| |

AWS Lambda in JavaAWS lambda is a "service less" compute service that the developers do not have to worry about which AWS resources to launch or how they will manage them. They just put the code on Lambda, and it runs. However, a lambda can only use to execute background tasks. AWS Compute DomainThe primary services under this domain are EC2, Elastic Beanstalk, and AES Lambda. Among these three, the essential service is EC2, a raw server like a personal computer we are working on remotely. It can install any operating system of our choice, supported by the AWS infrastructure, and then we can use it in any manner we want; we can configure it to become a web server, and we can configure it to become a workout environment. Elastic Beanstalk It is the automated version of EC2, and with this elastic beanstalk, we will not get the excess to the operating system. However, we still have control over the configuration of our system so that we can choose what kind of instance we want to launch. So elastic beanstalk is used to deploy an application, and we only upload our code, and then the application is deployed on the AWS infrastructure. AWS Lambda The AWS Lambda service is an automated version of EC2 where we do not get access to the operating system. With AWS Lambda, we do not even have the choice to choose what configuration we want with our server. In AWS Lambda, we have to upload our code, which will execute. Why AWS Lambda?As we discussed, it is the automated version of EC2 like an elastic beanstalk, but with AWS Lambda, we can only execute background tasks. We cannot deploy an application, so AWS Lambda is not used to deploy an application but is used to perform background tasks. We do not have to choose the configuration in an AWS Lambda, and we do not want to decide what kind of service we want, and depending on our workload, the type of server configuration is assigned to us. So, this is why we use AWS Lambda. AWS SDKsSDKs are nothing but software development kits, and these are APIs that developers use to connect to the desired service at the wall. So, it makes the life of the developers easy because they can now concentrate on the logical part of their application rather than wasting time on understanding how they can connect their code to the service, which is on AWS. One can use AWS services in our applications with an API tailored to our programming language or platform. AWS SDKs are called Software Development Kits, APIs defined for specific programming languages. These APIs can be integrated with an IDE and thus can be easily used. Another part is that these SDKs will use with IDEs, and at present, we have only two supported IDEs: Eclipse and visual studio. Where is Lambda Used?There is a vast number of ways that businesses use AWS Lambda; some of them are: AWS Lambda is used to process images when it is uploaded, or let us say an object gets uploaded in a bucket in a format that we do not expect it to be which means the file needs to be formatted, so it gets uploaded in a raw form, and AWS Lambda has triggered a new object anytime is added to the bucket, and the images are processed and converted into thumbnails based on the device. The device can be a PC like an apple machine, Android, and tablet. Based on the device's different formats, a lambda can get triggered and convert the video or picture into the other form required. Another use case for Lambda is to analyze social media data. Let us say we are collecting the hashtag trending data, and the data is received. It is added into the Amazon Kinesis to feed into the Amazon environment. Lambda action gets triggered, and it receives the data, and then the data is stored in the database, which businesses can use for later analysis. Some companies that have gotten tremendous benefits from using Lambda are Thomson Reuters, Benchling, Nordstrom, Coca-cola, and Robot; some companies, to name a moment, have received enormous help from Lambda. How does Lambda Work?The clients send data to Lambda, and clients could be anyone who is sending requests to AWS Lambda. It could be an application or other Amazon web services that send data to Lambda. Then Lambda receives the request depending on the data size, amount, or volume of the data it runs on the defined number of containers. If it is a single request or fewer requests, it runs on a single container. So, the recommendations are given to the container to handle, and the container which contains the code the user has provided to satisfy the query would run. 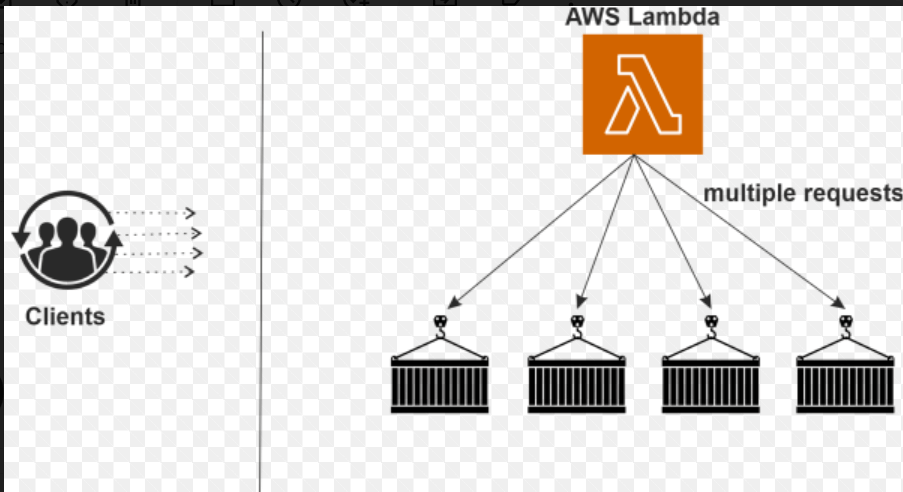
The container image is a lightweight standalone executable package of a piece of software that includes everything needed to run it, like the codes, the runtimes, the system tools, the system libraries and the settings required. It is currently available both on Linux and Windows-based applications, and container rise to software will always run the same regardless of the environment it is running on, and containers isolate software from its surroundings. For example, there could be a difference between a development and a staging environment. So that is isolated, which helps reduce the conflict between the teams running different software on the same infrastructure. At last, we understood that Lambda sends multiple requests to containers and shares the multiple requests to the different containers there. When the request reduces, the number of containers will also be reduced, which will