| |

Indexing and Selecting a Pandas DataFramePandas is one of the most prominent libraries in Python for Data Analysis applications. First, a DataFrame in Pandas is like a table or a two-dimensional array with rows and columns. It is a mutable and heterogeneous data structure. We refer to rows and columns as axes. A lot of functions are available in Pandas to manipulate DataFrames for analysis. We can create a DataFrame in several ways but the function used is: To use this function or any function in the library, first, we have to import the library using the following: For this tutorial, we created a table in an excel sheet, "painters.xlsx," with information about the 20 greatest painters in the world. 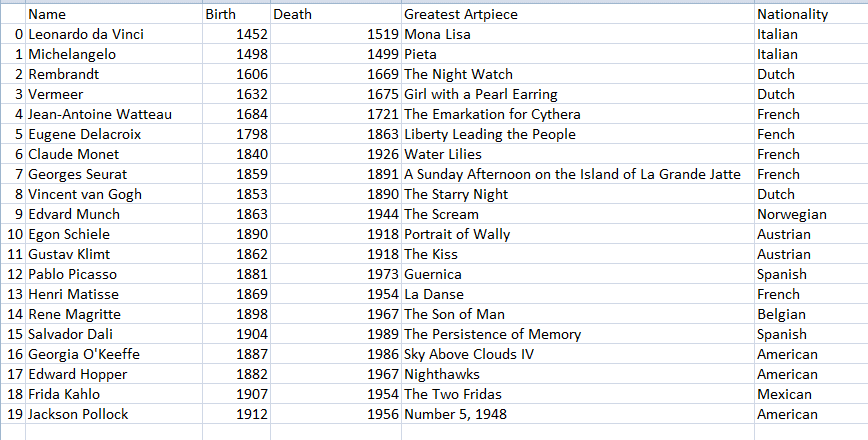
Now, here is a Python code to create this table into a pandas DataFrame: Output: 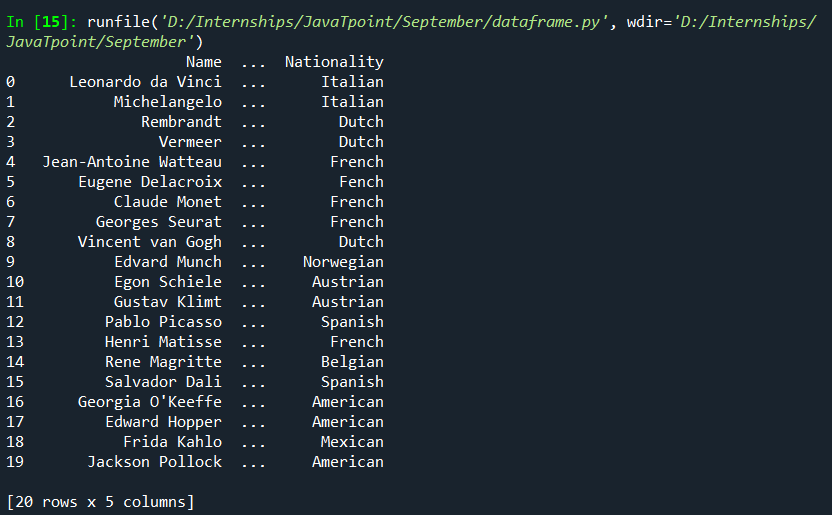
The title of the tutorial is "Indexing and Selecting a DataFrame". Like we slice a string using indexes from 0 to length - 1, we can also access, copy and create new DataFrames from an existing DataFrame. This tutorial explains all these ways.
