| |

Bucketing in HiveThe bucketing in Hive is a data organizing technique. It is similar to partitioning in Hive with an added functionality that it divides large datasets into more manageable parts known as buckets. So, we can use bucketing in Hive when the implementation of partitioning becomes difficult. However, we can also divide partitions further in buckets. Working of Bucketing in Hive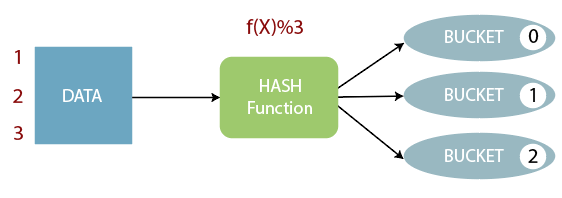
Example of Bucketing in Hive

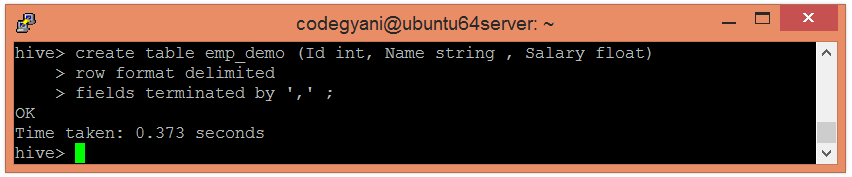
