| |

JavaCCLike YACC, JavaCC is also a parser. JavaCC is a short form for Java Compiler-Compiler. It is an open-source popular parser generator and lexical analyzer generator tool developed by Oracle Corporation. It is written in the Java programming language. It is licensed under the BSD license. It is widely used with Java applications. It generates top-down parsers. It is mostly used for LL(K) grammar. It also generates lexical analyzers as generates by lex. The Java language extension is provided by the JavaCC that specifies the programming language's grammar. 
Parser GenerationParser and lexical analyzers are the two software components that deal with the input of character sequences. The compiler and interpreters integrate lexical analyzers and parsers. The parsers are used to deciphers the files that contain programs. In other words, the parser reads grammar specifications and converts them into Java programs that recognize the matches to the grammar. Lexical analyzers break the sequence of characters into subsequences called tokens and also classifies the tokens. Therefore, lexical analyzers and parsers can be used with a variety of programs. 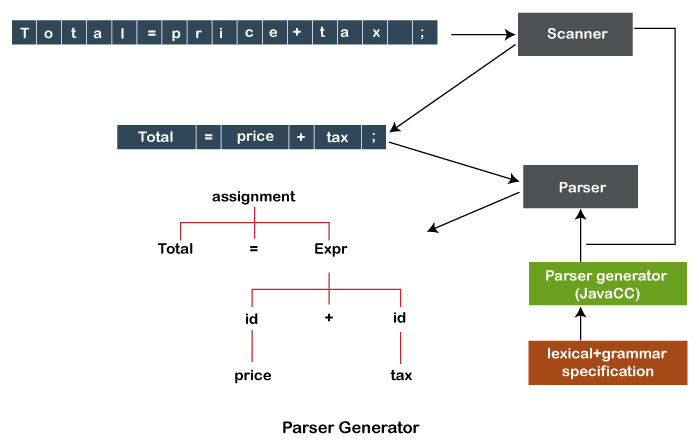
JavaCC is also capable to perform standard parser functionalities such as tree building, debugging, and actions. The functionality of tree building is performed by the tool called JJTree that is inbuilt in JavaCC. Design of JavaCCLet's understand the design of JavaCC through the following diagram. The image shown below describes the relationship between a JavaCC generated lexical analyzer (also called token manager) and a JavaCC generated parser. The JavaCC parser can deal with any programming language only if we have described the rules of the language to JavaCC. But in the following image, we have used the C programming language as input. 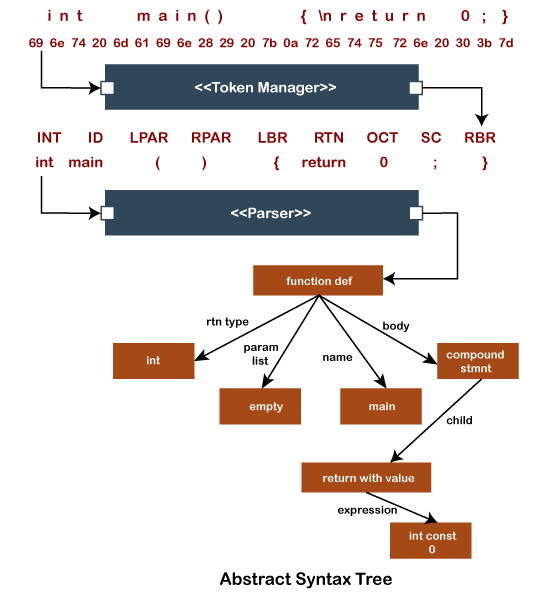
In the above diagram, we see that the token manager reads the input and generates a sequence of objects called tokens. The generation of the token depends upon the rule of the language that we are using to break the sequence of characters. The rules are supplied by the user as a collection of regular expressions. The parser consumes the tokens generated by the token manager. It analyses the structure of tokens and produces an output defined by the user. Features of JavaCC
Download and Install JavaCCThe latest version of JavaCC is 7.0.9. So, we will download and install the latest version and will use it throughout this section. Note: We can also use JavaCC with IDE such as Eclipse and IntelliJ IDEA. If we use JavaCC with IDE, it is required to download the JavaCC plugin.Step 1: Download the JavaCC tool from https://bit.ly/39C5tGZ. It starts downloading the file javacc-javacc-7.0.9.zip. 
