| |

Boyer Moore JavaBoyer-Moore algorithm is a string searching or matching algorithm developed by Robert S. Boyer and J Strother Moore in 1977. It is a widely used and the most efficient string-matching algorithm. It is much faster than the brute-force algorithm. In this section, we will discuss the Boyer-Moore algorithm, features, and its implementation in a Java program. It runs in time O(nm+s) complexity. The worst-case is: T=ssssssss……………ssssssss P=psssssssss The above sequence may occur in images and DNA sequences. Features of Boyer Moore Algorithm
The algorithm is based on the following two heuristics:
Let's understand the working of the Byer-Moore algorithm. Working of Boyer-Moore AlgorithmThe algorithm starts tracing characters from the rightmost character of the given pattern and moves towards the left. In case of any mismatch and complete matching of the pattern, it uses two pre-computed functions that shift the characters to the right and left, respectively. These two precomputed shift functions are called the good-suffix shift (or matching shift) and the bad-character shift (or occurrence shift). Note: For matching the pattern, align characters in left to right order and compare characters in right to left order.Bad Character ShiftWhen a mismatch occurs, skip alignment until one of the following conditions does not meet:
For example, consider the following text (T) and pattern (P) given below. 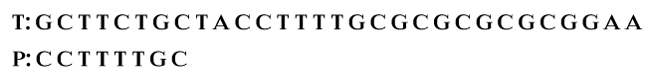
Let's start matching the pattern. Step 1: Align characters in left to right fashion and compare characters in right to left order. We see that the last three characters of P matched with the characters in T. The fourth character (T) does not match. According to the rule discussed above, skip alignment until a mismatch becomes a match. Since the seventh character (C) in P matched with C in T. 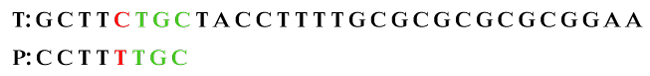
Step 2: Skip three characters to the right to matching the pattern. After shifting, again compare the characters from right to left. The first character is matched. We observe that the character A does not occur in the left of P. In this case, P moves to the past mismatch character (A) in T. 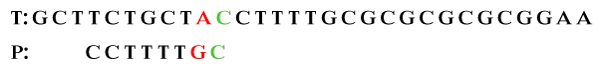
Step 3: Move P past mismatch character, we get: 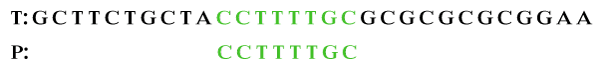
The pattern is matched. Note: The bad-character shift can be negative. Since for shifting the characters, the Boyer-Moore algorithm applies the maximum (skip characters) between the good-suffix shift and bad-character shift.Good-Suffix ShiftLet, t substring matched by inner loop, then skip characters until:
For example, consider the following pattern. 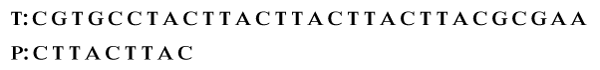
Step 1: Compare characters from right to left. We see that the last three characters of P matched with characters in T denoted with t. 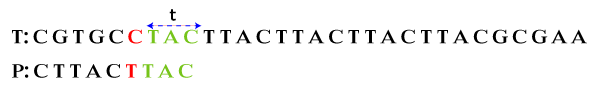
Step 2: Skip characters until there is no match between P and t. We observe that the first four characters (from left to right) of P (C T T A C) match with the last five characters in t. 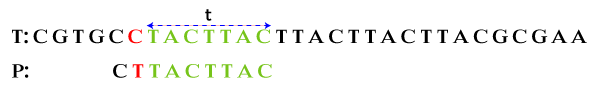
Step 3: Skip three alignments to get the match. Therefore, we get the match. 
