| |

Pandas DataFrame.groupby()IntroductionPandas is a famous Python library for data manipulation and analysis. It gives a strong and adaptable method for dealing with data structures, for example, data frames and series. One of the critical highlights of Pandas is the capacity to group data by at least one variables utilizing the groupby() method. In this article, we'll investigate how to utilize groupby() to break down and control data. What is groupby() in Pandas?The groupby() method in Pandas is a useful asset that permits you to group data in light of at least one variables. It is utilized to split an enormous data outline into more modest groups in light of a clear cut variable, for example, a column name, and afterward apply a capability to each group independently. This permits you to dissect subsets of your data independently and analyze them. Syntax:Parameters of Groupby:by:
Its main task is to determine the groups in the groupby. If we use by as a function, it is called on each value of the object's index. If in case a dict or Series is passed, then the Series or dict VALUES will be used to determine the groups. If a ndarray is passed, then the values are used as-is determine the groups. We can also pass the label or list of labels to group by the columns in the self. axis:
level:
It is used when the axis is a MultiIndex (hierarchical), so, it will group by a particular level or levels. as_index:
It returns the object with group labels as the index for the aggregated output. sort:
It is used to sort the group keys. Get better performance by turning this off. It does not influence the order of observations within each group. The Groupby preserves the order of rows within each group. group_keys:
When we call it, it adds the group keys to the index for identifying the pieces. observed:
It will be used only if any of the groupers are the Categoricals. If the value is True, then it will show only the observed values for categorical groupers. Otherwise, it will show all of its values. **kwargs: It is an optional parameter that only accepts the keyword argument 'mutated' that is passed to groupby. ReturnsIt returns the DataFrameGroupBy or SeriesGroupBy. The return value depends on the calling object that consists of information about the groups. Groupby OperationsThis operation consists of the following steps for aggregating/grouping the data:
Note: The result of Groupby operation is not a DataFrame, but dict of DataFrame objects.Split data into groupsGroupby splitting is a method utilized in data analysis to bunch data into subsets in light of the values of at least one variables. The fundamental thought is to parted a dataset into groups in light of a specific variable, and afterward perform some sort of analysis or calculation on each gathering separately. This procedure is in many cases utilized in statistical analysis and AI, as well as in data visualization and exploratory data analysis.
There are multiple ways to split any object into the group which are as follows:
We can also add some functionality to each subset. The following operations can be performed on the applied functionality:
AggregationsIt is defined as a function that returns a single aggregated value for each of the groups. We can perform several aggregation operations on the grouped data when the groupby object is created. Aggregation is a strong method in data analysis that includes joining various values in a dataset to get summary statistics, which help in acquiring experiences and going with informed choices.Aggregation can be performed on a single variable or across various variables in a dataset. Pandas gives an extensive arrangement of functions for performing aggregation tasks, including mean(), sum(), count(), min(), max(), median(), var(), and std(). These functions can be applied to individual columns or gatherings of columns in a DataFrame. Example Output Course B.Ed 98 B.Sc 82 BA 87 M.Phill 91 Name: Percentage, dtype: int64 TransformationsIt is an operation on a group or column that performs some group-specific computation and returns an object that is indexed with the same size as of the group size. In Pandas, transformation includes applying a function to a column or a group of columns in a DataFrame to modify the data, frequently with the end goal of standardization or scaling. Pandas gives the transform() strategy, which applies a function to each group of a groupby object and returns a changed rendition of the first DataFrame. The transform() strategy can be utilized to play out a variety of transformations, including normalizing data, scaling data, and filling missing values. Example Output Percentage 0 NaN 1 NaN 2 NaN 3 NaN FiltrationThe filter() function filters the data by defining some criteria and returns the subset of data. Filtration in Pandas refers to the most common way of choosing a subset of rows from a DataFrame in light of some condition or models. The interaction includes filtering out rows that don't meet the predetermined condition and holding those that do. Pandas gives a few methods to filtration, including boolean indexing, query(), and filter(). These methods permit us to filter the rows of a DataFrame in view of a variety of models, for example, column values, index labels, or conditions including numerous columns. Example Output Name Percentage Course 0 Parker 82 B.Sc 1 Smith 98 B.Ed 2 John 91 M.Phill 3 William 87 BA Example Output 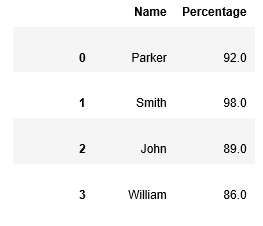
Example Output Name Percentage 0 Parker 82 1 Smith 98 2 John 91 3 William 87 Conclusion:In this article, we've seen the groupby() technique in Pandas and how to utilize it to group data by at least one variables. We've perceived how to apply functions to groups, including various functions utilizing the agg() technique. We've likewise perceived how to utilize contingent articulations with groupby() to make more unambiguous groups. With the groupby() strategy, you can break down and control your data in a strong and adaptable manner.
Next TopicDataFrame.head()
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








