Pandas Dataframe.sample()
The Pandas sample() is used to select the rows and columns from the DataFrame randomly. If we want to build a model from an extensive dataset, we have to randomly choose a smaller sample of the data that is done through a function sample.
Syntax
Parameters
- n: It is an optional parameter that consists of an integer value and defines the number of random rows generated.
- frac: It is also an optional parameter that consists of float values and returns float value * length of data frame values. It cannot be used with a parameter n.
- replace: It consists of boolean value. If it is true, it returns a sample with replacement. The default value of the replace is false.
- weights: It is also an optional parameter that consists of str or ndarray-like. Default value "None" that results in equal probability weighting.
If a Series is being passed; it will align with the target object on the index. The index values in weights that are not found in the sampled object will be ignored, and index values in the sampled object not in weights will be assigned zero weights.
If a DataFrame is being passed when axis =0; it will accept the name of a column.
If the weights are Series; then, the weights must be of the same length as axis being sampled.
If the weights are not equal to 1; it will be normalized to the sum of 1.
The missing value in the weights column is considered as zero.
Infinite values are not allowed in the weights column.
- random_state: It is also an optional parameter that consists of an integer or numpy.random.RandomState. If the value is int, it seeds for the random number generator or numpy RandomState object.
- axis: It is also an optional parameter that consists of integer or string value. 0 or 'row' and 1 or 'column'.
Returns
It returns a new object of the same type as a caller that contains n items randomly sampled from the caller object.
Example1
Output
data1 data2 data3
John 2 2 10
William 0 0 8
Example2
In this example, we take a csv file and extract random rows from the DataFrame by using a sample.
The csv file named as aa that contains the following dataset:
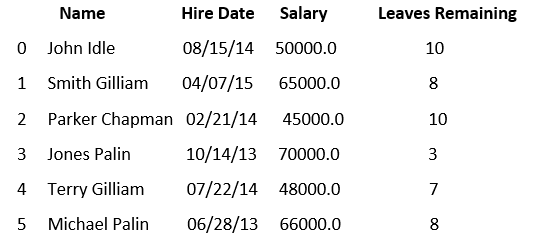
Let's write a code that extract the random rows from the above dataset:
Output
Name Hire Date Salary Leaves Remaining
2 Parker Chapman 02/21/14 45000.0 10
5 Michael Palin 06/28/13 66000.0 8
|

 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now








