| |

Define Input of Independent Sample T-TestIn this section, we will learn Independent sample T-test, and how to calculate the differences between two group Means. When we have two groups to compare and we want to find out whether there are significant differences between the two groups or not, we can go for a Mean comparison between two groups. Independent sample t-test is a powerful test for finding out the group differences between two group means. To calculate the Independent sample T-test, we will go to the Analyze menu and then go to Compare Means. Now we can see the Independent sample T-test like this: 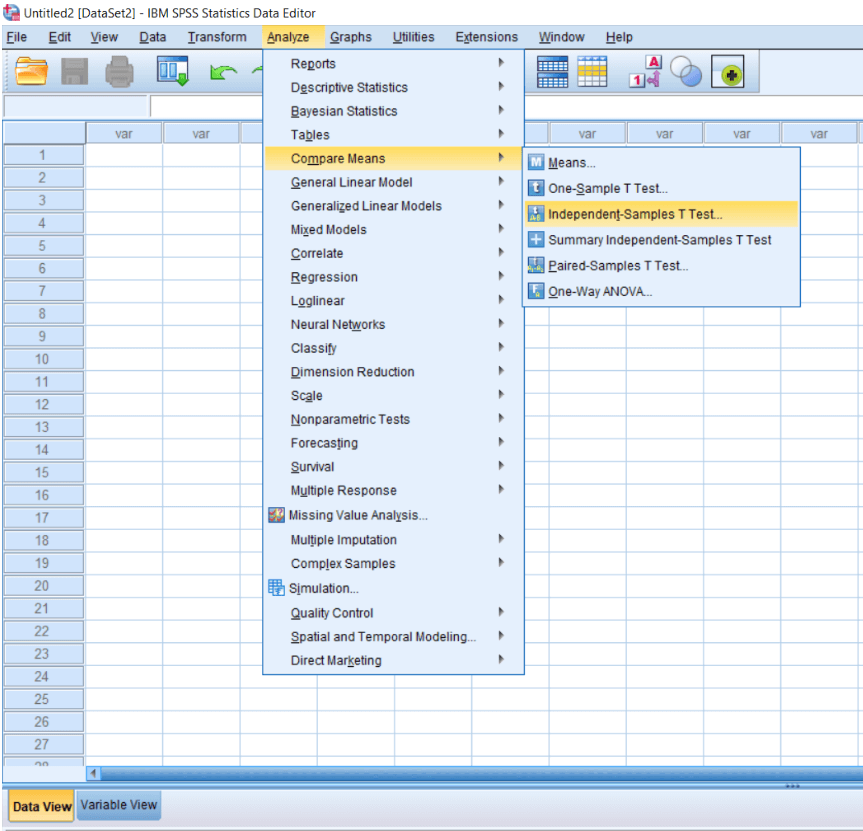
