| |

Unsupervised Artificial Neural NetworksLearning is a fundamental component required by every human being in the creation of intelligence. Humans derive their intelligence from the brain's capacity to learn from experience and utilizing that to adapt when confronted with existing and new circumstances. Reproduction of human intelligence in machines and computers is the objective of artificial intelligence techniques, one of which is an Artificial Neural Network. ANNs are models defined to mimic the learning capability of human brains. Like humans, validation, training, and testing are significant components in making such computational models. Artificial Neural Networks acquire information by getting some datasets (might be labeled or unlabeled) and computationally changing the network's free parameters adapted from the environment through simulation. Based on the learning rules and training process, learning in ANNs can be sorted into supervised, reinforcement, and unsupervised learning. 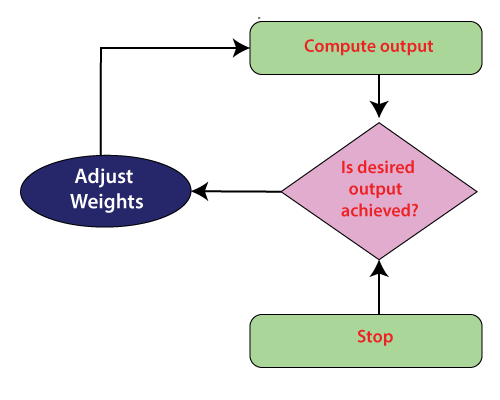
Supervised learning:In supervised learning, the artificial neural network is under the supervision of an educator (say a system designer) who utilizes his or her knowledge of the system to prepare the network with labeled data sets. Thus, the artificial neural networks learn by receiving input and target the sets of a few observations from the labeled data sets. It is the process of comparing the input and output with the objective and computing the error between the output and objective. It utilizes the error signal through the idea of backward propagation to alter the weights that interconnect the network neuron with the point of limiting the error and optimizing performance. Fine-tuning of the network proceeds until the set of weights that limit the discrepancy between the output and the targeted output. The supervised learning process is used to solve classification and regression problems. The output of a supervised learning algorithm can either be a classifier or predictor. The application of this process is restricted when the supervisor's knowledge of the system is sufficient to supply the network's input and targeted output pairs for training. Unsupervised learning:Unsupervised learning is used when it is absurd to augment the training data sets with class identities(labels). This difficulty happens in situations where there is no knowledge of the system, or the cost of obtaining such knowledge is too high. In unsupervised learning, as its name suggests, the ANN is not under the guidance of a "teacher." Instead, it is provided with unlabelled data sets (contains only the input data) and left to discover the patterns in the data and build a new model from it. In this situation, ANN figures out how to arrange the data by exploiting the separation between clusters within it. Reinforcement learning:Reinforcement learning is another type of unsupervised learning. It includes cooperation with the system, getting the condition of such a system, choosing an activity to change this state, sending the action to a system and accepting a numerical reward or a penalty in the form of feedback which can be positive or negative with the target of learning a policy. Activities that boost the reward are chosen by trial and error techniques. The figure illustrates the block diagram to describe the concept of reinforcement learning. Reinforcement and unsupervised learning are different from each other in many aspects. Reinforcement learning includes learning policy by maximizing a few rewards. The objective of unsupervised learning is to exploit the similarities and differences in the input data, which is used for categorization later. 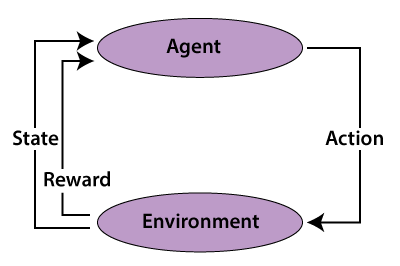
While supervised learning prompts to regression and classification, unsupervised learning plays out the tasks of pattern recognition, data dimensionality reduction, and clustering. Unsupervised learning is aimed at discovering some patterns in the input data. Recognition of patterns in unlabeled datasets prompts clustering. One of the significant stages of recognition systems is pattern recognition. Pattern recognition has discovered application in data mining, classification of documents, diagnosing diseases, recognize faces, etc. Data mining, as its name suggests, includes automatic or semi-automatic mining extracting useful information, patterns from huge datasets. Self-organizing maps are artificial neural network algorithms used for data mining. Huge data can be analyzed and visualized proficiently by self-organizing maps. Unsupervised neural networks, based on the self-organizing map, were used for the clustering of medical data with three subspaces named as patient's drugs, body locations, and physiological abnormalities. The self-organizing map was used to analyze and visualize yeast gene expression, and distinguished as an excellent, quick, and advantageous procedure for organization and interpretation of huge data sets like that of yeast gene expression. Unsupervised learning also plays out the task of lessening the number of variables in high dimensional data, a process known as dimensionality reduction. Data dimensionality reduction tasks can be additionally segmented into feature extraction and feature selection. Feature selection includes selecting a subset of the significant variable from the original dataset. Transformation of the dataset in high dimensional space to low dimensional space is considered as feature extraction. The principal component analysis is one of the best strategies for extracting linear features. In auto-coders with weights, initialized effectively was exhibited as a better tool than principal components analysis for data dimensionality reduction. Dimensionality reduction of data is normally performed at the pre-processing phases of other tasks to minimize computational complexity and improve the performance of machine learning models. In performance component analysis, an unsupervised learning algorithm was used to reduce the dimension of the data before classification for improvement in execution and better computational speed. |
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








