| |

Kafka TopicsIn the previous section, we have taken a brief introduction about Apache Kafka, messaging system, as well as the streaming process. Here, we will discuss the basic concepts and the role of Kafka. TopicsGenerally, a topic refers to a particular heading or a name given to some specific inter-related ideas. In Kafka, the word topic refers to a category or a common name used to store and publish a particular stream of data. Basically, topics in Kafka are similar to tables in the database, but not containing all constraints. In Kafka, we can create n number of topics as we want. It is identified by its name, which depends on the user's choice. A producer publishes data to the topics, and a consumer reads that data from the topic by subscribing it. PartitionsA topic is split into several parts which are known as the partitions of the topic. These partitions are separated in an order. The data content gets stored in the partitions within the topic. Therefore, while creating a topic, we need to specify the number of partitions(the number is arbitrary and can be changed later). Each message gets stored into partitions with an incremental id known as its Offset value. The order of the offset value is guaranteed within the partition only and not across the partition. The offsets for a partition are infinite. Note: The data once written to a partition can never be changed. It is immutable. The offset value always remains in an incremental state, it never goes back to an empty space. Also, the data is kept in a partition for a limited time only.Let's see an example to understand a topic with its partitions. 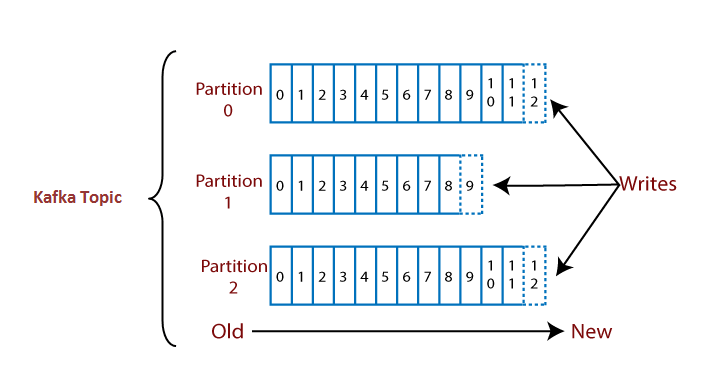
Suppose, a topic containing three partitions 0,1 and 2. Each partition has different offset numbers. The data is distributed among each offset in each partition where data in offset 1 of Partition 0 does not have any relation with the data in offset 1 of Partition1. But, data in offset 1of Partition 0 is inter-related with the data contained in offset 2 of Partition0. BrokersHere, comes the role of Apache Kafka. A Kafka cluster is comprised of one or more servers which are known as brokers or Kafka brokers. A broker is a container that holds several topics with their multiple partitions. The brokers in the cluster are identified by an integer id only. Kafka brokers are also known as Bootstrap brokers because connection with any one broker means connection with the entire cluster. Although a broker does not contain whole data, but each broker in the cluster knows about all other brokers, partitions as well as topics. 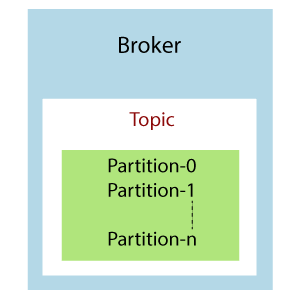
This is how a broker looks like in the figure containing a topic with n number of partitions. Example: Brokers and TopicsSuppose, a Kafka cluster consisting of three brokers, namely Broker 1, Broker 2, and Broker 3. 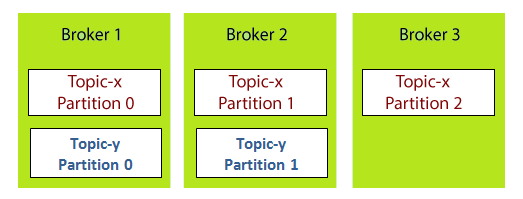
Each broker is holding a topic, namely Topic-x with three partitions 0,1 and 2. Remember, all partitions do not belong to one broker only, it is always distributed among each broker (depends on the quantity). Broker 1 and Broker 2 contains another topic-y having two partitions 0 and 1. Thus, Broker 3 does not hold any data from Topic-y. It is also concluded that no relationship ever exists between the broker number and the partition number.
Next TopicApache Kafka Topic Replication
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