The symbol of Independent sample T-test read as t A-B. It means the group we are comparing A and B are independent of each other. For example, suppose we want to compare the salary of males and females or the population of two cities like Delhi or Mumbai. In this case, the groups are not related to each other. So we can go for an Independent sample t-test. To calculate the independent sample t-test, we will open our Data set. We will go to the File menu, then go to Recently used Data as follows: 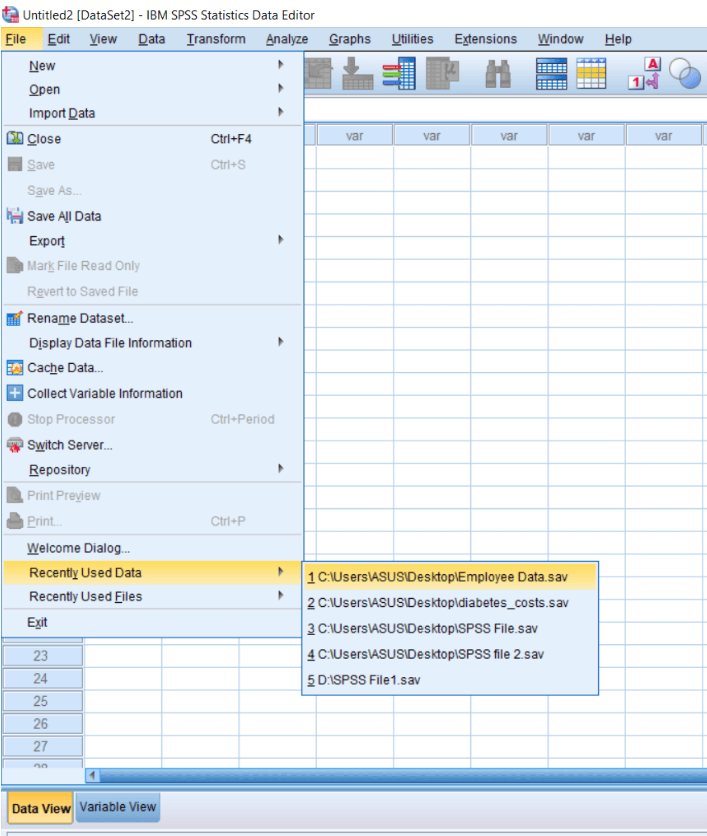
Now we will click on the above Employee Data option and see our Employee Data set as follows: 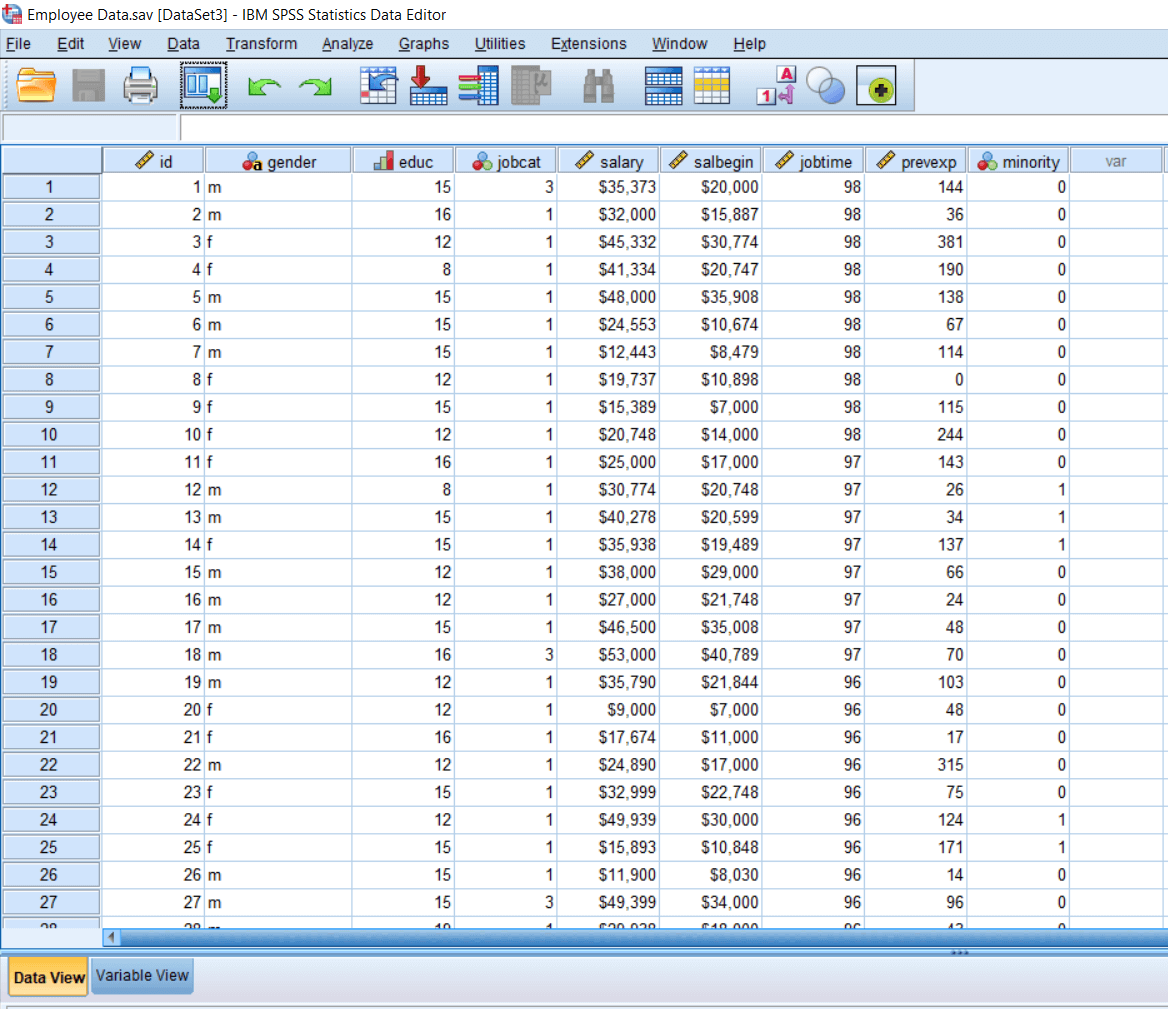
