data is deeply ingrained in Java. Several open-source Java-based communities are contributing to making open-source big data tools. Nowadays, we can see exponential growth in data. Analyzing such a large amount of data will be continued to increase over the period time as well. One major way to analyze this data is batch data processing, which is mostly done by using open-source tools such as Hadoop and Spark. Both are Java-based tools. Hadoop is a big name in the big data spectrum. It is one of the prominent tools; for this tool, Java is the language. Hence, it is easy for Java developers to learn it. In fact, for Java developers learning Java-based big data tools is just like learning a new API in Java. Just like Hadoop, the Pig is also another easy option to learn for Java developers. Let's discuss some of Java features that allow it to easily deal with big data: Big Data Tools are Accessible for Java Most of the big data tools are accessible for Java so implementation of big data will be the cheapest possible tech stack & flexible. Java is Type-Safe It is crucial for data scientists to deal with a large amount of data with the huge set of information being processed. Java is type-safe, so it allows spending less time on unit testing and codebase maintenance. Java is Scalable Java is outstanding in terms of scalability. It supports a wide toolkit, a huge community, and cross-platform compatibility, which makes it a perfect choice for designing complex big data infrastructures. Java is Portable Java is portable, can be run on any hardware and software platform. This also makes it a good choice for big data. Java has Garbage Collection Java facilitates garbage collection and automatic memory distribution, which also be useful for big data processing. Java is Secure Security is one of the main reasons behind the popularity of Java. Thus, we can say Java has a shining future in the big data processing. Let's discuss some popular big data frameworks for Java: 1) Apache HadoopHadoop is a well-known name in big data management tools. It is an open-source framework provided by Apache Foundation. It efficiently stores and analyzes the huge volume of data. Hadoop is written in Java. 
The Apache Hadoop software library allows distributed processing of large data sets across clusters of computers. It is a leading big data tool designed to scale up from single servers to thousands of distributed machines. Some key features of Hadoop are as following:
2) Apache SparkApache Spark is similar to the Hadoop MapReduce framework, but it is getting much more popular than MapReduce in the big data processing. It is a cluster computing framework that can be run on thousands of machines. Further, it can be run on distributed computers for analyzing the massive datasets across these devices. The Spark works on the concept of RDD (Resilient Distributed Dataset). 
Spark performs large ETL (extract, transform, and load ) operations easily. Furthermore, it performs predictive analytics and reporting applications operations over large datasets. Apache Spark performs the following operations:
The Spark is written in Scala programming language, which inherently is written in Java. Hence, indirectly Java is the base of the Apache Spark stack and is fully supported by all its products. Its stack has an extensive Java API. Thus, The Apache is an easily adopted big data framework for the Java developer. The following are some of Spark's API that can be easily understood and used by the Java developer:
3) Apache StormThe storm is a free and open-source distributed real-time computational system for big data provided by the Apache foundation. It is an efficient tool for big data that makes it is easy to reliably process unbounded streams of data with real-time processing. It is an easy tool that can be used with any programming language. 
It facilitates real-time data processing, machine learning, continuous computation, ETL, distributed RPC, and more. It is a fast tool that performs over a million tuples processing per second per node. It is a distributed, scalable, fault-tolerant tool and easy to set up tool. It integrates with the queueing and available database technologies. Its architecture has two main components:
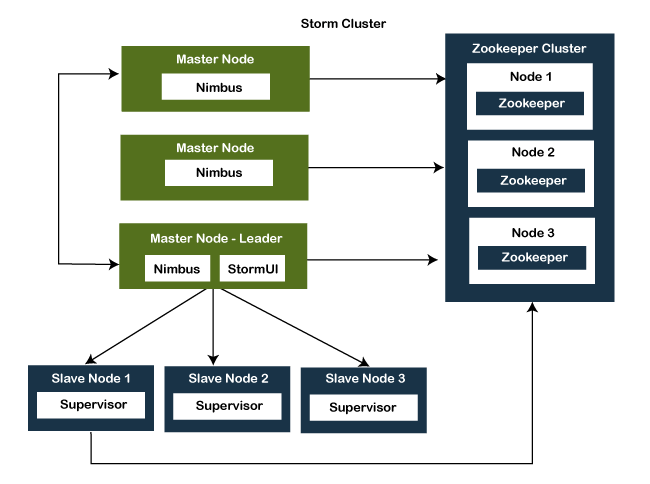
Some key features of Apache Storm are as following:
4) Java JFreeChartData visualization is also an integral task in big data analysis. As big data deals with a huge amount of datasets, it is also necessary to represent and look out for the raw data. When data is represented in a chart, it becomes easy to analyze data. JFreechart is one of the leading tools available for the visualization of data. It is an open-source tool with built-in libraries in Java to allow a user to easily generate professional-quality graphs and charts. 
We can create different types of visuals such as pie charts, bar charts ( with an optional 3D effect), scatter plots, Gantt charts, line charts, time series charts, and more using JFreeChart. JFreeChart library provides plug-in support in various IDE's such as Eclipse, Netbeans, and more. It provides several choices to add charts in our application. 5) Apache MahoutApache Mahout is also an open-source big data tool, which provides a Java ML library. It is an Apache Software Foundation product designed for Machine Learning. It enables machines learning with queries without being overly programmed. It supports scalable machine learning algorithms, extracts recommendations and relationships from data sets in a convenient way. 
The Mahout runs on Hadoop, using the MapReduce paradigm. With its data science tools, Mahout supports the following features:
Mahout's algorithms run on Hadoop. Thus, it performs well in a distributed environment. Furthermore, it provides inbuilt MapReduce implementations of several ML algorithms. 6) Deeplearning4jDeeplearning4j is also an important big data tool. I is a Java library that is useful for building different types of neural networks. It can also be integrated with Apache Spark on the big data stack can even run on GPUs. It provides several Java libraries with lots of built-in algorithms for deep learning and casting in Java. Additionally, it also has large communities and documentation. Some useful features of Deeplearning4j are as following:
7) HPCCHPCC is also the most widely used big data tool. It is developed by LexisNexis Risk Solution. HPCC system delivers on a single platform and provides an end-to-end data lake management solution. The HPCC provides an easy way to develop the data application. It is a simple, fast, accurate, and cost-effective tool. It is primarily developed for high-speed data engineering. 
Some useful features of HPCC are as following:
8) QuboleThe Qubole Data is an open-source autonomous Big Data management Tool. It is a self-managed and optimized tool that allows the data team to focus on the business outcome. 
Some useful features of Qubole are as following:
9) Couch DBThe CouchDB is also a vital tool for handling big data. It is used to store data in JSON documents that are accessible from the web or query using JavaScript. It provides distributed scaling with fault-tolerant storage. It defines Couch Replication Protocol to access data. 
Some useful features of CouchDB are as following: CouchDb works like other databases; it is a single node database.
10) Apache CassandraThe Cassandra database is a widely used big data tool. It provides effective management of large amounts of data. 
Some useful features of Apache Cassandra are as following:
Summary:We have discussed some widely used big data tools. These tools are not prioritized on any basis. It is all up to you; you can choose any of the discussed tools as per your need.
Next TopicJava Get Data From URL
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








