| |

The Phases of a compiler-Lexical AnalysisA compiler is a software translator program that converts pure high-level language instructions into a machine-understandable format. Generally, we write programs in languages like Python, C, etc... Machines/computers aren't capable of understanding these languages. It can only understand binary language. Writing a program in the binary language is hard. Hence, we use compilers as a medium. Compiling is the second step in a machine's language processing system. It expands the macros given by #define and then gives the pure high-level language code to the compiler. When we write a program in a high-level language, the preprocessor receives the code and performs a few operations like Macro-expansion and file inclusion. When preprocessor directives like #include and #define, the preprocessor includes the specified header files. The compiler then translates the source program into assembly language (a combination of high-level and binary language). It transfers it to the assembler for further encoding into the lowest-level machine code. 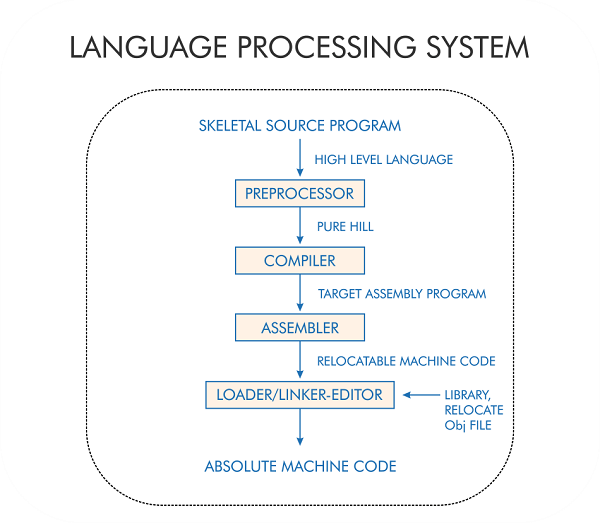
Compilation:The task of a compiler isn't just to translate but also to ensure that the given code is lexically, syntactically, and semantically correct. One of the compiler's major tasks is detecting and displaying error messages. When we write a program and compile it, the compiler takes the whole program at a time, processes the whole code, and displays the list of all error messages and warnings at a time, unlike an interpreter. An interpreter is another translator similar to a compiler. It reads the program line-by-line, and once it finds an error, it stops execution and displays the error message. It works phase-wise, dividing all the tasks it has to complete. Here are all the phases included in the compilation: 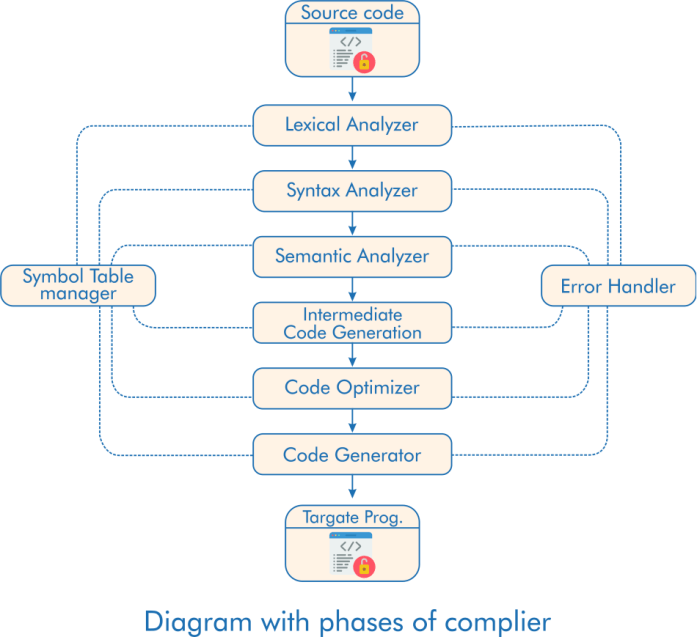
We'll discuss each phase of the compiler in detail. This tutorial explains the first phase-Lexical Analysis. Lexical Analysis:A lexical analyzer is also called a "Scanner". Given the code's statement/ input string, it reads the statement from left to right character-wise. The input to a lexical analyzer is the pure high-level code from the preprocessor. It identifies valid lexemes from the program and returns tokens to the syntax analyzer, one after the other, corresponding to the getNextToken command from the syntax analyzer. 