1. [] and .[] is called the Index operator, and . is called the Attribute operator in Pandas. These operators are used for basic form of Indexing and viewing different subsets of a DataFrame. Using the Attribute operator(.): Selecting columns:
In our Painters table: Output: 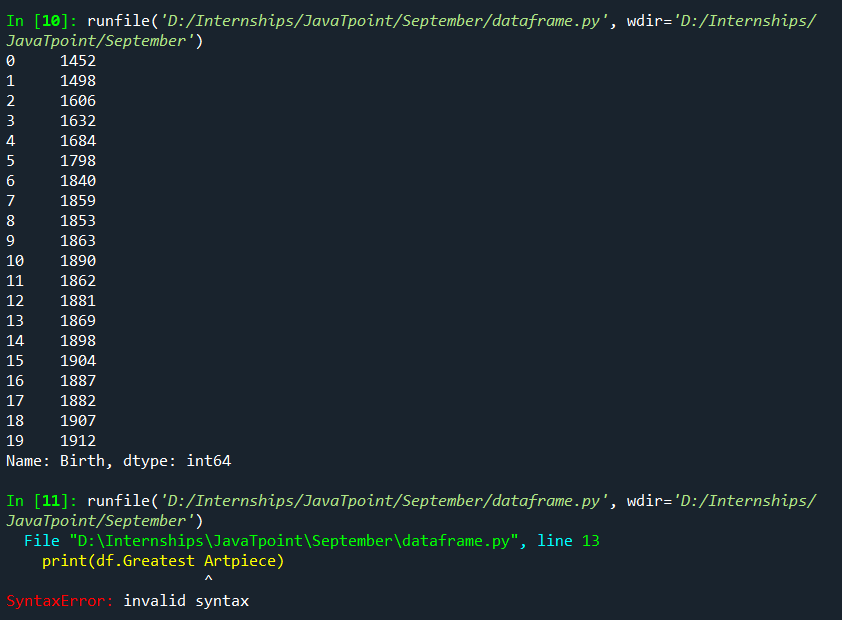
Observe that a syntax error is raised when we try to access the column "Greatest Artpiece" because of the space. If we want to access the attribute, we can use the getattr(DataFrame, column_name) function. Output: 
Using the Index operator:Selecting columns: We need to pass the name of the column to the operator, but here there is no restriction for any spaces in the column names: Note that the name of the column has to be passed in quotes. Output: 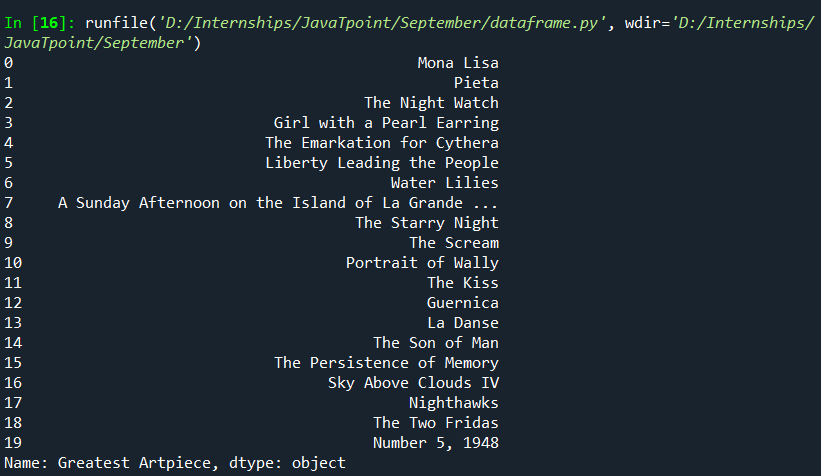
Output: 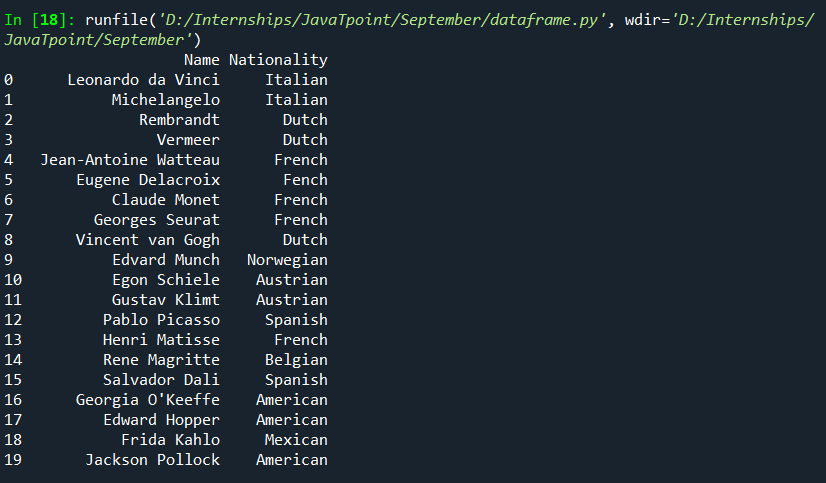
