| |

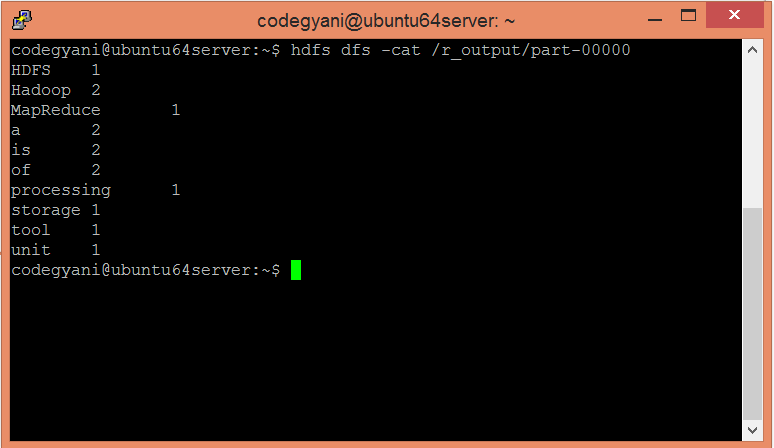
MapReduce Word Count ExampleIn MapReduce word count example, we find out the frequency of each word. Here, the role of Mapper is to map the keys to the existing values and the role of Reducer is to aggregate the keys of common values. So, everything is represented in the form of Key-value pair. Pre-requisite
If any of them is not installed in your system, follow the below link to install it. www.javatpoint.com/hadoop-installation Steps to execute MapReduce word count example
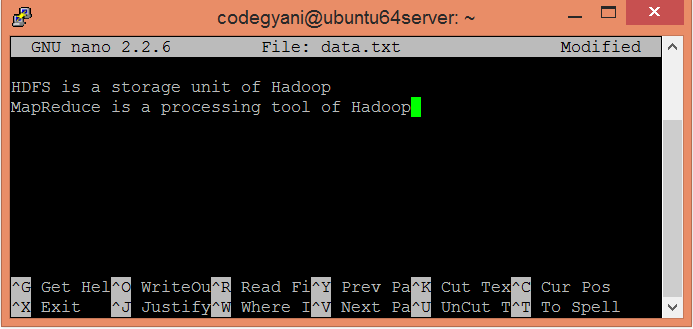
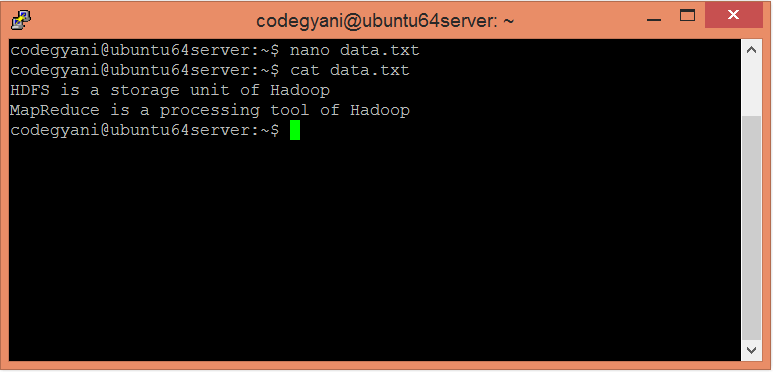
In this example, we find out the frequency of each word exists in this text file.
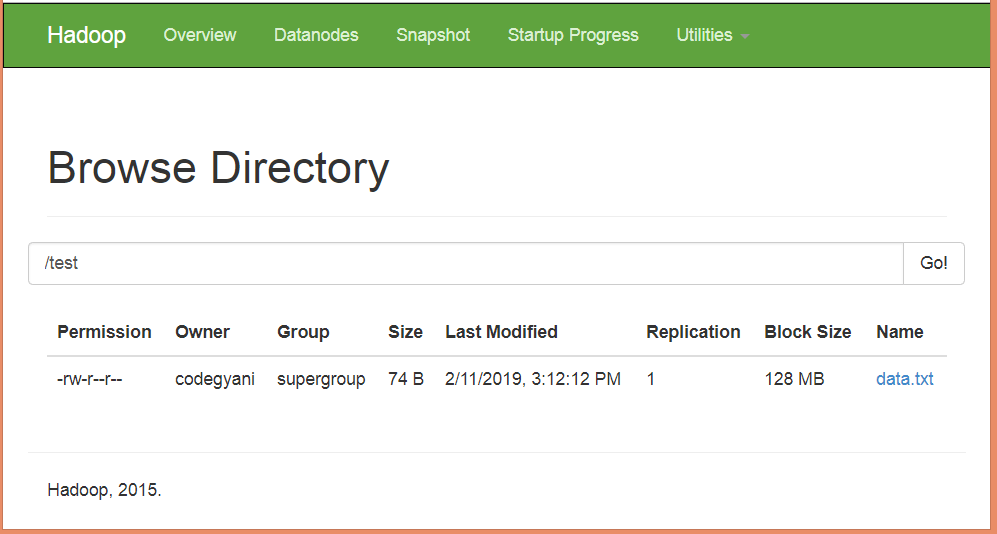
File: WC_Mapper.javaFile: WC_Reducer.javaFile: WC_Runner.javaDownload the source code.
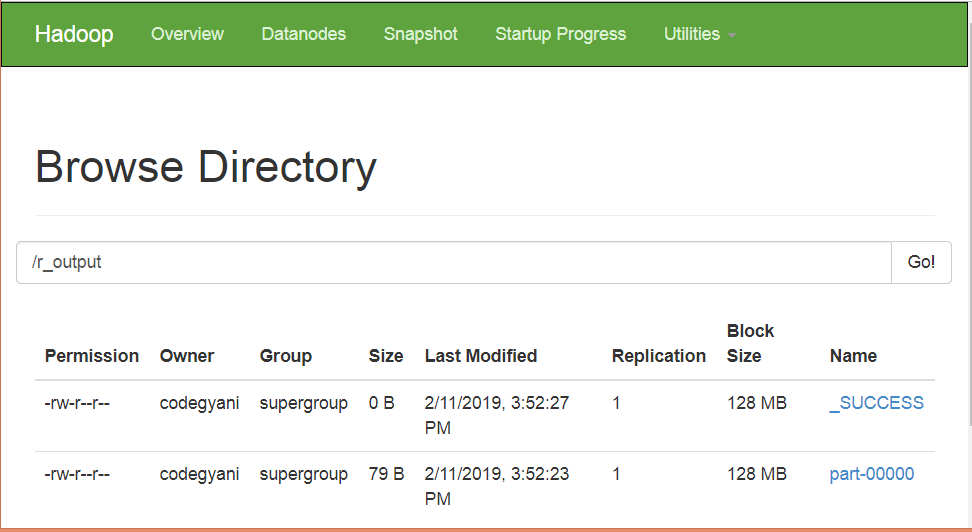
Next TopicChar Count Example
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share



Like/Subscribe us for latest updates or newsletter 




