| |

Elasticsearch AnalysisAnalysis is a process of converting the text into tokens or terms, e.g., converting the body of any email. These are added to inverted index for further searching. So, whenever a query is processed during a search operation, the analysis module analyses the available data in any index. This analysis module includes analyzer, tokenizer, charfilter, and tokenfilter. For example - Sentence: "A quick white cat jumped over the brown dog." Tokens: [quick, white, cat, jump, brown, dog] Analysis is performed by an analyzer. It can be either a built-in analyzer or a custom analyzer. Custom analyzers are defined according to the index. If the analyzer is not defined, then by default built-in analyzers, filters, token, and tokenizers get registered with the analysis module. Analysis is performed with the help of -
We will discuss each of them in detail. Before this, start with a simple example. Example -Let's take a simple example in which we will use standard analyzer to analyze the text and convert them into tokens. It is a default analyzer used when nothing is specified. It will analyze the sentences and break them into tokens (words) based on the grammar. Copy Code Response Configure the Standard analyzerStandard analyzer can be configured according to our requirement. We can also configure other analyzers to fulfill our custom requirements. With the help of an example, understand it much better.
Copy Code Response Analysing text after configuring standard analyzerAfter creating an index with a modified analyzer, now we will apply the analyzer with text. In the following example, you must have to provide the index name (analysis_example) in query string and analyzer in request body along with text string. Do not forget to provide _analyze API. Copy Code You note that elasticsearch and tutorial have 13 and 8 characters respectively, in the text string. Thereby, they will also be further broken according to the maximum token length specified in the previous query. Response Different types of AnalyzersThese are several analyzers, each having different functionality. They help to achieve different objectives as needed. Below is a list of built-in analyzers with their descriptions -
Example of Keyword tokenizerAs we discussed, the keyword analyzer treats the whole stream as a single token. Look at the below example of keyword analyzer. For this, we do not require any index. We just need to specify the analyzer type in the analyzer field and text string in the text field. Do not forget to pass _analyze API in API column. Copy Code Response Screenshot 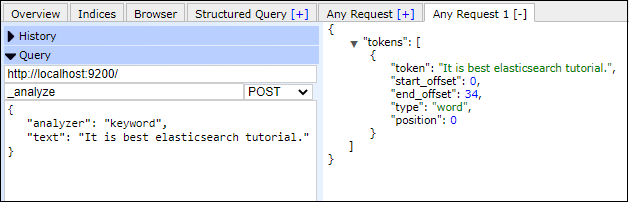
TokenizersIn elasticsearch, tokenizers are used to generate tokens from the text. Tokenizer helps to break down the text into tokens by putting whitespace or other punctuation symbols. Elasticsearch provides built-in tokenizers, which can be used in custom analyzers. Below is a table of tokenizers with their description -
Now, let's take an example of tokenizer that how it works in elasticsearch. In the following example, tokenizer will break the text into tokens whenever a non-letter character is found. It also converts all tokens into lowercase. See the example below - Lowercase Tokenizer ExampleCopy Code Response Note that - in the above response, all the uppercase letters converted into lowercase and elasticsearch did not print the numeric (non-letter) value, i.e., 2. But it keeps the space for it like one for before the non-letter and one for end of that non-letter character and one for itself.Screenshot 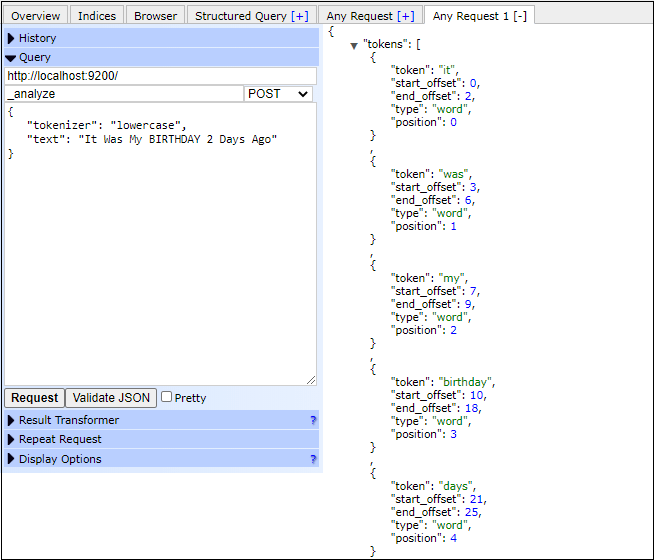
Classic Tokenizer ExampleIn this example, we will pass the _analyze API in API section and specify the tokenizer name in a "tokenizer" variable. At last, we need to provide a text string to break the text into tokens. Copy Code Response In the response below, you can see that the text stream is divided into tokens and the type is alphanumeric, which means both alphabetic and numeric value will be displayed. Like the lowercase tokenizer, tokens are not converted to lowercase here, and the numeric value is also displayed in response. Screenshot 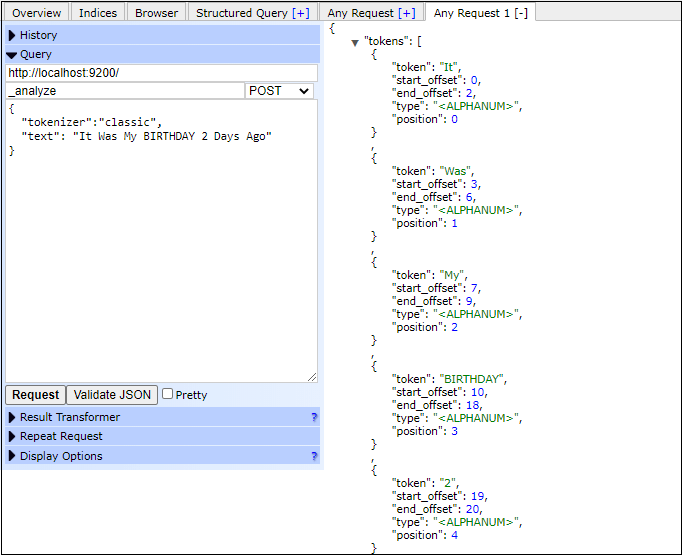
Similarly, we can get the result for another tokenizer by just passing their name in tokenizer field and text in a text string. Token Filters
Character Filters
Next TopicElasticsearch Mapping
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








