| |

R-Random ForestThe Random Forest is also known as Decision Tree Forest. It is one of the popular decision tree-based ensemble models. The accuracy of these models is higher than other decision trees. This algorithm is used for both classification and regression applications. In a random forest, we create a large number of decision trees, and in each decision tree, every observation is fed. The final output is the most common outcome for each observation. We take a majority vote for each classification model by feeding a new observation into all the trees. An error estimate is made for cases that were not used when constructing the tree. This is called an out-of-bag(OOB) error estimate mentioned as a percentage. The decision trees are prone to overfitting, and this is the main drawback of it. The reason is that trees, if deepened, are able to fit all types of variations in the data, including noise. It is possible to address this by partial pruning, and the results are often less than satisfactory. R allows us to create random forests by providing the randomForest package. The randomForest package provides randomForest() function, which helps us to create and analyze random forests. There is the following syntax of random forest in R: Example:Let's start understanding how the randomForest package and its function are used. For this, we take an example in which we used the heart-disease dataset. Let's start our coding section step by step. 1) In the first step, we have to load the three required libraries i.e., ggplot2, cowplot, and randomForest. 2) Now, we will use the heart-disease dataset present in http://archive.ics.uci.edu/ml/machine-learning-databases/heart-disease/processed.cleveland.data. And then, from this dataset, we read the data in CSV format and store it in a variable. 3) Now, we print our data with the help of head() function which prints only the starting six rows as: When we run the above code, it will generate the following output. Output: 
4) From the above output, it is clear that none of the columns are labeled. Now, we name the columns and make these columns labeled in the following way: Output: 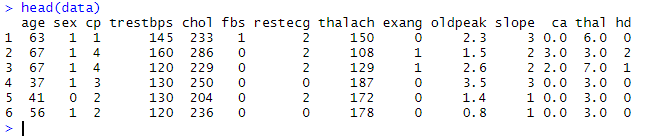
5) Let's check the structure of the data with the help of str() function to analyze it better. Output: 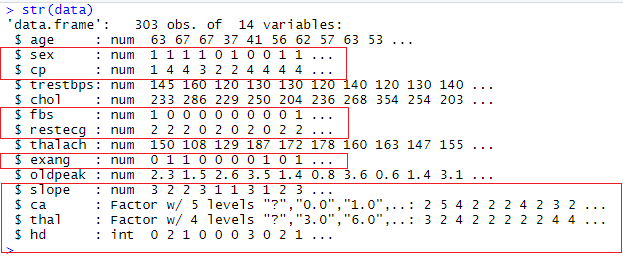
6) In the above output, we highlight those columns which we will use in our analysis. It is clear from the output that some of the columns are messed up. Sex is supposed to be a factor where 0 represents the "Female" and 1 represents the "Male". And cp(chest pain) is also supposed to be a factor where level 1 to 3 represent a different type of pain, and 4 represent no chest pain. The ca and thal are factors, but one of the levels is "?" when we need it to be NA. We have to clean up the data in our dataset, which are as follows: Output: 