This is an Employee data set where we have the id of an employee, their gender, education, job category, salary, beginning salary, job timing, previous experience, and whether they belong to minority or majority group. In this case, suppose we want to test that there is a significant difference between the Salary of males and females. To test that, we can conduct an Independent sample t-test. Similarly, suppose we want to determine whether people from minority categories are taking a lesser amount of Salary than people from the majority community. In that case, we can again calculate the Independent sample t-test. To test the independent sample t-test, we will go to the Analyze menu and then go to Compare Means option. In the Compare Means option, we locate the Independent sample t-test. When we click on it, we will see a dialog box like this: 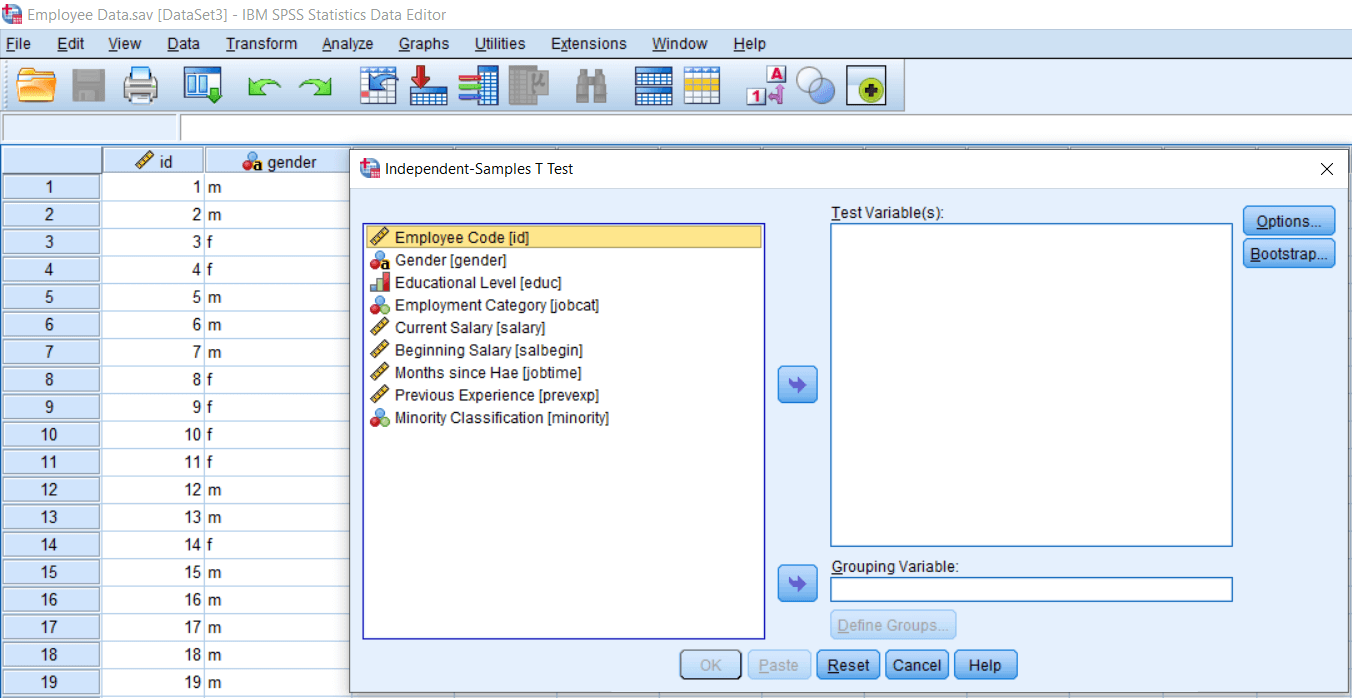
Now we want to compare people across Gender. In this case, Gender has been defined as a String variable. So to calculate any meaningful test, we need to define all variables as a Numeric variable. So we will change the definition of the gender variable. We will turn it into a Numeric variable from String. So we will go to our Variable view and look at the Gender as follows: 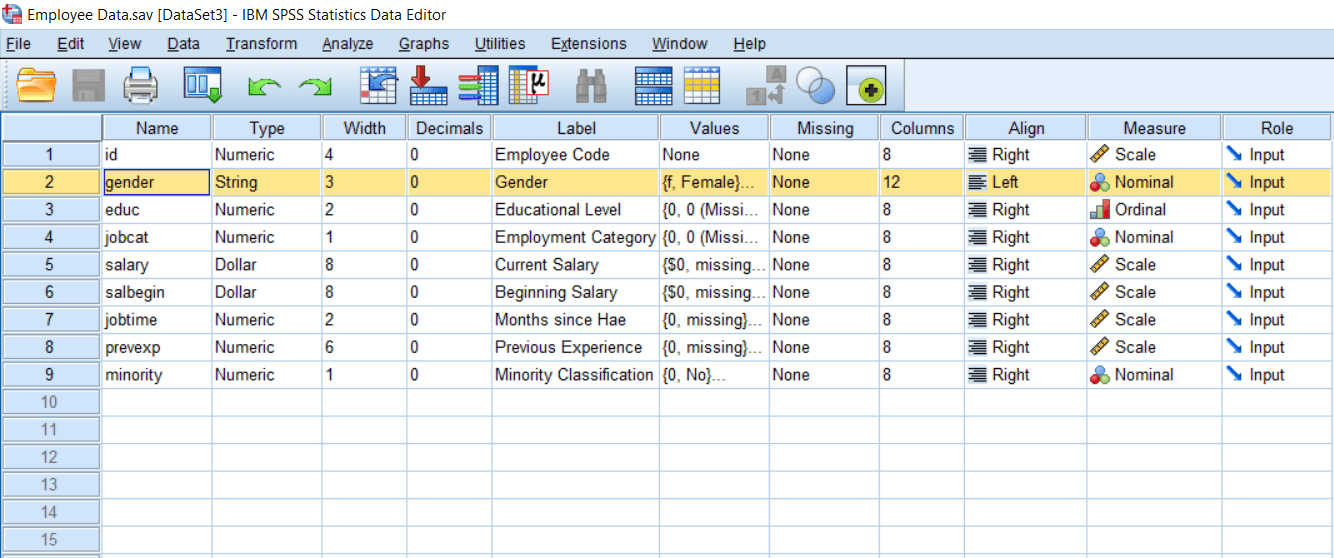