Selecting Rows: Using the slicing operator, we can select rows of the DataFrame using the same index operator. The syntax for slicing is the same as for any other iterable object: start: Starting index/row_position(inclusive) stop: Position to stop slicing(exclusive) step: The interval between selecting rows Output: 
We can also use row labels if we use them while creating. Here is an example: Output: 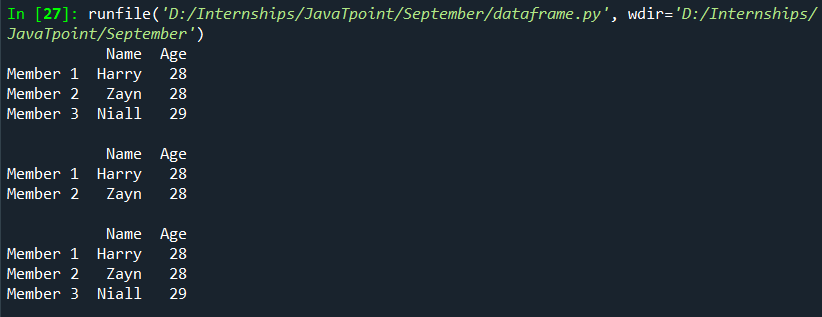
Here are the points to conclude about the index operator:
So far, we couldn't select both rows and columns of a DataFrame simultaneously. There are two functions in Pandas specially built for selecting and sub-setting DataFrames. These functions have clear functionality. We'll learn about them now. 2. DataFrame.ilocSyntax: Both rows and columns must be positions and not labels, and these positions can be given as follows:
Here is the table we'll be modifying: 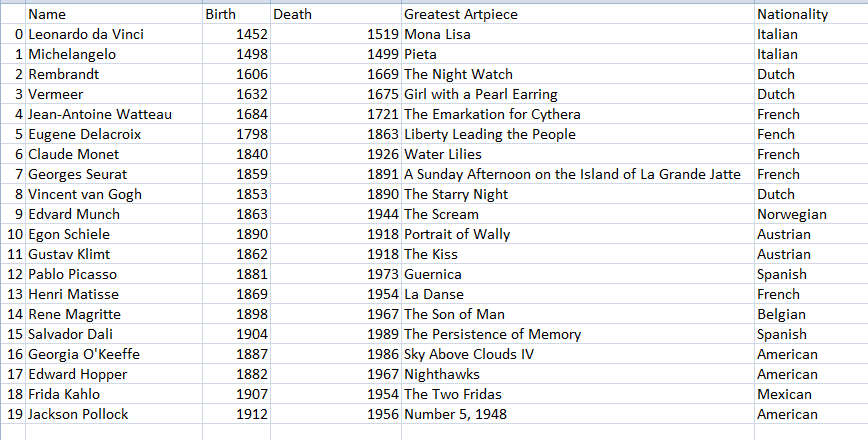
Note that the 0th row and 0th column are referred to as the 1st row and 1st column.