7) Now, we are randomly sampling things by setting the seed for the random number generator so that we can reproduce our result. 8) NWxt, we impute values for the NAs in the dataset with rfImput() function. In the following way: Output: 
9) Now, we build the proper random forest with the help of the randomForest() function in the following way: Output: 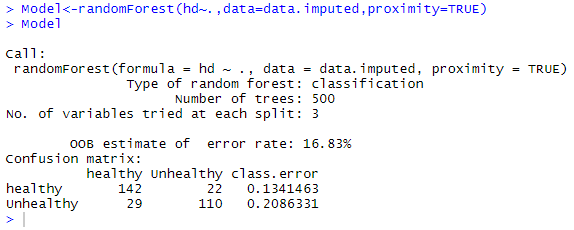
10) Now, if 500 trees are enough for optimal classification, we will plot the error rates. We create a data frame which will format the error rate information in the following way: 11) We call the ggplot for plotting error rate in the following way: Output: 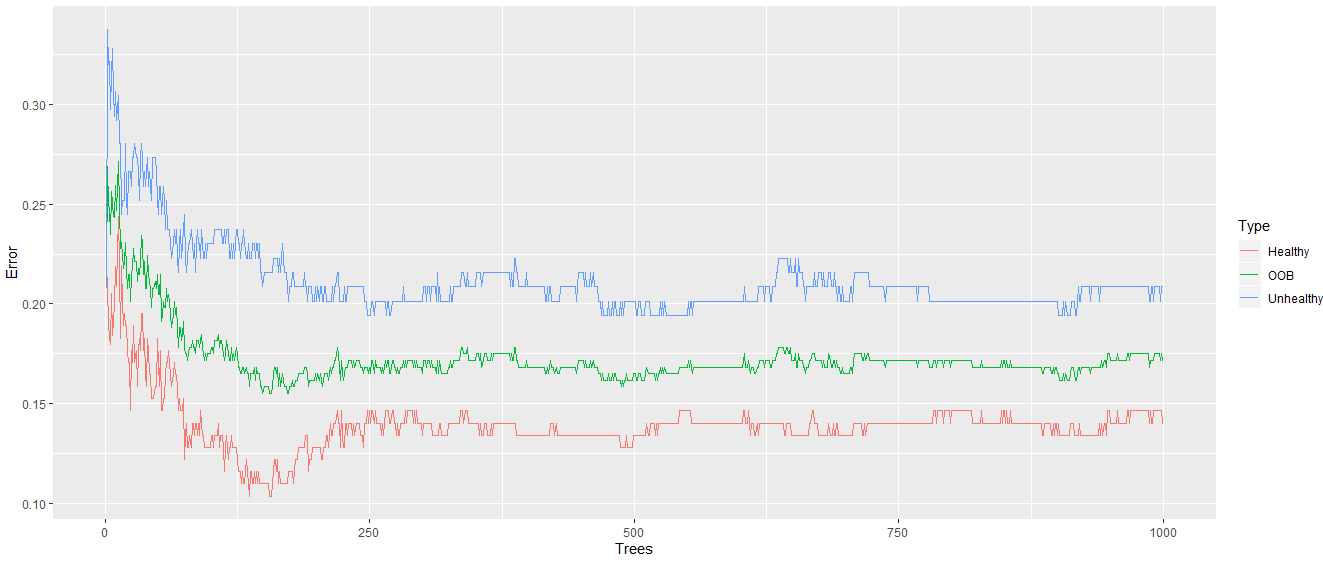
From the above output, it is clear that the error rate decreases when our random forest has more trees. 12) Now, we add 1000 trees and check would the error rate goes down further? So we make a random forest with 1000 trees and find the error rate as we have done before. Output: 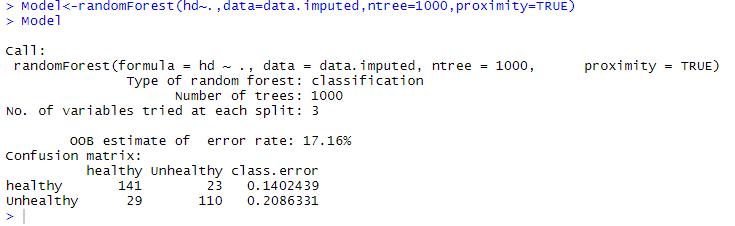
Output: 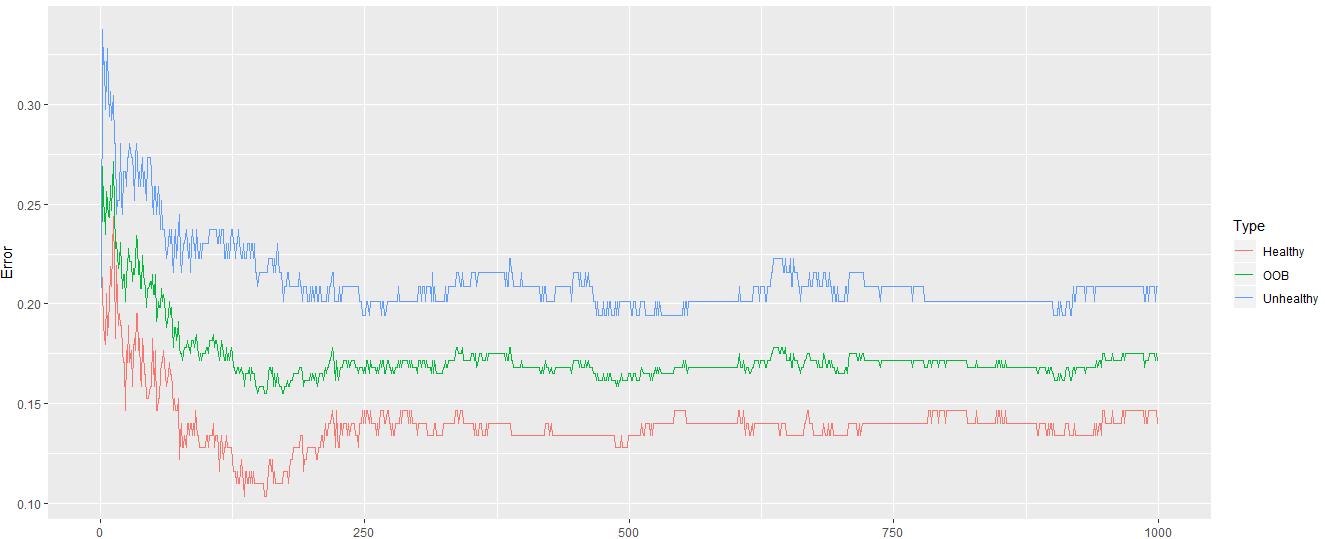
From the above output it is clear that the error rate is stabilized. 13) Now, we need to make sure that we are considering the optimal number of variables at each internal node in the tree. This will be done in the following way: Output: 
14) Now, we use the random forest to draw an MDS plot with samples. This will show us how they are related to each other. This will be done in the following way: Output: 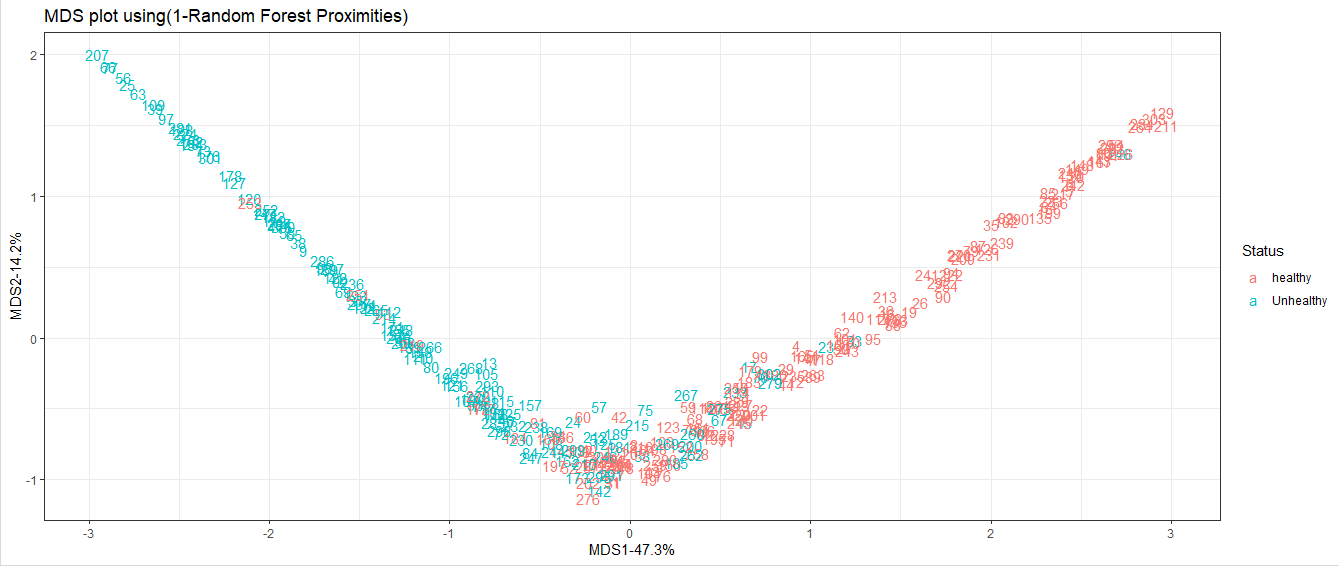
Next TopicT-Test in R
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