Since it's a String, so first, we need to convert the value. So we will select the row, press Ctrl+F, and then click on Replace. We will find m and replace it by 1 and then click on Replace all. 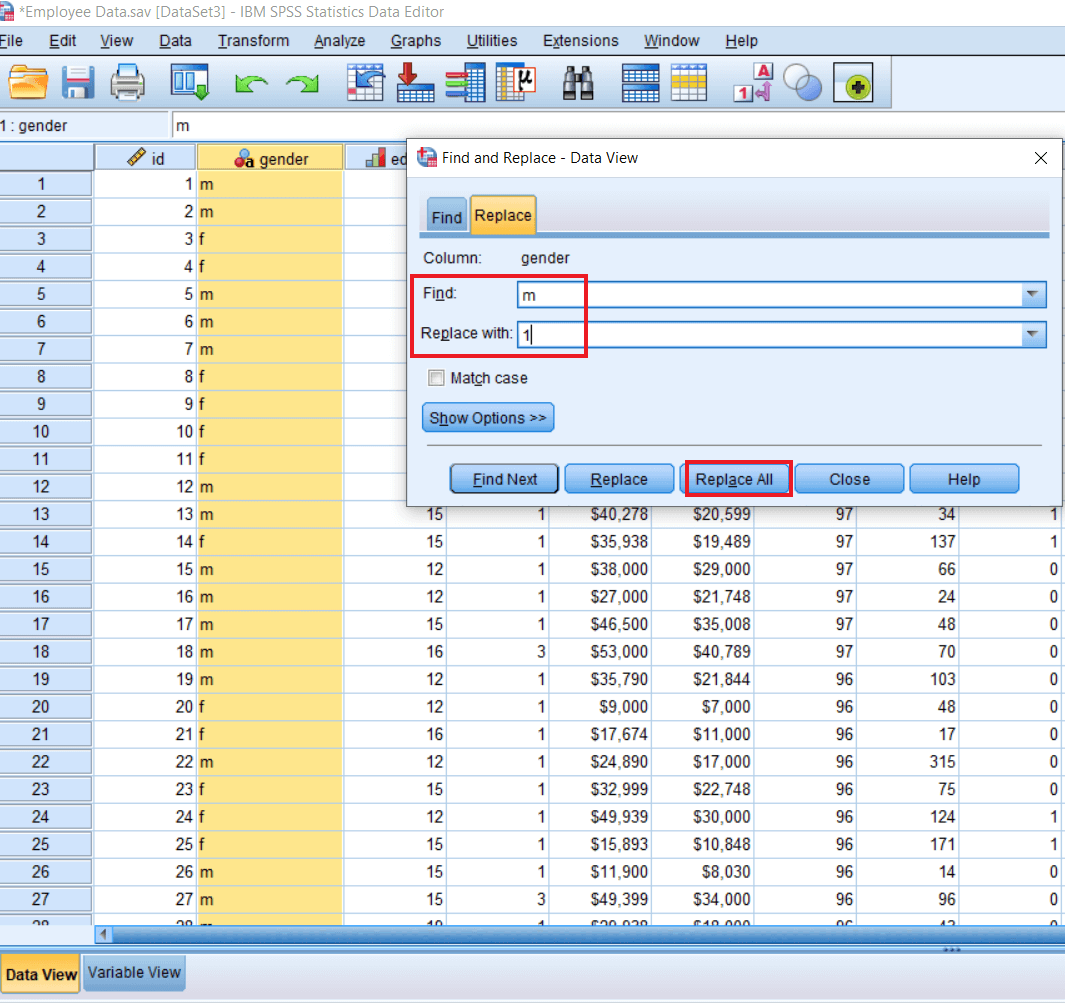
Similarly, we will write f and replace it by 2 and click on Replace all. After this, we will see the following changes in the Gender variable: 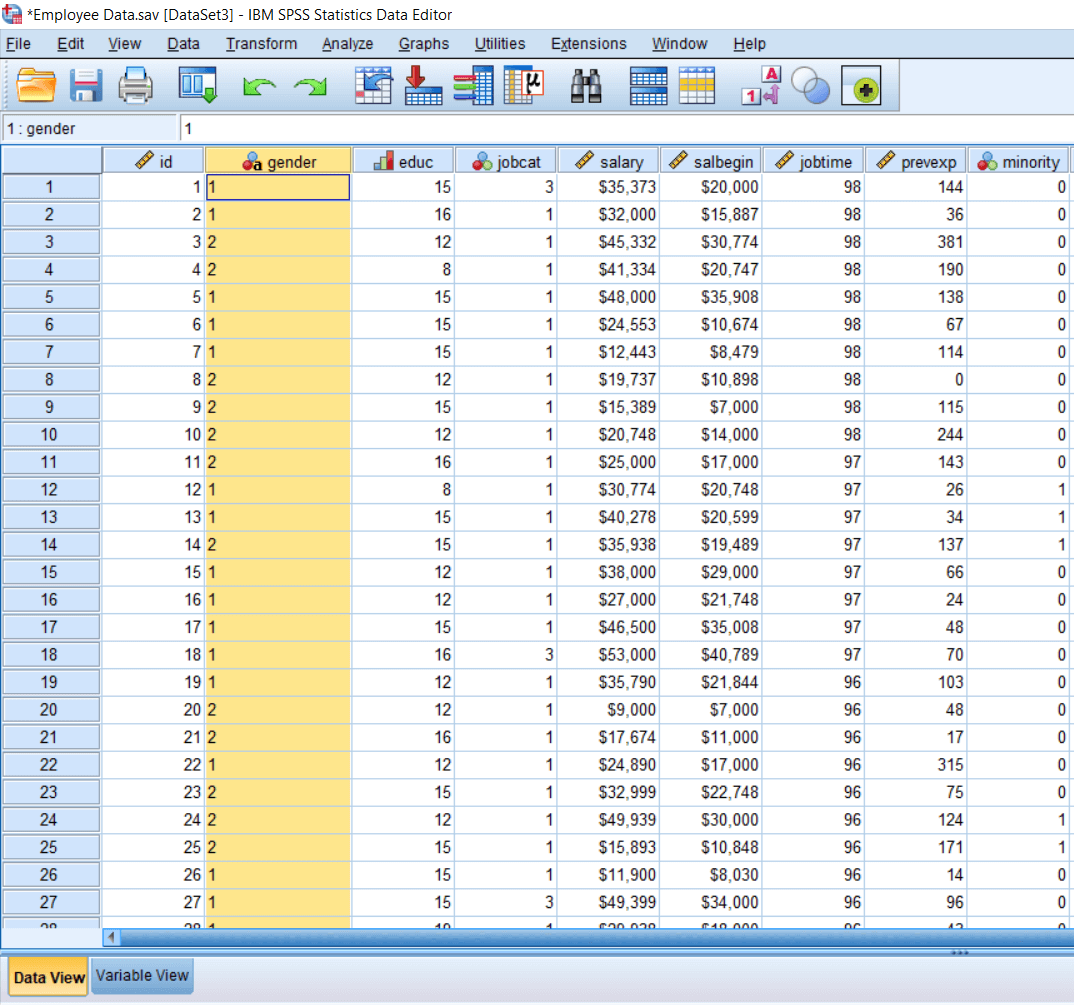
Now we have to redefine this Gender variable. So we will go to the Variable view option and click on the Value step of the Gender variable. Now we will select the female option and define Value as 2 and click on Change as follows: 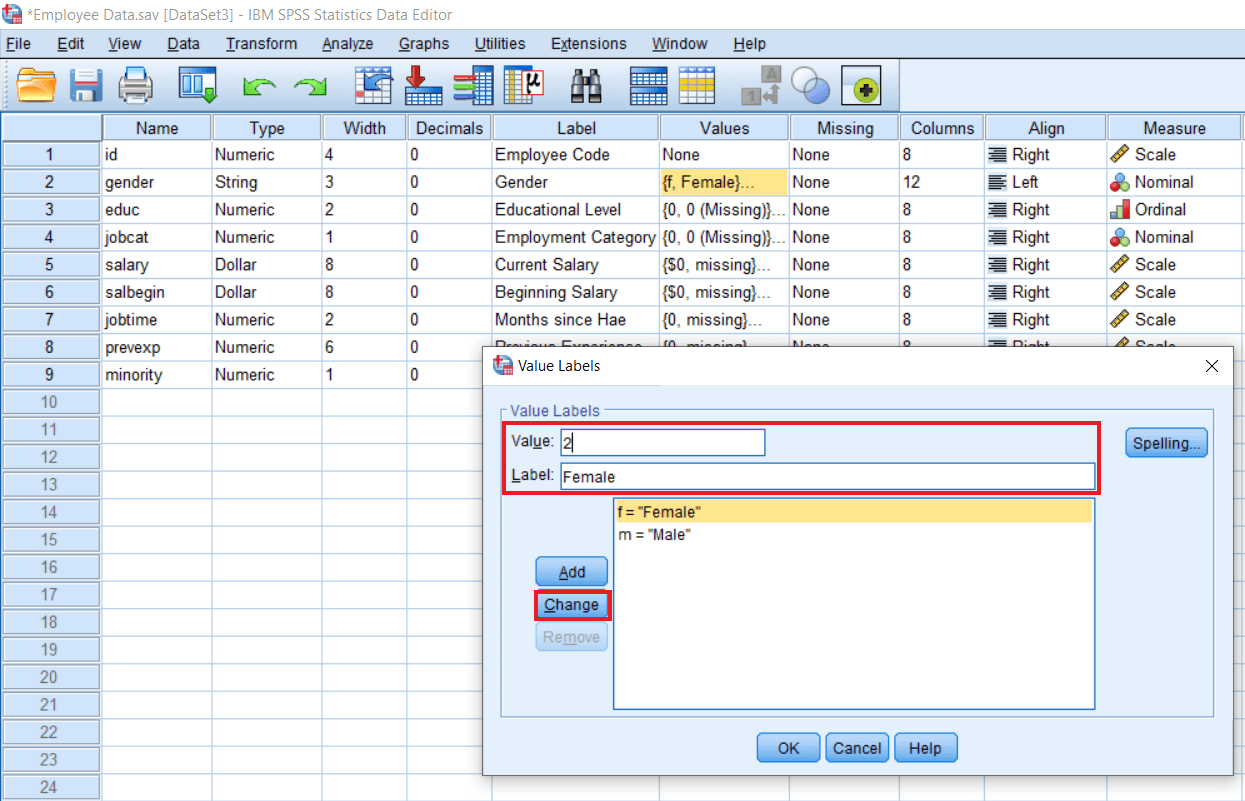