Syntax: Code: Output: 
Syntax: Code: Output: 
Syntax: Code: Output: 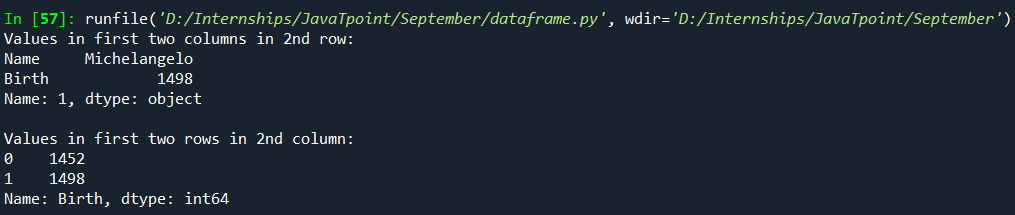
Syntax: Code: Output: 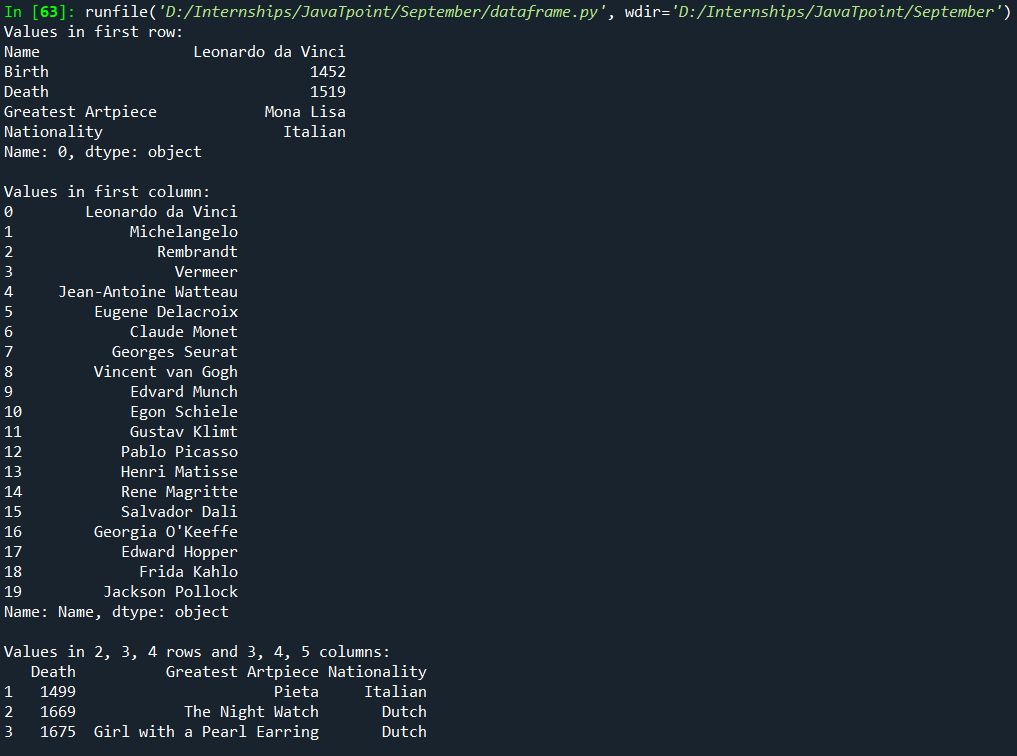

3. DataFrame.loc[rows, columns]As we saw above, iloc[] works on positions, not labels. loc[], on the contrary, works on labels, not positions. All the other functionality is the same. Both rows and columns must be labels, and these labels can be given as follows:
Note: While using the slice operator on the row or column labels, the end label will be inclusive along with the starting label like when we sliced using the index operator-[]Here is the table we'll be modifying: 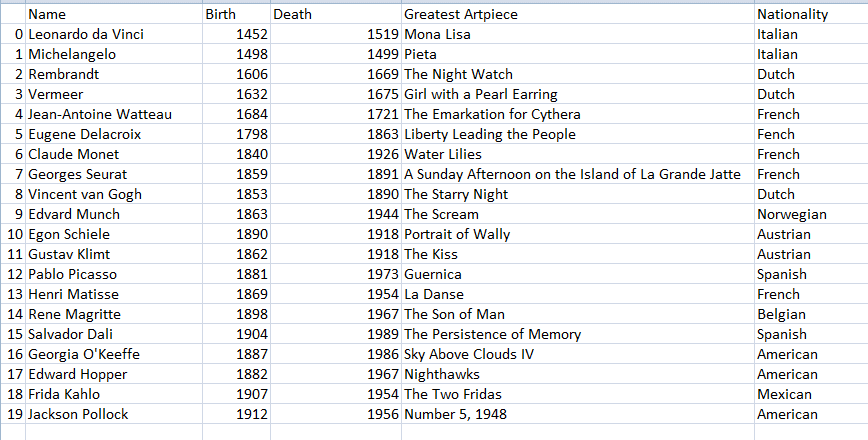
