| |

Data Organization in FirestoreCloud Firestore is a NoSQL, document-oriented database. There are no tables or rows, and data is stored in the documents, which are organized into collections. Each document contains a set of key-value pairs to identify a document. These key-value pairs are optimized for storing a large collection of small documents. 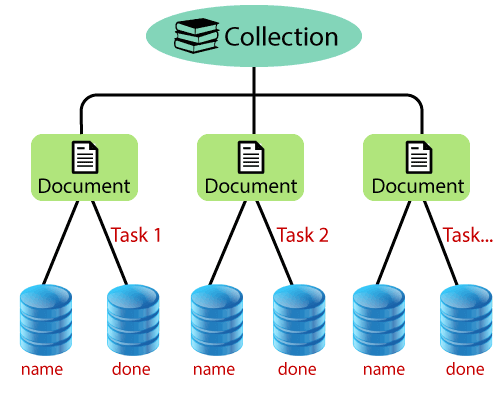
All the documents must be stored in collections. Documents can contain sub-collections and nested objects, which can include primitive fields like string or complex objects like lists. A document is a light weighted record that contains a field, which maps to values. A name identifies each document, and we can treat documents as lightweight JSON records. Complex, nested objects in a document are known as maps. CollectionsDocuments reside in collections, which are very simple containers for documents. Collections are schema-less. We have freedom over the fields which we put in each document and data types that we store in those fields. Documents that are in the same collection can contain and store different fields and different types of data in those fields.
Sub-collectionsA sub-collection is a collection associated with a specific document. We can create a sub-collection called messages for every room document in our rooms collection. When we structure our data in Cloud Firestore, we have the following options
We can nest complex objects like arrays or maps within documents. It is easy to set up and streamline our data structure if we have a simple, fixed list of data. The document grows, with larger or growing lists that can lead to slower document retrieval times. So it is not scalable as another option. We can create collections within the document when we have data that might expand over time. As our list grows, the size of the parent document doesn't change and also get full query capabilities on sub-collections. There is one drawback or limitation of sub-collections, i.e., we cannot easily delete sub-collections. ExampleRoot-level collectionsIn the root-level collection, we create collections at the root level of our database to organize disparate dataset. Example
ExampleCreating a reference to a message in the sub-collection
Next TopicRead and Write in Firestore
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