Again select the male option and define Value as 1 and click on Change. Now press Ok. 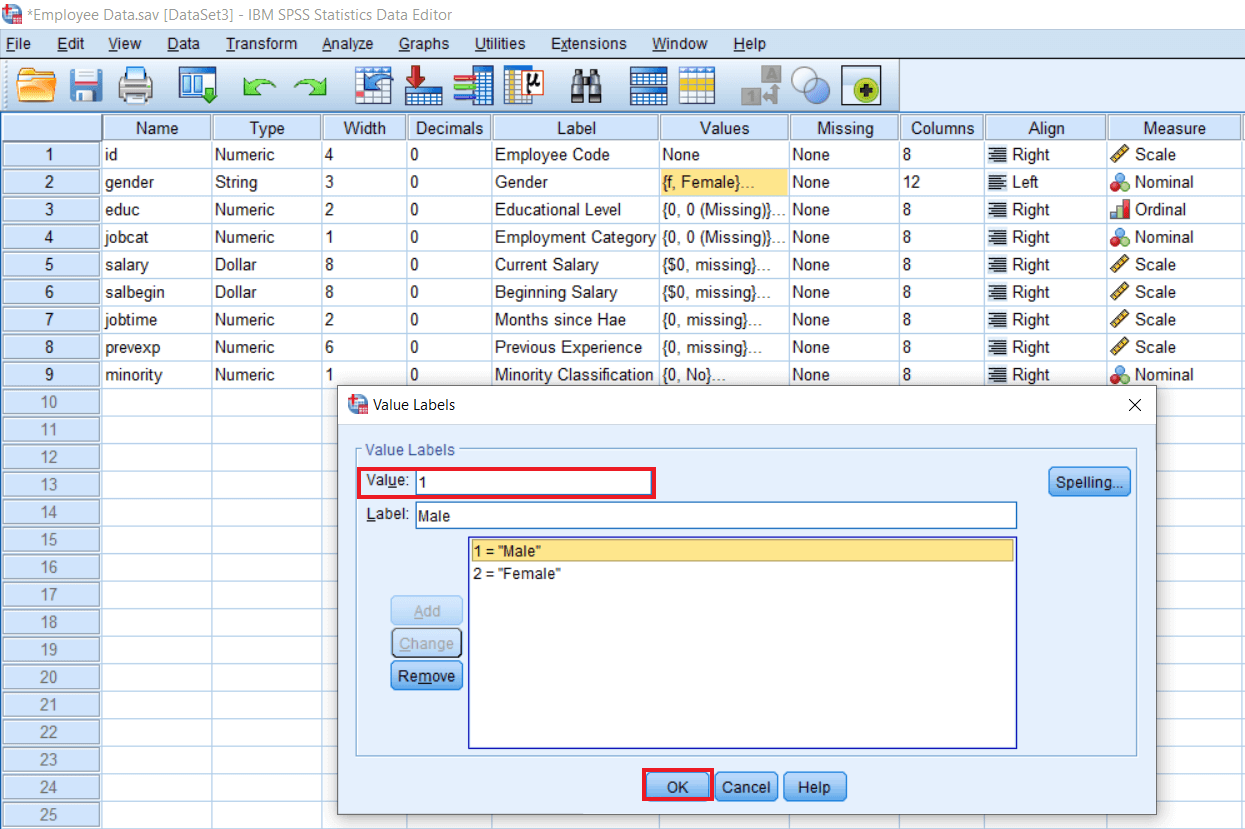
Now we can change the Gender from String to Numeric variable like this: 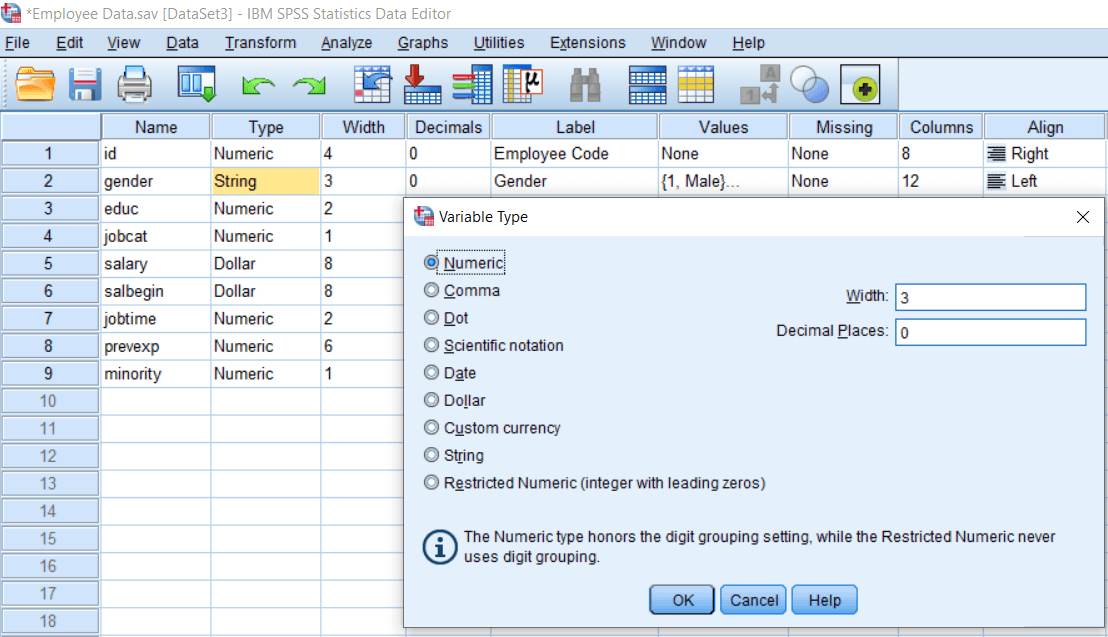
Now variables have been defined. We will go to Compare Means option and click on an Independent sample t-test. So we want to compare genders for their salary. We will take the Salary as our Test variable and Gender as a Grouping variable. So the Salary is our dependent variable, and Gender is our independent variable. 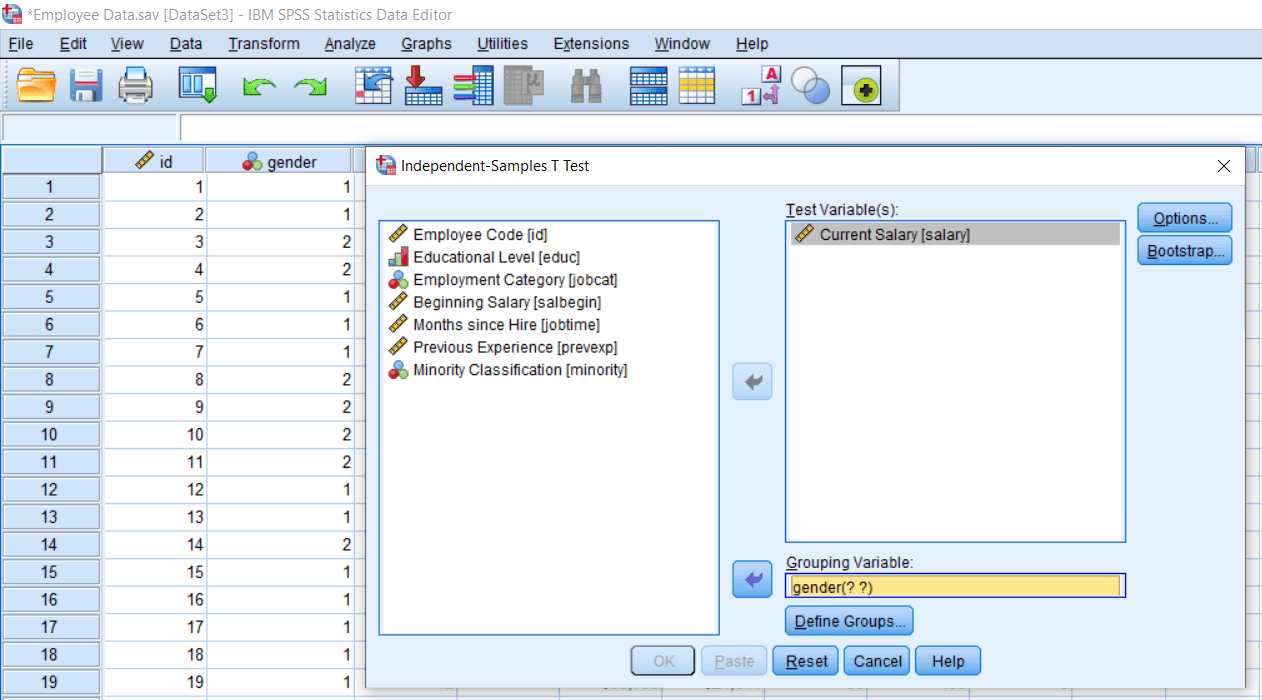
In the above image, under the Grouping variable, we can see two question marks. It means we need to define our