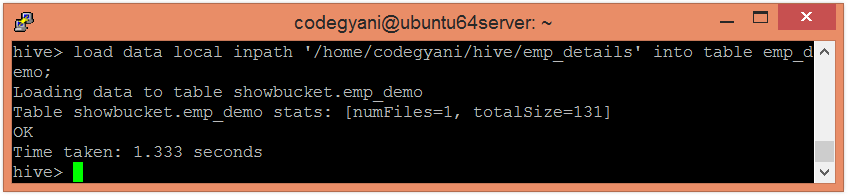
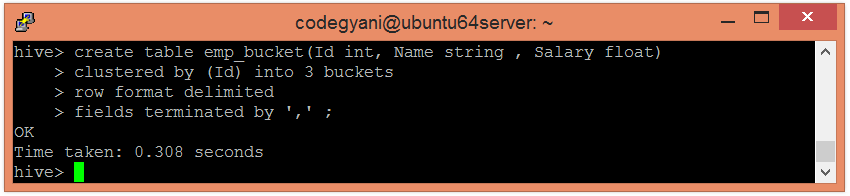
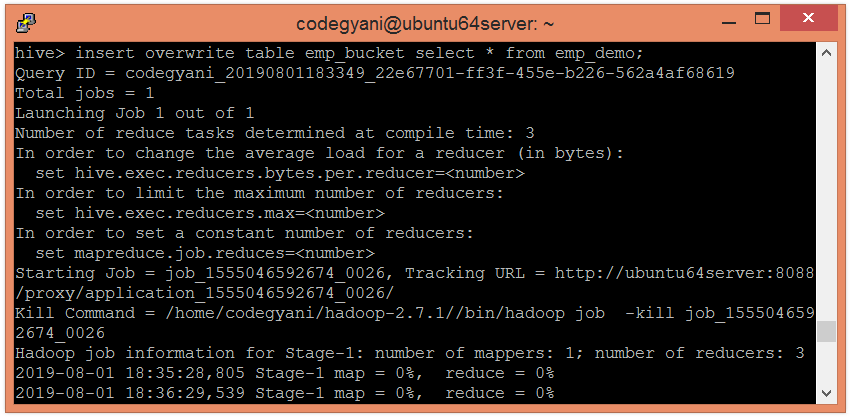
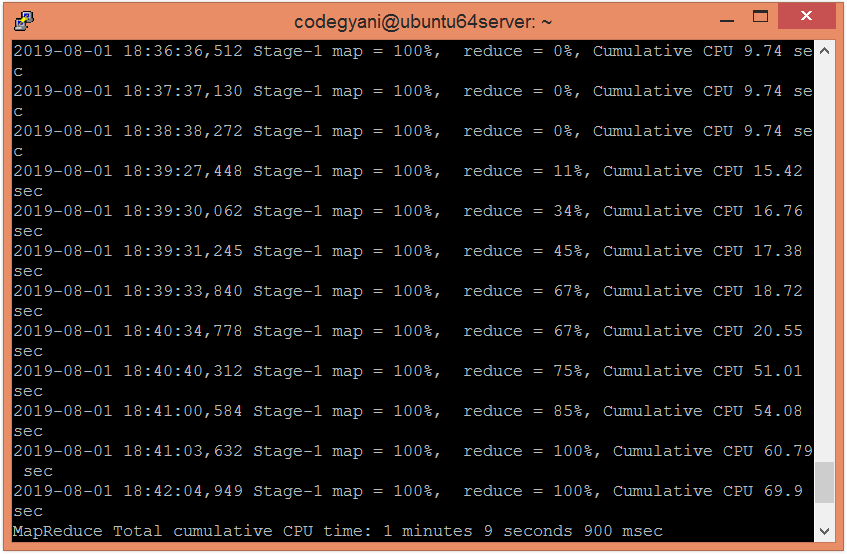
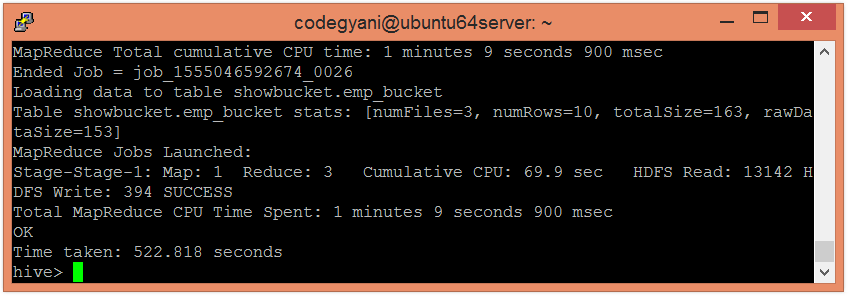
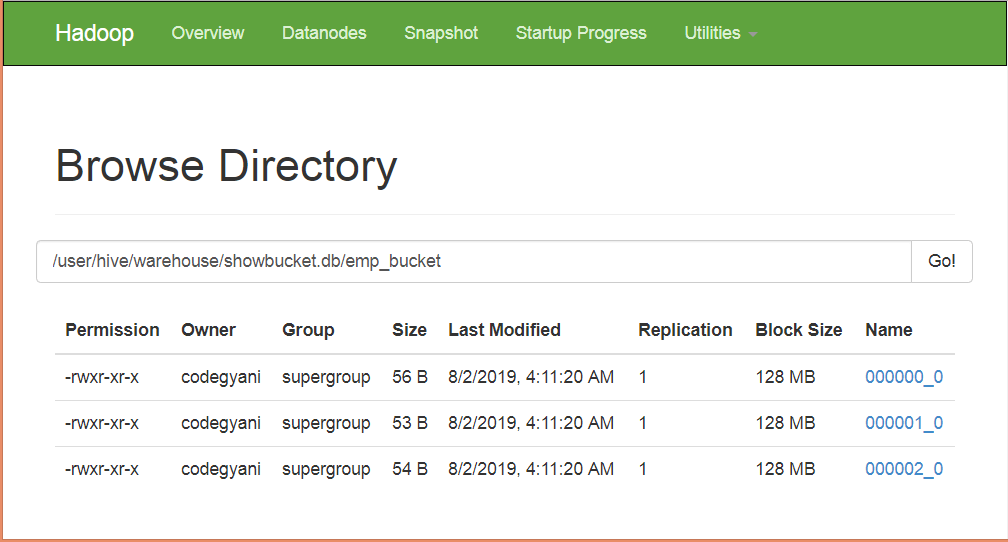
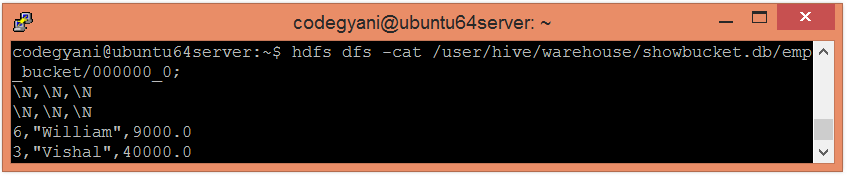
According to hash function :

According to hash function :

According to hash function :
Next TopicHiveQL - Operators
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share



Like/Subscribe us for latest updates or newsletter 




