| |

Elasticsearch PaginationBefore starting with pagination in Elasticsearch and knowing how to do it, it is important to know what is pagination. So, let's first start with pagination. Each time when we search something on the web, it returns a lot of results. These results can be in hundreds or thousands or sometimes in lakhs, which are distributed on several pages. Each page has multiple records. This mechanism is known as pagination. Pagination helps to make easy for the users to find necessary information efficiently. Usually, each page consists of 10 records, but it's not a limitation. You can set the number of records that you want to be displayed per page. The below diagram shows how pagination looks like so that you can understand it well. 
Pagination is a sequence of pages having similar content. It also refers to as paging, which helps the users move directly to any page. Therefore, they do not need to scroll down the page for too long. It saves the precious time of users. Most of the time, paging is placed at the bottom of the page. However, we can also place it anywhere we want, like - top of the page. Note that we can use paging with scrolling. Pagination in ElasticsearchElasticsearch allows users to perform pagination. It is easy and simple to do. In Elasticsearch, there are two properties from and size, which help to perform pagination very efficiently. These parameters are as follow: From - This property is used to specify the initial point for each page to start searching the record in the index. Means it specifies from which record in an index, Elasticsearch should start searching. In this, you can define the number of items to be skipped from the start. Size - This property is used to specify the number of records per page to be searched. This means how much results will return is set in this property. Therefore, with the help of pagination, we are able to pick up a specific number of records to be returned to the users. How to perform pagination in ElasticsearchIn Elasticsearch, we can perform pagination with the help of from and size properties, as discussed above. This will help you to fetch a specific number of results from an index and return them to the users. However, these from and size parameters work for only for 10k search results. Let's take a query example to do pagination in Elasticsearch - Here reasoning is the name of the index, and _search is Elasticsearch API. According to this query, it will return the 15 records from the reasoning index. It is obvious that each technology has some drawbacks along with benefits. Elasticsearch pagination also has a small issue. When a search request is performed on an Elasticsearch index and if we get a list of more than 10000 results. The from + size index cannot be greater than the index.max - result - window. Its default value is set to 10000 while index creation. We have solutions for it, you can either use scroll API or search_after parameter to deal with this problem. If you need to go forward, use search_after. On the other hand, if you need to dump the entire index that contains more than 10 thousand documents, use scroll API. We will discuss both solutions in detail: How to resolve if have a list of more than 10000 items?Elasticsearch has solutions in case if you have a list of more than 10k items, which are as follows - 1. Scroll API of ElasticsearchElasticsearch offers scroll API to its users to deal with such type of problems. We can use scroll API if the request is large and latency is not so important. This means that if there is no issue of time and the request is also large, scroll API is useful. The scroll API is recommended for deep scrolling. However, there is a lot of warning given by the web due to this solution. Despite this, we have implemented this solution. It is expected to be very slow and may take around 10 minutes to execute. In addition, it is an expensive solution as well because Elasticsearch kept the state between each iteration. Therefore, it is not a best solution for real-time user requests. In summary, it is not acceptable for real-time requests and the scroll context is also costly. See the example below: Example We have to send an initial request to start scrolling. Usually, this request starts a search context on the server. In this query request, you need to specify the scroll time in scroll parameter (i.e., scroll=TTL), which means how long it stays alive. This query request will keep the context alive for 2 minutes. 2. Use search_after parameterWith the help of from and size parameters, we can perform pagination cost-effectively. But when the deep pagination is reached, the cost raises too much. The scroll API is good for large requests, but there is no time limitation to respond. So, it is not suitable for real-time user requests. Elasticsearch offers a search_after parameter, which is suitable for real-time use requests. The search_after parameter provides a live cursor. It is not used to jump to a random page, it helps to scroll several queries in parallel. Note that the search requests take heap memory and time equivalent to from + size. See the below example: 3. Increase the value of index.max_result_windowBasically, this value (index.max_result_window) helps to preserve the Elasticsearch cluster memory from large queries. By increasing this value, cluster latency can crash. Elasticsearch does not allow the users to paginate beyond the index.max_result_window setting. It is not a limitation but a safeguard against deep pagination. By default, its value is 10000. Therefore, from + size should be less than this value. 4. Limit lists to 10k articleIn case there is a need to pagination on more than 10k results, this request may not be precise enough. Because it is not good to paginate over 10k results. Elasticsearch is just not a search engine. Some articles have to display the entire history for SEO purposes, which are above 10k articles. Implemented solutionLet's understand with the help of a flowchart in which are describing two solutions here -
See the below flowchart: 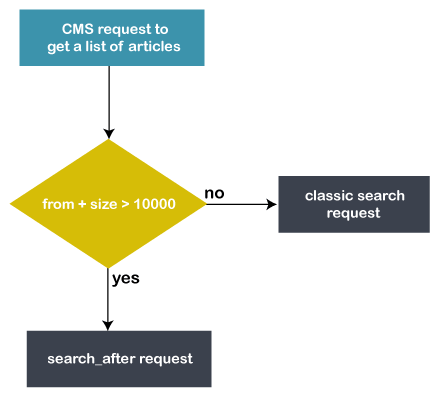
The pages within the first 10k items are fresh because they are calculated on demand. While other pages are not as fresh as expected. These pages are static and pre-calculated but acceptable for SEO purposes. A query request is executed for this.
Next TopicElasticsearch Snapshot
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