help save the cost. We do not charge for the resources; we only charge for the time a function runs inside these containers. Use case- Backing up data Now consider a situation where we have to set up a temporary storage system to back up data as soon as it is uploaded, which is a near real-time backup. Near real-time manual backups are nearly impossible, and they are not that efficient near real-time manual backups, and that's what the business demands, but that is not near real-time backup that standard is not efficient even if we come up with a solution of manually backing out close to near real-time. It will not look efficient at the amount of data that will be put in, and looking at the random times to set the data in the source bucket; there is no way we can do a manual backup. AWS Lambda manually handles the backup. In other words, for an impossible or difficult situation like that, AWS Lambda comes to the rescue. Create two S3 buckets; one would be the source bucket where the data will upload, and the other is the destination bucket where the data is backed up from the source bucket. For these buckets to talk to themselves, it will require an IAM rule, and then for the automatic copy, it will need a Lambda function to copy files between those buckets. What Triggers the Lambda Function?The Lambda function is triggered every time there is a change in the metadata for the bucket, and this data is then uploaded into the destination bucket. After setting all this up, we can test it by putting information in the source bucket that will automatically replicate or copy the data. Let us see how we can replicate data between two buckets. So, for this, we have a feature to cross region replicate in its feature that comes along with S3. If we want to copy between two different buckets in two separate accounts in those cases, we can use Lambda to replicate the data between the buckets, so we put one data, or we put data in the source bucket. That data gets copied to the destination bucket, and let us see how that is done. The procedure here is to have two buckets, to begin with, and then create an IAM rule that will let us access to pull the data from the source bucket and put the data on the destination bucket, and then create Lambda files or Lambda event or triggers to look for an event in the source bucket and anytime new information gets added. Lambda gets triggered, copies the data from the source bucket and moves it to the destination bucket, and it uses the IAM rule and policy for the needed permissions. What is the Cloud?Before cloud computing, we want to host a website; these are the following things that we would need to do: First, we must buy a lot of servers because we will be hosting a website on something, and every website has a peak time. Secondly, keeping the peak time in mind, we should buy more servers. Thirdly, we must monitor and maintain these servers since these are our servers, and we must continuously monitor them so our application will not experience downtime. So, these things will lead to the problem. Disadvantages of cloud
These are the problems we face before cloud computing. Now, we must fix these. Cloud computing uses
Cloud computing uses remote servers on the internet to store, manage and process data rather than a local server on our personal computer. AWS Database ServicesThere are mainly five database services. 1. Relational database management services (RDS)We must understand that RDS is not a database but a database management service that manages our databases. It works with relational databases and databases like MySQL, Oracle, MariaDB, PostgreSQL, Microsoft SQL server or Amazon Aurora. It will update the DB engines automatically, install the security patches automatically, and do everything that had to be done manually or manually if we are hosting a database server; it does that automatically for us, and that's why it is called a management service. Everything will be done automatically by RDS. 2. Amazon AuroraAmazon Aurora is a database which Amazon itself has developed. So, it is included in RDS, a relational database that RDS also manages. The difference between Amazon Aurora and the other databases already out is Amazon Aurora is based on MySQL. It means that the code we are using MySQL will also work with Amazon Aurora. But then, Amazon claims that Amazon Aurora is five times faster than MySQL. If we replace the MySQL server with an Amazon Aurora server, we will experience five times boost in our performance, and this is what Amazon claims, and that is what Amazon Aurora. If we use Amazon Aurora and we were using MySQL before, we do not have to change our code because it will work the same with the code as it was when we were working with MySQL. 3. DynamoDBDynamoDB is also a management service, but it manages non-relational databases. That is, NoSQL databases. If we have unstructured data that must be stored in a database, so we cannot store it in the relational databases, we must keep it in a non-relational database, and DynamoDB manages the non-relational databases. It is also managed automatically and will get updated; the security patches are installed automatically, DynamoDB does everything, and no manual intervention is required. We do not have to specify the space we need; the moment more data comes in, the database automatically scales, it will grow automatically and shrinks automatically, and there is no need for manual intervention. 