Syntax: Code: Output: 
Syntax: Code: Output: 
Syntax: Code: Output: 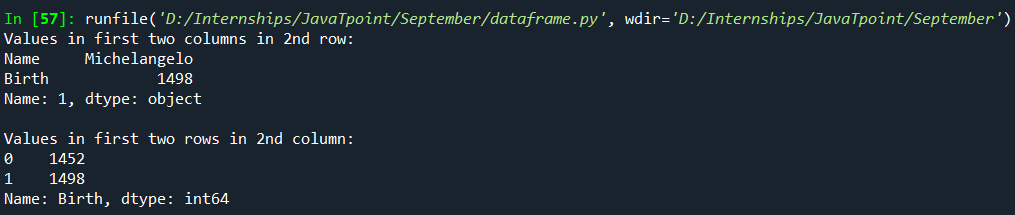
Syntax: Code: Output: 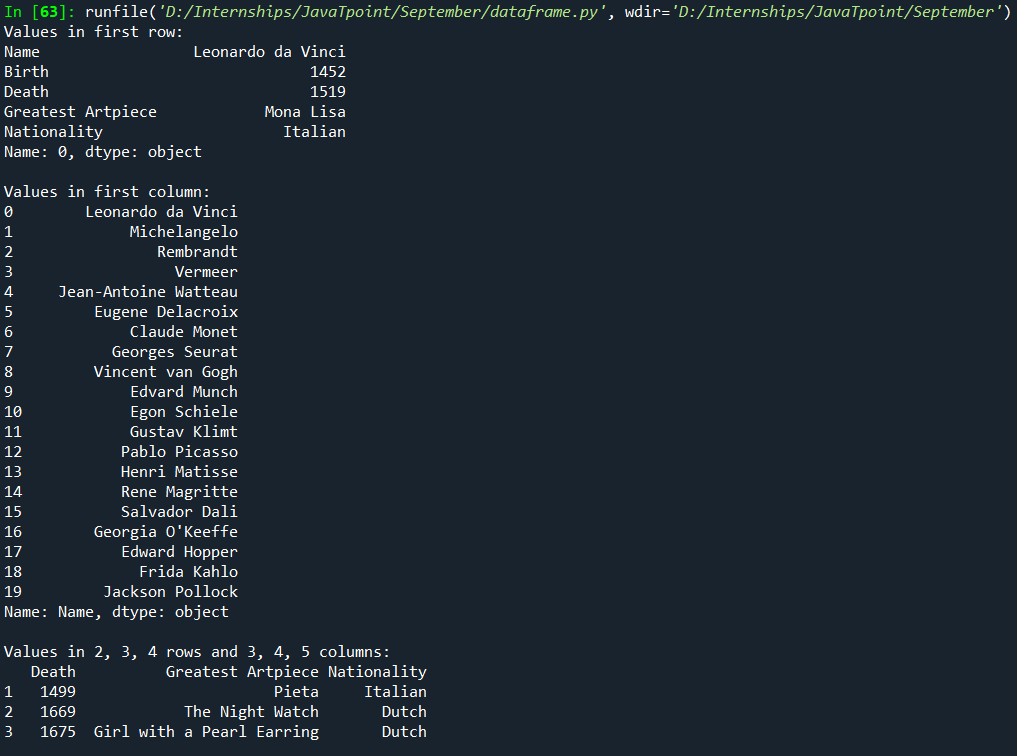

Observe that when we gave: Rows: 1st, 2nd, and 3rd rows Columns: "Death", "Greatest Artpiece," and "Nationality" are printed, which means the last row and column are also included. With conditions: Until now, we selected data from DataFrame using either position numbers or labels. We can also select data based on conditions we need using two ways used-loc[] and index operators: Here are some important points to carry on: 1. We can use any Boolean