| |

Kafka Stream ProcessingTill now, we learned about topics, partitions, sending data to Kafka, and consuming data from the Kafka. This could be a lower level of abstraction. Thus, a higher level of abstraction is required. This consequently introduces the concept of Kafka streams. Kafka StreamsGenerally, streams define the flow of data elements which are provided over time. In Apache Kafka, streams are the continuous real-time flow of the facts or records(key-value pairs). Kafka Streams is a light-weight in-built client library which is used for building different applications and microservices. The input, as well as output data of the streams get stored in Kafka clusters. Kafka Streams integrates the simplicity to write as well as deploy standard java and scala applications on the client-side. Why Kafka Streams?There are the following properties that describe the use of Kafka Streams:
Stream ProcessingSimilar to the data-flow programming, Stream processing allows few applications to exploit a limited form of parallel processing more simply and easily. Thus, stream processing makes parallel execution of applications simple. The business parties implement the core functions using the software known as Stream Processing software/applications. Stream Processing TopologyApache Kafka provides streams as the most important abstraction. Streams are repayable, ordered as well as the fault-tolerant sequence of immutable records. The stream processing application is a program which uses the Kafka Streams library. It requires one or more processor topologies to define its computational logic. Processor topologies are represented graphically where 'stream processors' are its nodes, and each node is connected by 'streams' as its edges. The stream processor represents the steps to transform the data in streams. It receives one input record at a time from its upstream processors present in the topology, applies its operations, and finally produces one or more output records to its downstream processors. 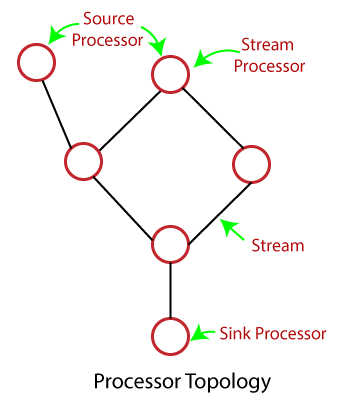
There are following two major processors present in the topology:
In addition, Kafka Streams provides two ways to represent the stream processing topology:
Next TopicKey concepts of Stream Processing
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








