| |

Web crawler JavaThe web crawler is basically a program that is mainly used for navigating to the web and finding new or updated pages for indexing. The crawler begins with a wide range of seed websites or popular URLs and searches depth and breadth to extract hyperlinks. The web crawler should be kind and robust. Here, kindness means that it respects the rules set by robots.txt and avoids frequent website visits. The robust means the ability to avoid spider webs and other malicious behavior. These are the following steps to create a web crawler:
We use jsoup, i.e., Java HTML parsing library by adding the following dependency in our POM.xml file. Let's start with the basic code of a web crawler and understand how it works: WebCrawlerExample.java Output: 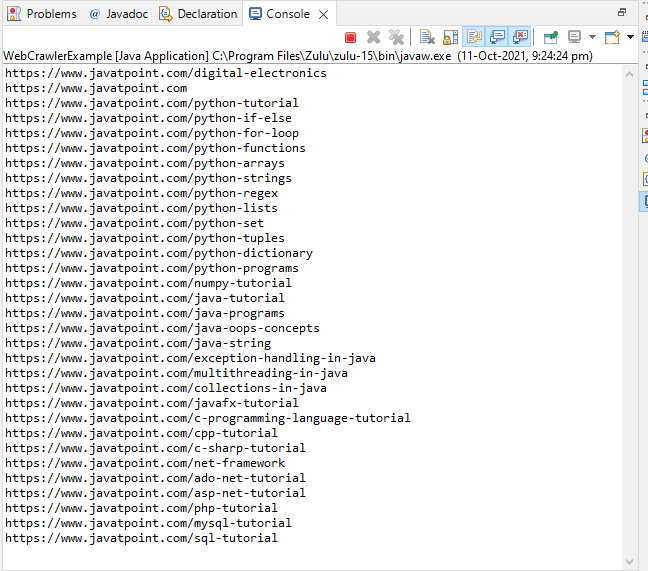
Let's do some modifications to the above code by setting the link of depth extraction. The only difference between the code of the previous one and the current one is that it crawl the URL until a specified depth. The getPageLink() method takes an integer argument that represents the depth of the link. WebCrawlerExampleWithDepth.java Output: 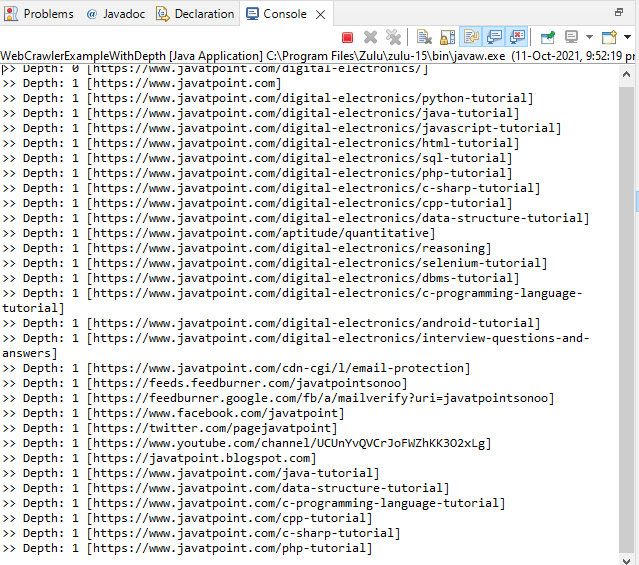
Difference Between Data Crawling and Data ScrapingData crawling and Data scrapping both are two important concepts of data processing. Data crawling means dealing with large data sets where we develop our own crawler that crawl to the deepest of web pages. Data scrapping means retrieving data/information from any source.
Let's take one more example to crawl articles using a web crawler in Java. ExtractArticlesExample.java Output: 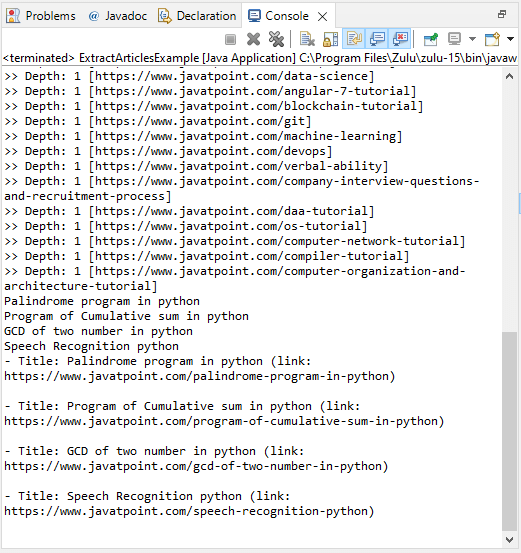
Output: |
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