If the storage is coming low, nothing is required in DynamoDB; we only move to the DynamoDB console and start creating new tables, and it will not ask for anything. 4. ElastCacheElastiCache is a caching service used to set up, manage and scale a distributed environment in the cloud. It means suppose we have an application and query something from a database; the database will process the query and, in turn, give us a result. If there is a lot of demand for a specific kind of result set, then the same query will run, again and again, increasing the overhead on our database in getting the same results. 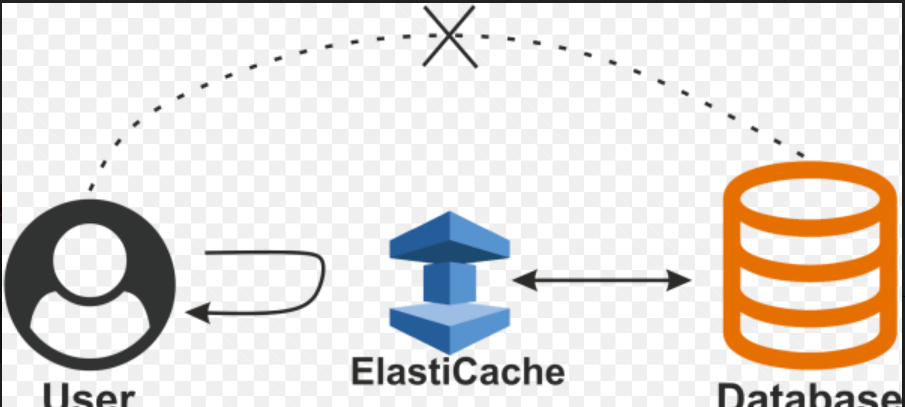
So, with ElastiCache, the user first accesses the query from the database. Still, now that it has been analyzed that this query is being asked very frequently, it stores the result set in ElastiCache. Whenever that query comes in, it directly feeds in that result. So, the database's overhead is reduced because the request never reaches the database. After all, it has already been processed and is stored in ElastiCache and the ElastiCache, in turn, serves the user with the result. Hence, this process becomes faster, which is all about what ElastiCache is about. 5. RedShiftRedShift is a data warehouse service, and it is a petabyte-scale data warehouse service. It gets data from RDS, and it gets data from DynamoDB, and it does not analyze on its own. It is an analysis tool and a data warehouse service that can analyze all the data stored on our databases, like RDS or DynamoDB. We can feed the data from RDS and DynamoDB as well. AWS Networking ServicesThe AWS networking services will show what the networking domain offers all the services. There are mainly three networking services: 1. VPC (Virtual Private Cloud)A virtual private cloud is a virtual network, and if we include all the AWS resources, we have launched inside one VPC, then all these resources become visible to each other or interact with each other once they are inside the VPC. The other use of VPC is when we have a private data Centre, and we are using AWS infrastructure to be used as if they were on our network. In that case, we will establish a "virtual private network" that is a VPN connection to our private cloud, in which we have included all the services we want on our private network. We will connect our private network to the VPC using the VPN, and then we can access all our AWS resources as if they were on our network, which is what VPC is all about. It provides us with the security and communication between the AWS services accessible, and it also helps us to connect our private data center to the AWS infrastructure. 2. Direct ConnectDirect Connect is a replacement for an internet connection; it is a leased line, a direct line to the AWS infrastructure, so if we feel that the bandwidth of the internet is not enough for our data requirements or networking requirements, we can take a leased line to the AWS infrastructure in the form of the Direct Connect service, so instead of using the internet, we would now use the Direct Connect service for our data stream to flow between our data Centre to the AWS infrastructure, and that is what Direct Connect is all about. 3. Route 53Route 53 is a domain name system. A domain name system is whenever we enter a URL; it must be directed to a domain name system which converts the URL to an IP address; the IP address is of the server on which our website is being posted. It functions like when we buy a domain name; the only setting we can do in that domain name, or the setting required in the domain name is the name servers. Now, these name servers are provided to us by Roue53. These name servers that Route53 gives us are to be entered in the settings of that domain name. 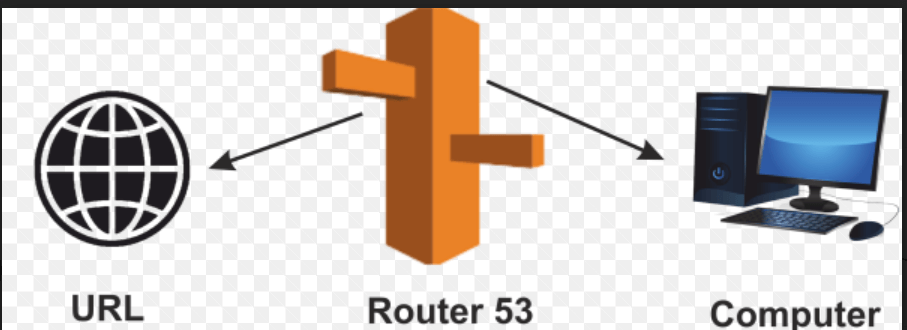
