| |

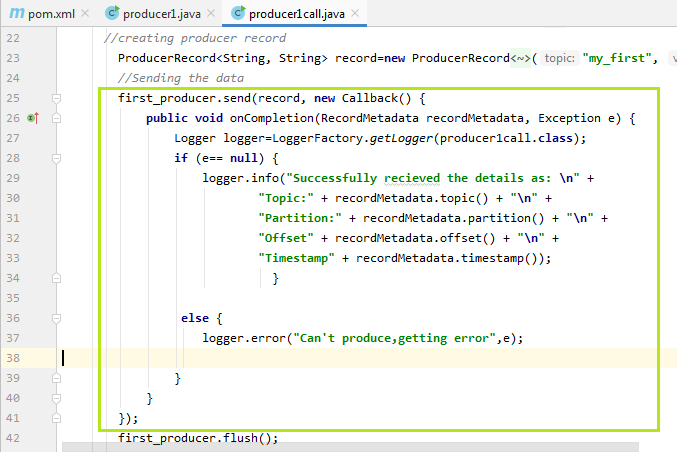
Kafka Producer CallbacksProducer without KeysIn the previous section, we saw how a producer sends data to Kafka. In order to understand more deeply, i.e., whether the data was correctly produced, where it was produced, about its offset and partition value, etc. Let's learn more. For performing the callbacks, the user needs to implement a callback function. This function is implemented for asynchronously handling the request completion. That's why it's return type will be void. This function will be implemented in the block where the producer sends data to the Kafka. There is no requirement to make changes in other blocks of codes. The callback function used by the producer is the onCompletion(). Basically, this method requires two arguments: Metadata of the Record: Metadata of the record means fetching the information regarding the partition and its offsets. If it is not null, an error will be thrown. Exception: There are following exceptions which can be thrown while processing: 1) Retriable exception: This exception says that the message may be sent. 2) Non-retriable exception: This exception throws the error that the message will never be sent. Let's see the implementation of the Producer callback in the below snapshot:
An object of 'Logger' has been created, which allows to import 'slf4j.Logger' and 'slf4j.LoggerFactory'. This logger object will log the information regarding the partition, offsets, as well as the timestamp. If the exception value is equal to null, the logger will display the information, else an error will be displayed. When the above code is executed, the user will come to know the topic name, partition number, timestamp, offset value where the message is sent. A snapshot of the output is shown below: 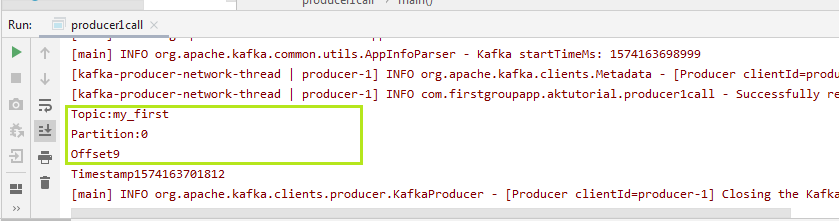
In the above output, it is seen that the message is produced to 'my_first', stored at 'partition 0' having the 'offset value 9'. Note: The messages we sent till now are without keys, therefore messages without keys get stored in the random partitions and behave asynchronously.Producer with KeysKeys become useful when a user wants to send the message to the same partition. In order to send the data, the user need to specify a key. The key will uniquely identify the partition from the other partitions. The user needs to send synchronous messages to the Kafka. One way to implement a key is shown below: 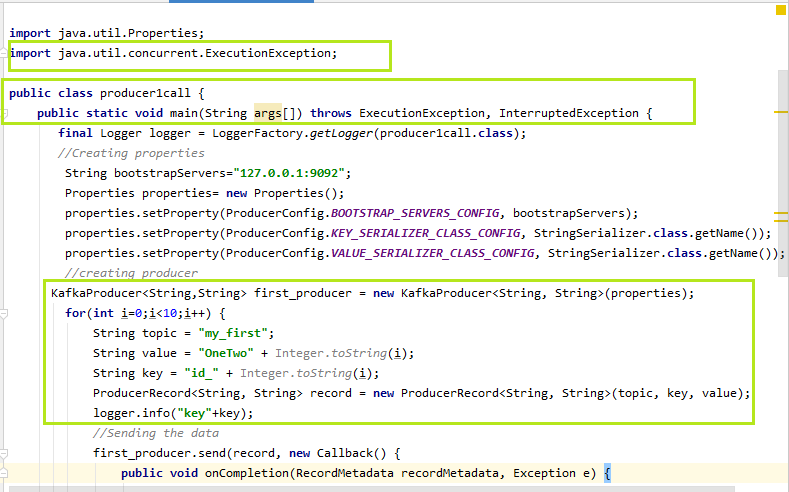
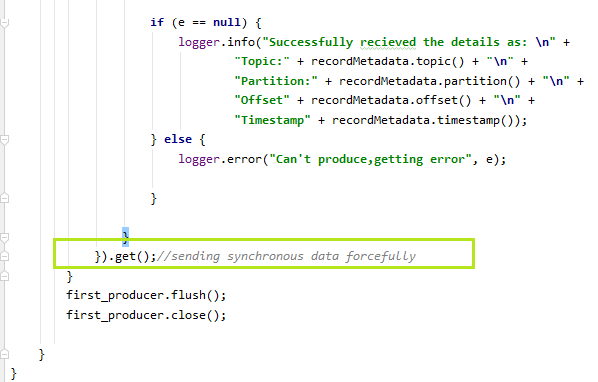
In the above snapshot, we have specified the topic name, its value, and the key. While creating the ProducerRecord, three of them are passed as the parameters. If the exception 'e' will be equal to null, the logger will fetch the information about the key. At the end, a get() function is used when the data is sent to the Kafka. This method sends the data synchronously and forcefully. The users can try their own ways to implement the keys. Note: Using the get(), a red underline will appear. Press alt+enter, it will say to 'Add exceptions to method signature', select it. This will add two exceptions to the main(), as shown above. Also, it will import 'java.util.concurrent.ExecutionException' to the code.When the above code is executed, the output is displayed as: 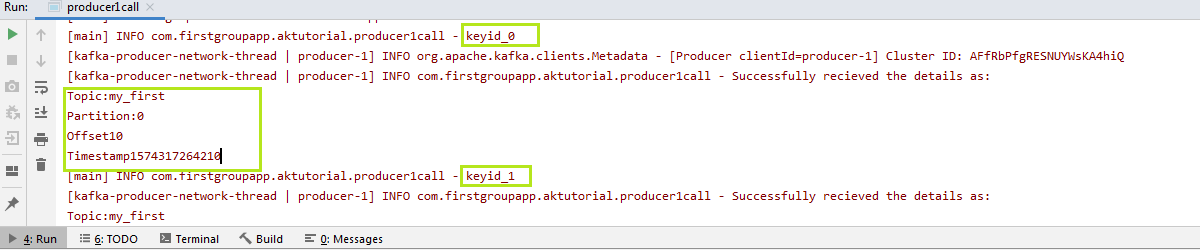
The highlighted parts in the output tell the key values, topic name, partition number, offset value, as well as the timestamps. The message 'OneTwo' will always go to the specified partitions now. So, in this way, a producer can send data to the Kafka with and without keys.
Next TopicCreating Kafka Consumer in Java
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