operator, but here, we must use: 2. We can use any number of conditions, but every condition must be enclosed using parentheses. Output: 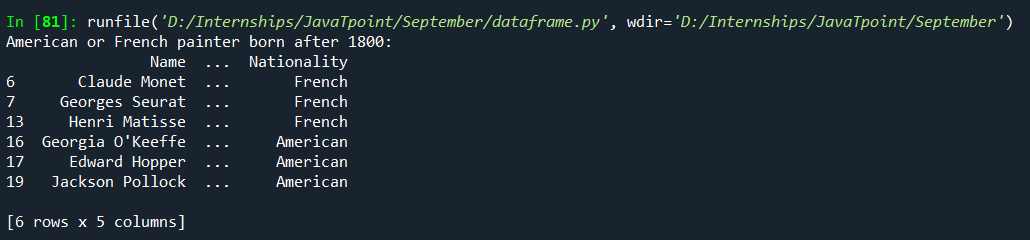
3. For suppose we want to print all the painters born after 1800. We need to check the column Birth: df["Birth"]>1800 This is the condition. We'll get that column with True and False if we print it after checking the condition. Now, if we want to print the rows, we need to pass the condition to df[]: Output: 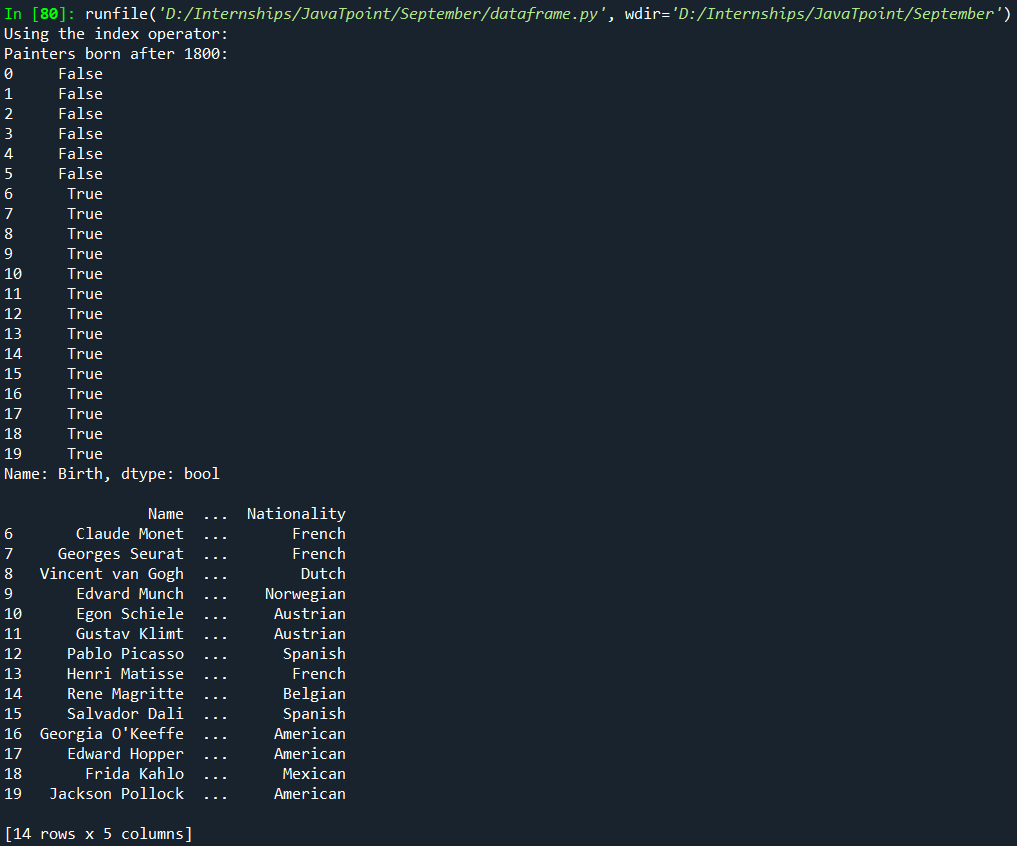
4. Using loc[], we can pass the condition directly to the operator as we pass to df[]. The additional advantage we can get by using loc[] is