So, whenever a user points to that URL, the user will point to Route53. The work and the domain name setting are done, and we would have to configure Route53 now. Now that our request has reached Route53, it must be pointed to the server on which our website is hosted. So, on Route53, now we must enter the IP address or the instance to which we want our traffic to be directed. Our URL will directly get pointed to Route53, which will point to the example on which our application or website is being hosted. AWS Management ServicesThe management domain includes all the below services: 1. CloudWatchCloudWatch is a monitoring tool that monitors all our AWS resources in our AWS infrastructure. Now, let us see how we can watch all of them. Suppose we want to monitor our EC2 instance and be notified whenever our EC2 model CPU usage exceeds 90%. So, we can create an alarm in CloudWatch. Whenever our usage crosses 90%, it will figure a warning. That alarm, in turn, will send us a notification like an email or maybe whatever the parameter we set, we will receive a notice in that scene, so this is what CloudWatch is all about. We can say that we can set alarms and turn to reactions from our AWS resources. 2. CloudFormationCloudFormation is used to templatize our AWS infrastructure. We need to templatize our AWS infrastructure because we have different environments and want to launch the same infrastructure in different environments. When we create infrastructure and do not want to make that again, we can always take a snapshot of it using the CloudFormation; we can templatize this infrastructure and use it in other test environments. Suppose we have a test, product, and debit environment and want the same infrastructure in all three environments. We can do that using CloudFormation. So, CloudFormation is a tool to templatize our AWS infrastructure. 3. CloudTrailCloudTrail is a logging service from AWS. We can log all our API requests and API responses in CloudTrail when we want to troubleshoot a problem. Suppose we get some error while we are using an application, and since there can be countless cases where we do not get an error, but in the particular case we get an error, now we have to track down the problem. We will track it down using the logging service. So, since every request is logged using CloudTrail, we can go to that particular log where the error occurred, jot down the problem, jot down the line where the error is happening, and then solve it is all about what CloudTrail is all about. How are the logs stored? Suppose CloudTrail is enabled on a particular service, so CloudTrail will generate logs and store those logs in S3, a file system provided by AWS. 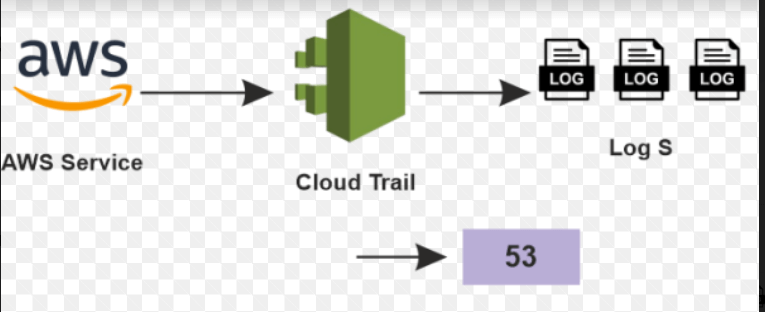
So, this is how the whole process happens. 1. CLI (Command Line Interface)CLI is a command line interface, replacing our GUI (Graphical User Interface). We can also use the command line to deploy instances, and the way to do that is by using AWS CLI. It is just a replacement for our GUI for any request. 2. OpsWorksAWS OpsWorks is a configuration management tool. It consists of two parts, and they are stack and layers. Layers are different AWS services that we have combined, and when we combine them, this whole system is known as a stack. We need a configuration management tool when we suppose we have an application using a host of AWS services. We want to change something fundamental one way to change this is by going to every service particularly and changing that setting and the following method to do this using OpsWorks. If we have deployed our application using OpsWorks, one basic setting we have to change in all our infrastructures can be at the stack level. All our resources, all the services we are using and different layers in that stack are known as a stack. The AWS infrastructure as a whole would be known as a stack, and if we have to change the setting, we will have to change it at the stack level and automatically, it will be implemented to all the levels. So, this is how OpsWorks functions. 3. Trusted AdvisorThe trusted advisor is like a personal assistant to the AWS infrastructure, advising us on our monthly expenditures. Suppose we have the best practice, and if we use that practice, we can reduce our expenditure. They would recommend we use our IAM policies if it recognizes that many users and different people are using our AWS account. We have not set up any IAM policies on our AWS account; it will advise us to create those IAM policies, enabling us to improve our AWS account. AWS Security ServicesThe AWS security domain includes two services. They are:
IAM (Identification and Authentication Management Tool)IAM is also referred to as an Identification and management tool. If we have an enterprise, users use our AWS account to control the AWS infrastructure, and we can provide them with granular permissions. Suppose we want a user to review what all instances are there, so we can give the user that access. If we want users to launch models and not delete them, we can provide that user with access, so these are the kind of accesses we can give using IAM, which is all about IAM. It authenticates us to our AWS account, or in this case, our employees do the route AWS account in the fashion we want. KMS (Key Management Service)AWS KMS is a Key Management Service. Any instance that we have launched in an AWS is based on this infrastructure that there will be a public key, and we will provide a private key and the public key with the AWS. Whenever we want to connect our instance, we must upload the private key or get the private key, and then AWS will master the private key with our public key, and if it matches, it will authenticate us to our AWS instances. So, we learnt that KMS assigns us the private key. We can create a new key pair or use an existing one, but we must be cautious with our private keys. If we lose our private keys, in any case, there is no way we can gain access back to our AWS resource, which will be using that private key. So, these are all about security services. Now, we will discuss the AWS application domain. AWS Application ServicesThe application domain includes three services: 1. SESSES is referred to as Simple Email Service. If we have a more extensive user base and want to send emails to them, we can do that with a push of a button using the SES. Also, if we wish for the replies to be automated, that can be done using SES, which is a straightforward service. 2. SQSSQS is called Simple Queue Service and is an exciting service that acts like a buffer. Suppose we had the image processing application, and whenever we uploaded an image and suppose we had to do five tasks. Now, these five tasks would list in our simple queue, and a server will keep a reference with this queue and see what all tasks are left to be done on the image. How does this help? It will help when we have multiple servers running for our processing. Suppose the first server does our first two operations, the other server might do the following three operations some another server might do the following three operations. So, the next server should know what all operations are already done, and this knowledge is referenced through our SQS. When a task is done, that task is removed from the queue, and the next task is queued, which is what SQS does. When we list those tasks, only those will be on priority. The first task we have listed will be executed first, based on priority, like first in, first out (FIFO). Suppose we have five images pending, so the second image is after the first image, and the third image is after the second image so that the first image will process according to the queue. Then the second image will process, and then the third image will process, so it works like this. 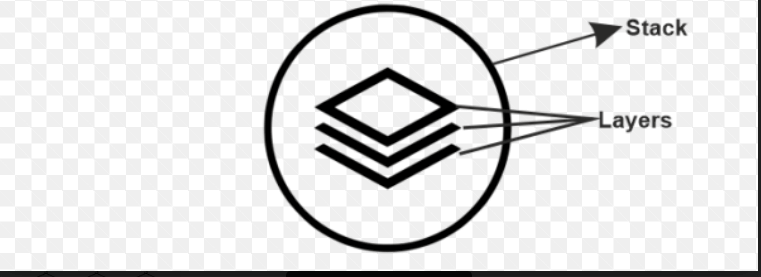
3. SNSSNS is called Simple Notification Service and sends a notification to other AWS services. It is used like, suppose we have an application that we discussed image processing, we upload the image, and now we want it to email whenever a photo is uploaded. SNS will notify SQS and SES that an image has been uploaded. When the notification is sent to SQS, that notification can also include the number of tasks to the task that has to be done on that image. So, SNS sends a piece of information to SQS with the details that must add to the queue. SNS can also notify SES that an image has been added, so send the respective email to the person. SNS sends a notification to different AWS services, which is what SNS is all about. Let us now discuss AWS pricing, like how we charge these services. AWS has two models:
Pay As You Go It means we can pay for what we use. Let us take an example to understand it better. Consider a file system here, so we do not have to force our requirement and buy 50GB junk for ourselves, even if we use only 10GB out of it. If we are using some other service and if we are not using AWS and they do not follow the "pay as you go" model. We must foresee what our requirement is. We must predict whether we might need 50GB in a month, but we end up using 10GB. But, with this, AWS is not the case; we pay according to our usage. So, if we are using S3 and we have only 6 or 7GB of data on it, we will be paying for that 6 or 7GB, and in future, if we upload more data onto it, we will be charged according to that data or that storage that we are using. So, this is what the "pay as we go" model is. Pay Less by Using More So, this is an exciting concept. Here we have included S3 for pricing. So, if we use S3 with up to 50GB of storage, we are charged at 0.023$Gb per month. If our usage goes beyond 50GB and it lies between 51-100TB of storage, our rate reduces to 0.022$GB per month. If we use 500TB and extra storage on S3, we will be charged 0.021$GB per month. So, as we are using more, our prices are dropping, and the rates are becoming less, and this is what "pay less by using more" means. Save when you reserveWhen we reserve any instances in AWS, we can book them for one year or a three-year term. So, if we have that kind of usage, we can reserve our instances and save costs up to 75%. With services like AWS EC2 and RDS, we can reserve our instances for a specific time frame. We are changed less sign up to 75% less. If we know that we will be using our instances for a minimum of 1 year or maybe three years down the line, we can reserve them and save up to 75% on that. Hosting a Website on AWSWe have to host a website on which we can upload images, which should display on the homepage. Once we have uploaded them, this website should also autoscale and be highly available. So, the above is our use case, and we have to host this application on the AWS infrastructure. Let us see how we will architect the various website we function. From the above use case, the user will point to a website address, and that website address will point to the website, and that website will be dealing with the files and that file server and a database. Why the File Server?Because we will be uploading our images on something, so, that's why the file server and we have to remember the parts of those images, and for that, we are using the database. So, the above is the architecture we will be constructing using AWS resources. Use Case Architecture Using AWS ServicesHere in this topic, let us see how we will architect the architecture discussed above using the AWS resources. The user had to point to a website address, which will point to a website. We will need a domain name system here so that we will be incorporating Route 53. The user will be interacting with Route 53, which will, in turn, point to a server. The server is the place where we are hosting a website. Our application or website is a PHP application; if we have an environment in Elastic Beanstalk, we should always go for it. Since PHP is listed in Elastic Beanstalk, we will use Elastic Beanstalk instead of EC2. Elastic Beanstalk will have EC2 instances under the hood, which are automated to have the PHP environment automatically configured on our EC2 models. Our EC2 instances will control this using the Auto Scaling and load balancer. Whenever there is a requirement for more cases, more EC2 models will launch, and the traffic will be distributed accordingly using the Elastic load balancer, so this is how it functions under the hood. Still, we do not have to worry about that. We can also consider Elastic Beanstalk as a black box. Now, our website has to interact with RDS and S3. We use RDS and S3 because S3 is a file system discussed in the architecture above, and RDS is the database we are trying to connect with. We have to store the paths to the file we are uploading; those paths can be kept structured. Since it is structured data, we will use RDS, Relational Database Management Service, to store our data in a supposed MySQL database. That is why we are using the RDS service. If we are connecting a third-party application to our S3 file system, we need to authenticate that application to S3, and for that, we would need to access keys, and IAM provides those access keys.
Next TopicAWS Polly in Java
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








