| |

Teradata Primary IndexThe primary index is used to specify where the data resides in Teradata. It is used to determine which AMP gets the data row. In Teradata, each table is required to have a primary index defined. If the primary index is not defined, Teradata automatically assigns the primary index. The primary index provides the fastest way to access the data. A primary may have a maximum of 64 columns. The primary index is defined while creating a table, and it cannot be altered or modified. The primary index is the most preferred and essential index for:
Rules for Primary IndexHere are some specific rules for the Primary index, such as: Rule 1: One Primary index per table. Rule 2: A Primary index value can unique or non-unique. Rule 3: The Primary index value can be NULL. Rule 4: The Primary index of a populated table cannot be modified. Rule 5: the Primary index value can be modified. Rule 6: A Primary index has a limit of 64 columns. Types of Primary IndexThere are two types of Primary Indexes.
1. Unique Primary Index (UPI)In the Unique Primary Index table, the column should not have any duplicate values. If any duplicate values are inserted, they will be rejected. The Unique Primary index enforces uniqueness for a column. A Unique Primary Index (UPI) will always spread the rows of the table evenly amongst the AMPs. UPI access is always a one-AMP operation. How to create a Unique Primary Index? In the following example, we create the Student table with columns Roll_no, First_name, and Last_name.
We have selected Roll_no to be our Primary Index. Because we have designated Roll_no as a Unique Primary Index, there can be no duplicates of student roll numbers in the table. 2. Non-Unique Primary Index (NUPI)A Non-Unique Primary Index (NUPI) means that the values for the selected column can be non-unique. A Non-Unique Primary Index will never spread the table rows evenly. An All-AMP operation will take longer if the data is unevenly distributed. We might pick a NUPI over a UPI because the NUPI column may be more useful for query access and joins. How to Create a Non-Unique Primary Index? In the following example, we create the employee table with columns Employee_Id, Name, Department, and City.
Every employee has a different employee Id, name, and department, but many employees belong to the same city in this table. Therefore we have selected City to be our Non-Unique Primary Index. Multi-Column Primary IndexesTeradata allows more than one column to be designated as the Primary Index. It is still only one Primary Index, but it is merely made up of combining multiple columns. Teradata Multi-column Primary index allows up to 64 combined columns to make up the one Primary Index required for a table. Example In the following example, we have designated First_Name, and Last_Name combined to make up the Primary Index. This is very useful and beneficial for two reasons:
Data distribution using Primary IndexWhen a user submits an SQL request against a table using a Primary Index, the request becomes a one-AMP operation, which is the most direct and efficient way for the system to find a row. The process is explained below. The complete process is explained in the below image: 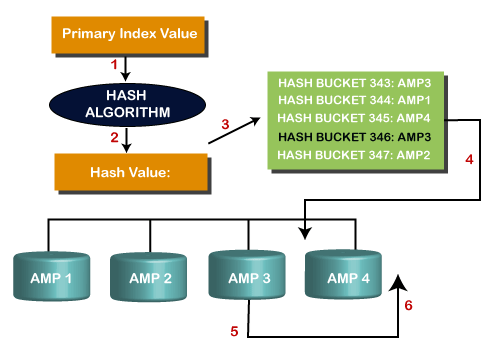
Hashing ProcessThe process of Hashing is defined in the following steps, such as: Step 1: In the first step, the Primary index value goes into the hashing algorithm. Step 2: The output of the hashing algorithm is the row hash value. Step 3: The hash map points to the specific AMP where the row resides. Step 4: The PE sends the request directly to the identified AMP. Step 5: The AMP locates the row(s) on its vdisk. Step 6: The data is sent to PE through BYNET, and PE sends the answer set to the client application. Duplicate Row Hash ValuesThe hashing algorithm can end up with the same row hash value for two different rows. We can do this in two ways, such as:
To differentiate each row in a table, every row is assigned a unique Row ID. The Row ID is the combination of the row hash value and unique value.
Row ID = Row Hash Value + Uniqueness Value
The uniqueness value is used to differentiate between rows whose Primary Index values generate identical row hash values. In most cases, only the row hash value portion of the Row ID is needed to locate the row. 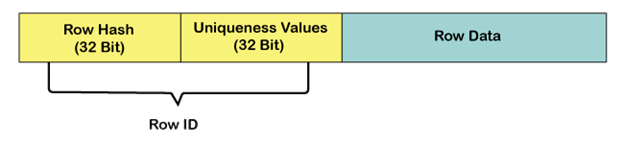
When each row is inserted, the AMP adds the row ID, stored as a prefix of the row. The first row inserted with a particular row hash value is assigned a unique value of the unique value is incremented by 1 for any additional rows inserted with the same row hash value.
Next TopicTeradata Joins
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