groups. So click on Define Groups option and write 1 for Group 1 and 2 for Group 2. So, 1 is for males, and 2 is for females. We can also define the Cut point instead of defining the groups. For example, suppose we have an exact salary and want to take a cutoff salary, which could be a median salary or any salary, suppose 10000. In that case, SPSS will compare two groups less than 10000 and more than 10000, and we will do significant testing between these two groups. Currently, we are using our group definition, so click on Continue like this: 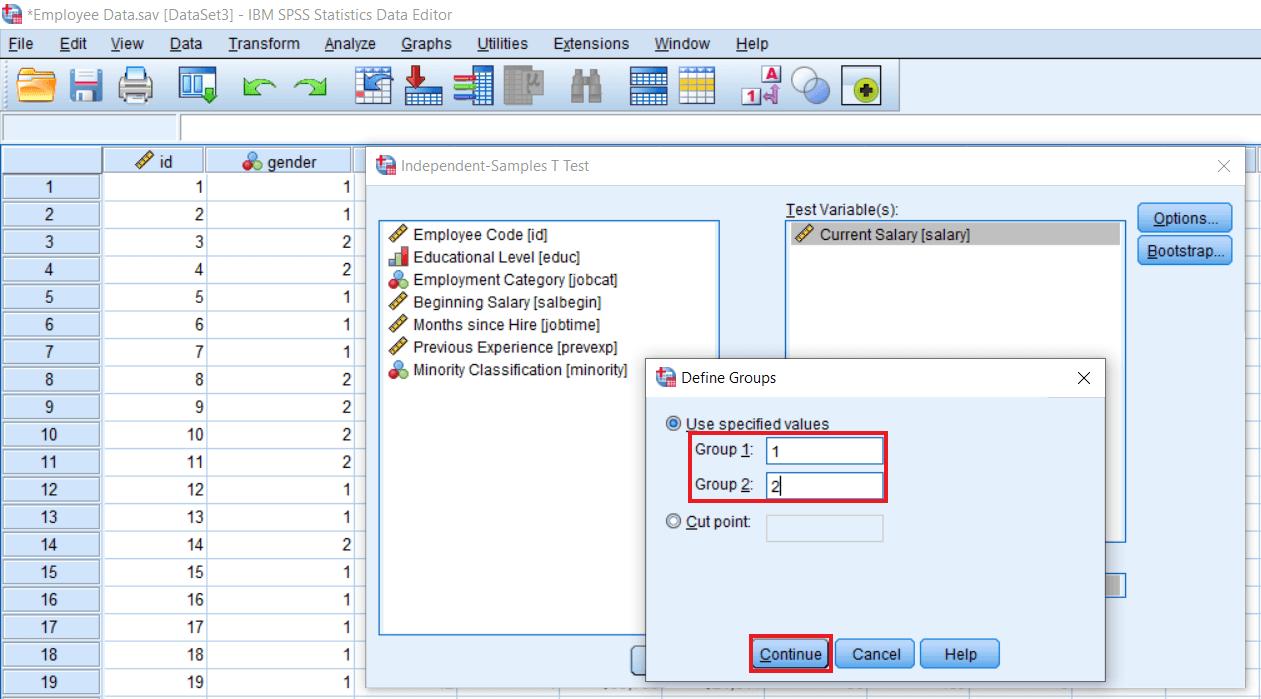
