| |

Data Augmentation ProcessPreviously, we saw a significant increment in model accuracy. Our model was effectively trained to classify the training data. It did not generalize well for the validation data to fix the overfishing issue. Now, let's discuss one more technique to improve the model training process. This technique is known as data augmentation. It is the process by which we create new data for our model to use during the training process. This is done by taking our existing dataset and transforming or altering the image in useful ways to create new images. 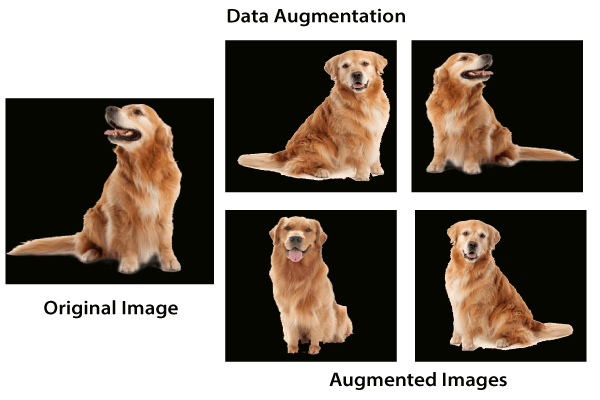
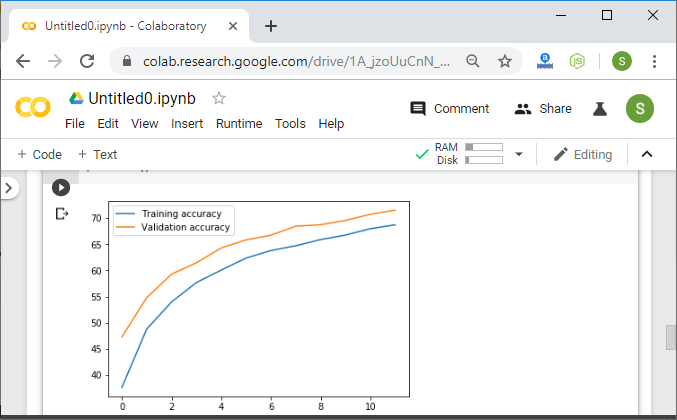
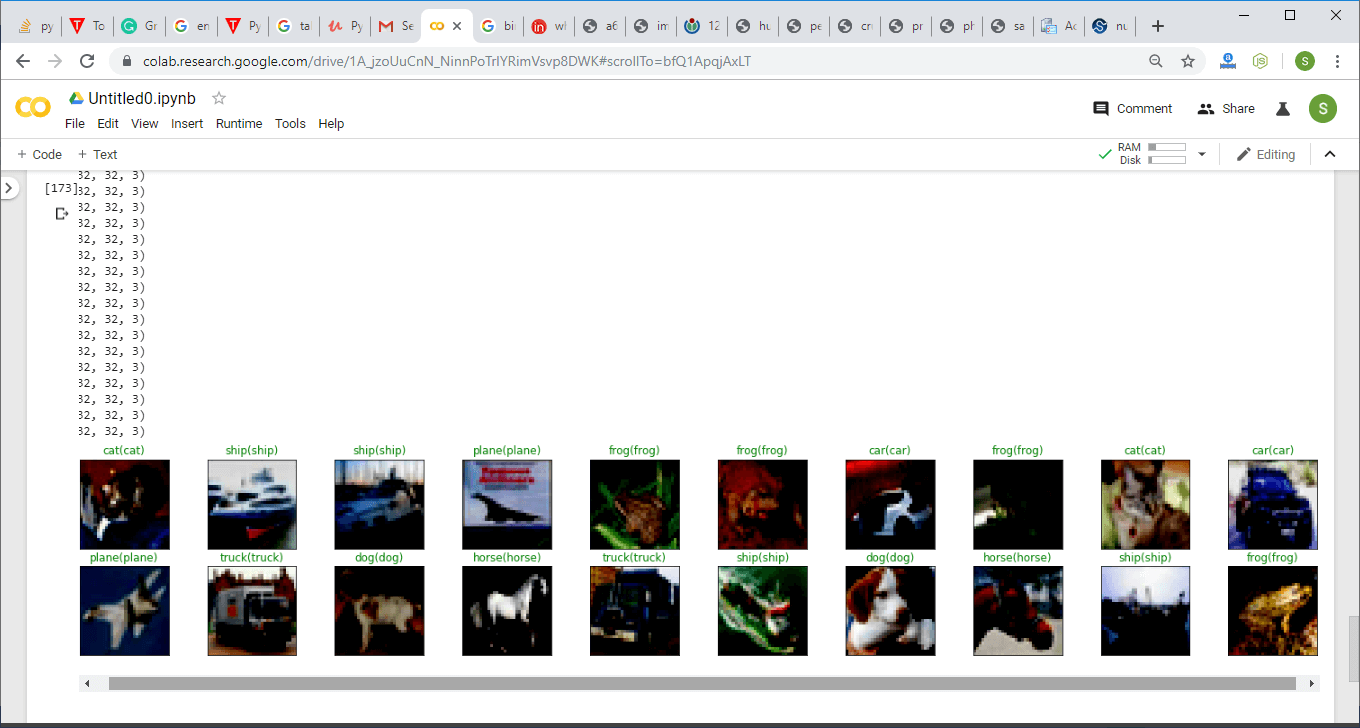
After applying the transformation, the newly created images are known as augmented images because they essentially allow us to augment our dataset by adding new data to it. The data augmentation technique is useful because it allows our model to look at each image in our dataset from a variety of different perspective. This allows our model to extract relevant features more accurately and to obtain more feature-related data from each training image. Now our biggest question is how we will use that augmentation to reduce overfitting. The overfitting occurs when our model is too closely fit the training set. There is no need to start collecting new images and adding them to our datasets. We can use data augmentation which introduces minor alteration to our existing datasets such darker shading, flips, zooming, rotations or translation. Our model will interpret them as separate distinct images. It will not only reduce over fitting but it also prevents our network from learning irrelevant patterns and boosts overall performance. We have the following steps to perform data