Step 2: Unzip the file to the directory where you want. In our case, we have unzipped in the F:\javacc folder. 
Step 3: Create a target directory. We have created a target directory at location F:\javacc\javacc-javacc-7.0.9\target. 
Step 4: Download the javacc-7.0.9.jar file from https://bit.ly/3nKU3G4. Step 5: Copy the JAR file to the newly created target directory. 
Step 6: Rename the JAR file to javacc.jar. 
Now, it's time to verify the installation. Step 7: Open the Command Prompt and navigate the directory F:\javacc\javacc-javacc-7.0.9. Step 8: Execute the following command: After executing the above command, we get lots of stuff related to JavaCC, as shown below. 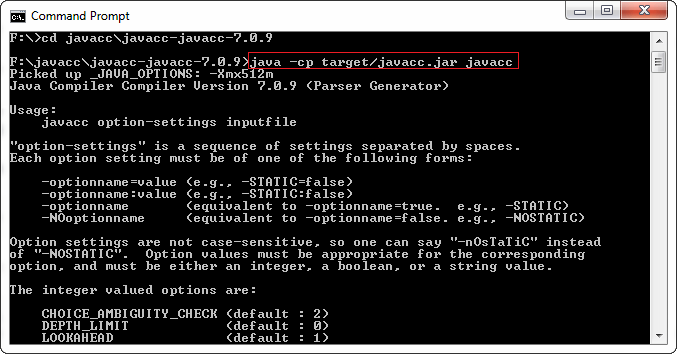
Building JavaCC From SourceThe source directory contains the sources of JavaCC, JJTree, and JJDoc, launcher scripts, example grammars, and documentation. It also contains a bootstrap version of JavaCC needed to build JavaCC. Prerequisites for Building JavaCC:
Steps to Use JavaCCStep 1: Write a JavaCC specification. It means, we need to create a .jj file. In this file, define grammar and actions. Suppose, we have generated demo.jj. Step 2: Run JavaCC that generates a parser and a scanner. We use the javacc command to execute the .jj file. The above command generates tokens, scanner, and parser. Step 3: Create a Java program that uses the parser. Suppose we have created a program with the name DemoParser.java. Step 4: At last, compile and run the Java program that we have created in the previous step. Use the following commands to run the program: Uses of JavaCCJavaCC has been used to develop different types of parsers that are based on formal and proprietary specifications.
Software Built Using JavaCCThe following software has been developed using JavaCC:
Remember
Files Generated by JavaCCThe JavaCC is a program generator tool. It reads the .jj file and generates a number of .java files if there is no error in the .jj file. It generates the following files with the default options. Boilerplate Files
The files described in the above table, generated only if they have not generated before. If the changes in the file are required, we should do the changes before running the JavaCC. Also, ensure that JavaCC will not overwrite them. Custom Files
Note: In the above table, instead of Demo, you can choose any name.JavaCC Default OptionsThere are the following options provided by JavaCC:
Token ManagerA token manager is a lexical analyzer that analyses the input of characters and breaks them into chunks called tokens. It also assigns types to each token. For example, consider the following code snippet: The above code is broken into tokens by the token manager, as follows: The token manager does not take care of the comments and whitespaces. So, we are considering them. Hence, after removing comments and whitespaces, we get the following tokens: As we have above discussed, each token has a type. Therefore, the above tokens can be classified as follows: Each token is denoted by the object of the Token class. The sequence of tokens is further delivered to the parser for further processing.
Next TopicUnique Number in Java Program
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