Now we will click on Options where we can select a 95% Confidence Interval by default. If we want to change, we change it and make it as 99%, but let's begin with the default value 95%. 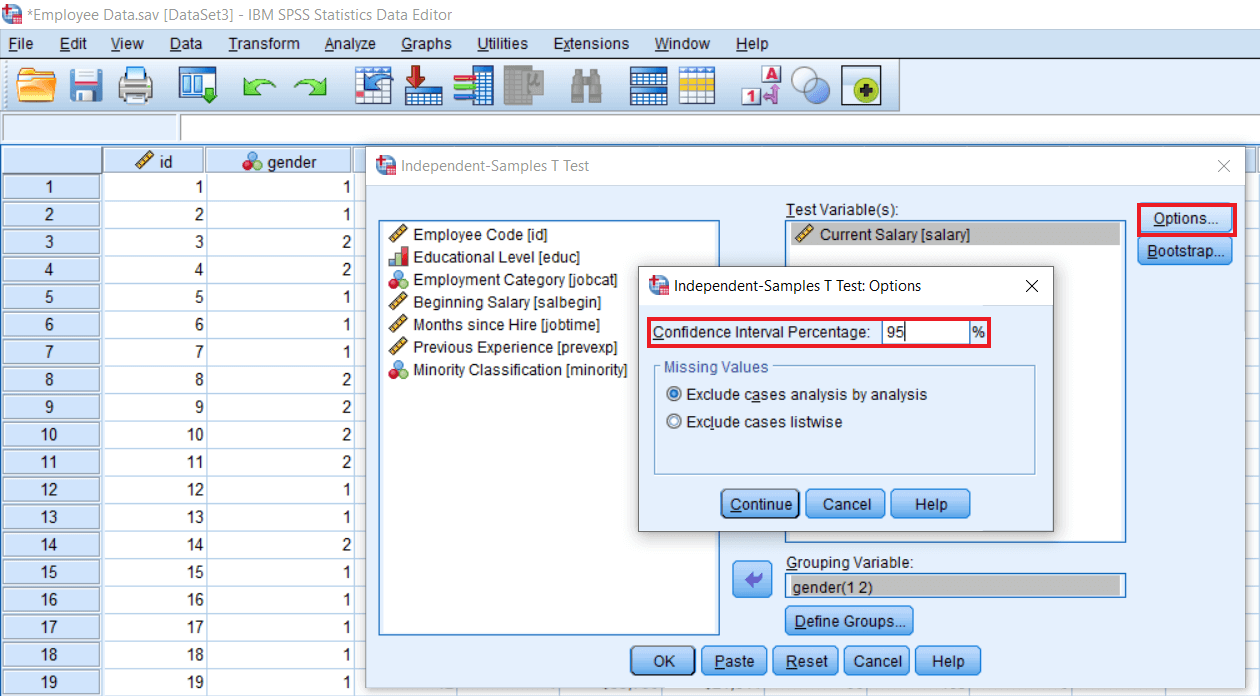
In the missing value, we are going with the default value Exclude case analysis by analysis. It basically leads to a lesser amount of data loss as compare to Exclude cases listwise. So we will take it as an analysis by analysis method. Now we will click on Continue. 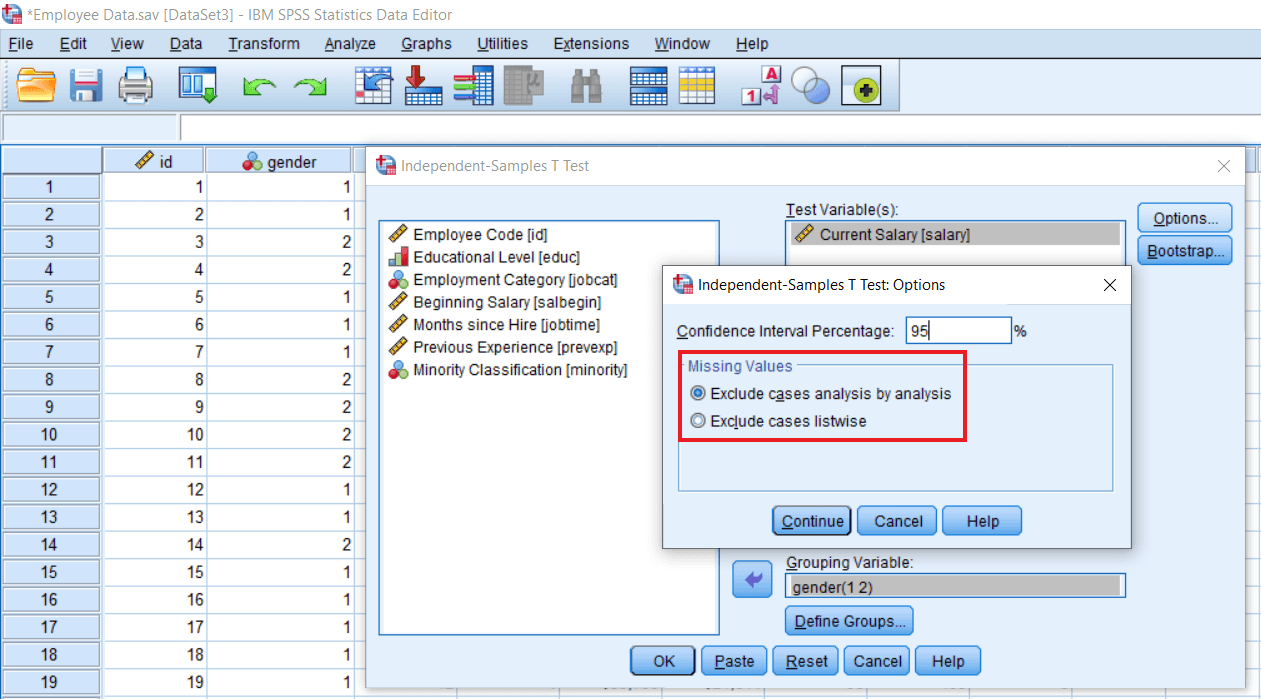
Now we will click on Ok, and after that, we will see the following Output: 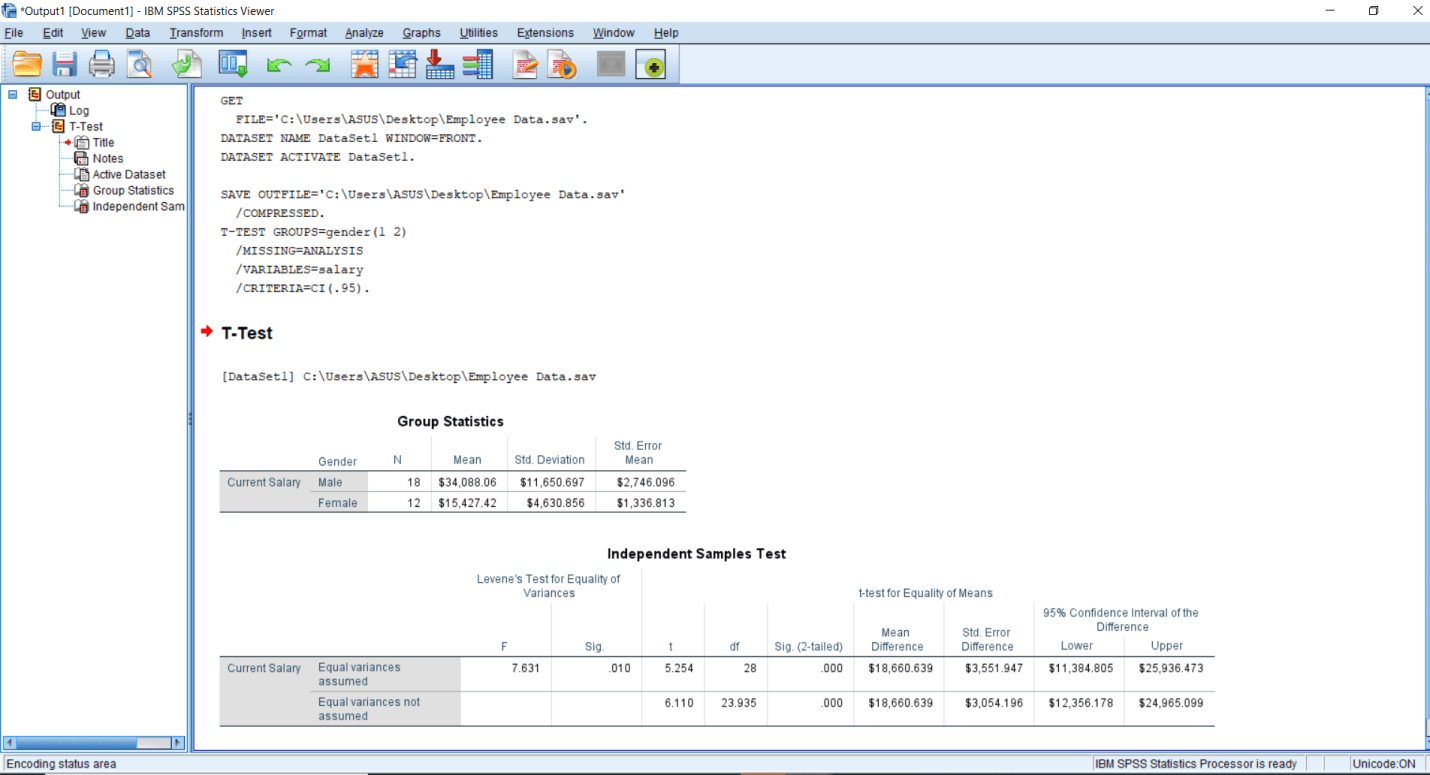
Next TopicOutput of Independent Sample T-test
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