that we can select the columns using slicing. Here is an example: Output: 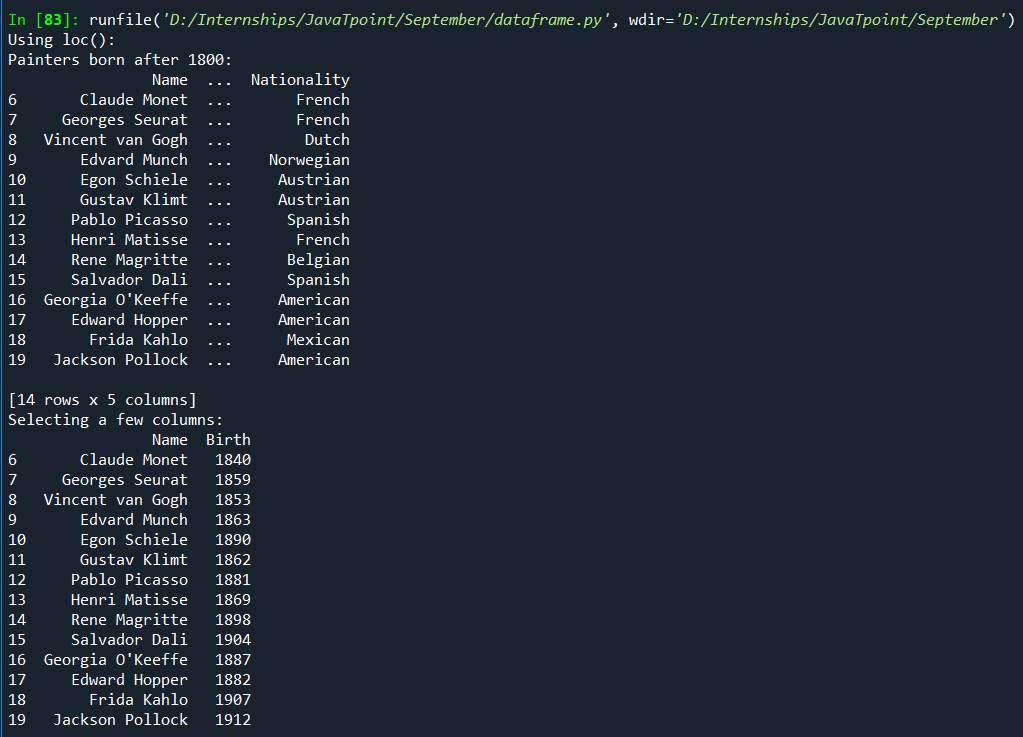
4. head() and tail()These two methods are mostly used to view data samples from a huge amount of data. Head() is used to get the samples from the start and tail() from the end. If we don't pass any argument, head() prints the first five rows of the DataFrame, and tail() prints the last five rows of the DataFrame. We can pass one argument by mentioning the number of rows we need. Syntax: Code: Output: 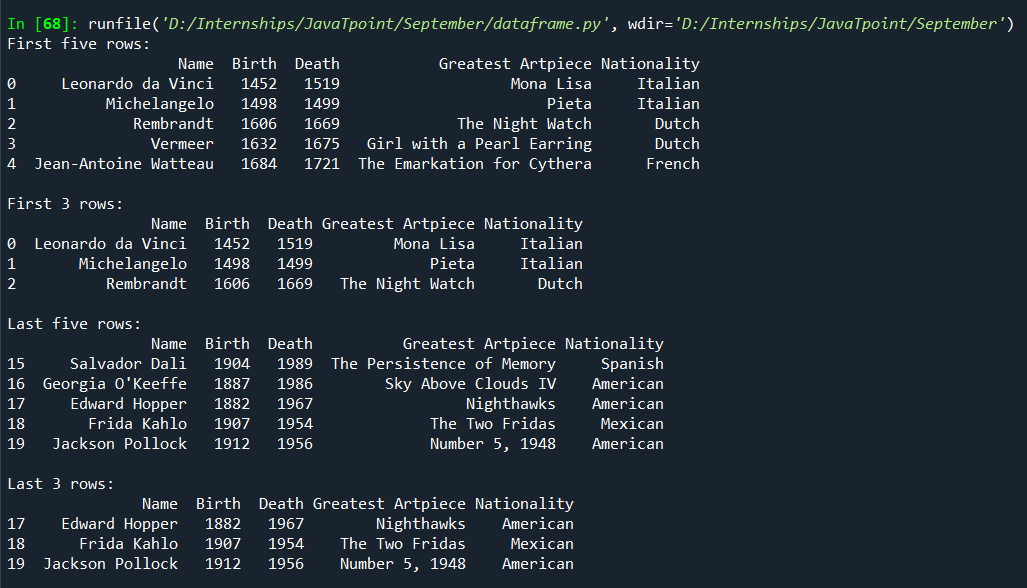
Next TopicHow to Drop Rows in Pandas
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