augmentation: Step 1: To perform data augmentation on training dataset, we have to make to make a separate transform statement. For validation dataset the transform will remain same. So we first copy our transform1 statement and treat it as transform_train as: Step 2: Now, we will add alternation in our transform_train statement. The alternations will be a RandomHorizontalFlip, RandomRotation which is used for rotation of an image by a certain angle and that angle will be passes as an argument. To add even more variety to our dataset, we will use a fine type transformation. Fine transformation represent simple transformation which preserve straight lines and planes with the object. Scaling, translation, shear and zooming is a transformation which fits this category. In RandomAffine(), the first argument is decrease which we set zero to deactivate rotation, second argument is the shear transformation and the last one is the scaling transformation and use a topple to define the range of zoom which we have required. We defined a lower and upper limit of 0.8 and 1.2 to scale images to 80 or 120 percent of their size. Step 3: Now, we move onto our next augmentation to create new augmented images with a randomized variety of brightness, contrast and saturation. We will add another transformation i.e. ColorJitter as: Step 4: Before executing our code, we have to change the training_dataset statement because now we have another transform for the training dataset. So Now, we will execute our code, and after execution, it will give us the expected output with a correct prediction. 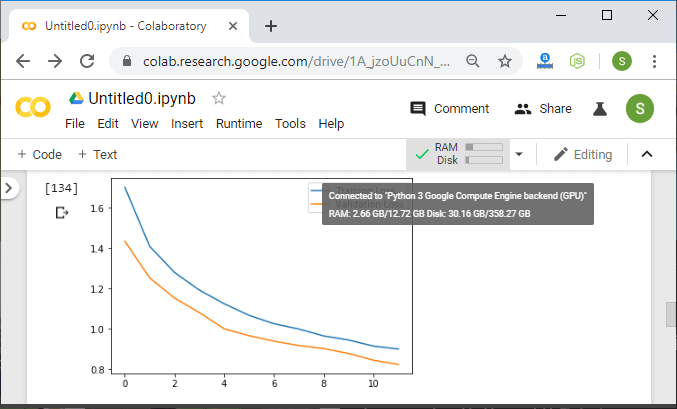
Complete Code: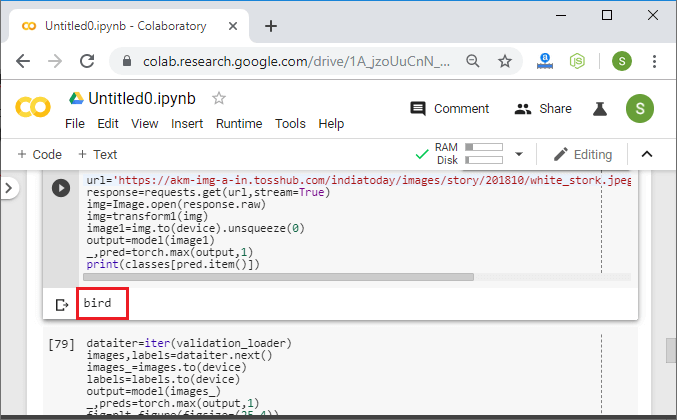
Next TopicStyle Transferring in PyTorch
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