The above two-shift functions can be defined as follows: The good-suffix shift function is stored in a table called bmGs of size m+1. The computation of the table bmGs use a table suff defined as follows: The bad-character shift function is stored in a table bmBc of size σ. For c in ∑: Boyer Moore Pattern Matching ExampleConsider the following pattern. 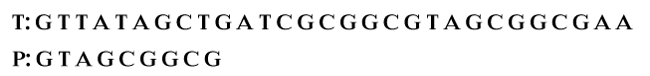
Let's start matching. Step 1: Compare characters from right to left. We see that the first character is mismatched i.e. G does not match with T. 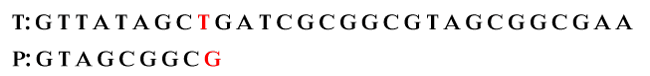
Step 2: Now, skip the characters until we found a match. A match is found after six characters. Here, the good suffix shift rule will not apply. 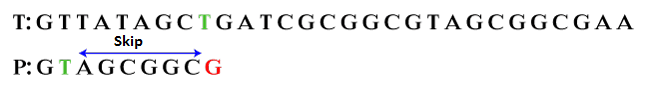
bc: 6, gs: 0 According to bad character shift, P moves past mismatch character (i.e. G). 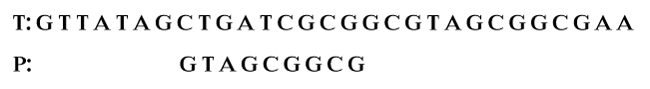
Step 3: Again, compare characters from right to left. We see that the first three characters of P matched (t) with T and the fourth one is not matched. 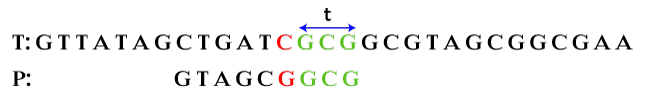
Here, we can apply both functions i.e. bad character suffix and good character suffix. If we apply the bad character suffix, it skips only one character. If we apply the good character suffix, it skips two alignments. Therefore, we will apply the good character suffix because the algorithm states, skip more alignments. Hence, we skip two alignments. 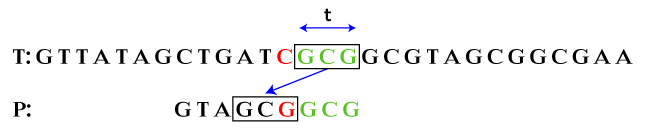
bc: 0, gs: 2 After shifting alignment by three characters, we get: 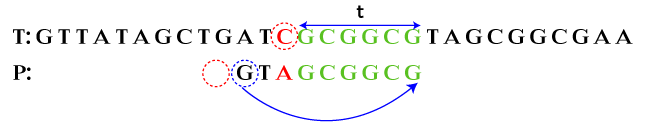
bc: 2, gs: 7 Here, we observe that C does not appears in the left of P. Therefore, bad character alignment skips two alignments and the good character alignments skips the seven alignments. Step 4: After shifting characters, we see that the string is matched. 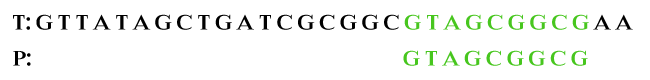
In the above pattern, we have skipped 15 alignments and 11 characters of T were ignored. Boyer Moore Preprocessing PhasesPre-calculated skips for the pattern T: A A T C A A T A G C and P: T C G C can be defined as follows. In the above pattern, we have used the bad character shift function. 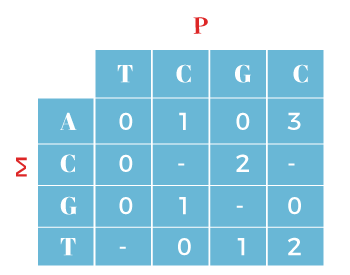
Above table defines the number of skip alignments (characters). Boyer Moore Algorithm Pseudo CodePattern Searching Java ProgramLet's see the pattern searching Java program. In the following program, we have implemented the brute-force string searching algorithm. PatternSearchingExample.java Output: Brute force looking for abddef in abcfefabddef Found match in the given text at index 6 Boyer-Moore looking for abddef in abcfefabddef Found match in the given text at index 6 Let's implement the algorithm in a Java program. Boyer Moore Java ProgramLet's implement the Boyer-Moore algorithm and search pattern through a Java program. BoyerMooreImplementation.java Output: Patterns occur at character = 0 Patterns occur at character = 5 Patterns occur at character = 10 Let's see another Java program in which we have implemented different logic for pattern searching. The following program checks if the specified pattern found in the text. BoyerMooreExample.java Output: Pattern Not Matched text: aabbccdef word: cde exp: 0, res: 5 Pattern Not Matched text: zzzzaaapppxyzabc word: pqrs exp: 1, res: -1 Pattern Matched Pattern Matched Pattern Matched Pattern Not Matched text: pqrsabcdxyzamnop word: cdxyza exp: 1, res: 6 Pattern Matched Pattern Matched
Next TopicJava Security Framework
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