There are three important terms to grab:
Everything that a lexical analyzer has to do:
The questions here are:
We'll get into the details question-wise. First, the lexical analyzer has to read the input program and break it into tokens. This is achieved by a method called "Input Buffering". Input BufferingFor suppose, assume that the line of code is: The input is stored in buffers to avoid going to secondary memory. Initially, We used a One-buffer scheme: 
Two pointers are used to read and find tokens: *bp (Beginning) and *fp (foreword). *bp is kept at the beginning, and *fp is traversed through the buffer. Once *fp finds a delimiter like white space or semi-colon, the traversed part between *bp and the encountered delimiter is identified as a token. Now, *bp and *fp are set to the succeeding block of the delimiter to continue searching for tokens. 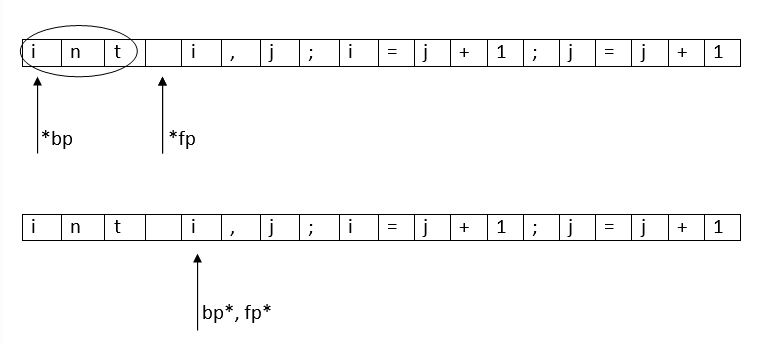
The drawback of One-buffer schema: When the string we want to read is longer than the buffer length, before reading the whole string, the end of the buffer is reached, and the whole buffer has to be reloaded with the rest of the string, which makes identification hard Hence, the Two Buffer scheme is introduced. Here, two buffers of the same size are used. The advantage is that when the first buffer is filled, the second buffer is loaded, and vice versa. We won't lose strings midways. 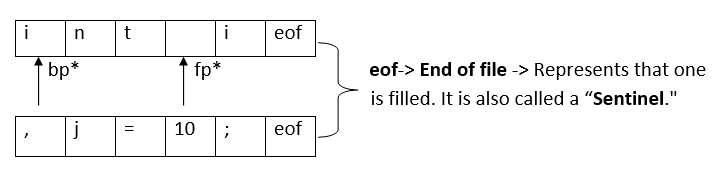
Whenever fp* moves forward, eof checks if it is reaching the end to reload the second buffer. So, this is how an input program is read, and tokens are divided. The next question is how the lexical analyzer can match patterns with lexemes to check the validity of lexemes with tokens. Patterns: The Lexical analyzer has to scan and identify only a finite set of valid tokens/ lexemes from the program for which it uses patterns. Patterns are the to find a valid lexeme from the program. These patterns are specified using "Regular grammar". All the valid tokens are given pre-defined patterns to check the validity of detected lexemes in the program. 1. NumbersA number can be in the form of:
The grammar has to identify all types of numbers: Sample Regular grammar:
2. DelimitersThere are different types of delimiters like white space, newline character, tab space, etc. Sample Regular grammar: 3. IdentifiersThe rules of an identifier are:
Sample Regular grammar: Now, we have detected lexemes and pre-defined patterns for every token. The lexical analyzer needs to recognize and check the validity of every lexeme using these patterns. To recognize and verify the tokens, the lexical analyzer builds Finite Automata for every pattern. Transition diagrams can be built and converted into programs as an intermediate step. Each state in the transition diagram represents a piece of code. Every identified lexeme walks through the Automata. The programs built from Automata can consist of switch statements to keep track of the state of the lexeme. The lexeme is verified to be a valid token if it reaches the final state. Here are some transition diagrams. These are just examples drawn manually, but the compiler's original rules and pattern programs are way more complicated as they have to recognize all types of lexemes whichever way they are used. 1. Identifiers
2. Delimiters
White spaces: When a compiler recognizes a white space or other separating characters like '\t' and '\n', it doesn't send it to the syntax analyzer. It rather starts the whole lexical analysis process from the immediate next token. This is called Stripping the spaces from a program. 3. Numbers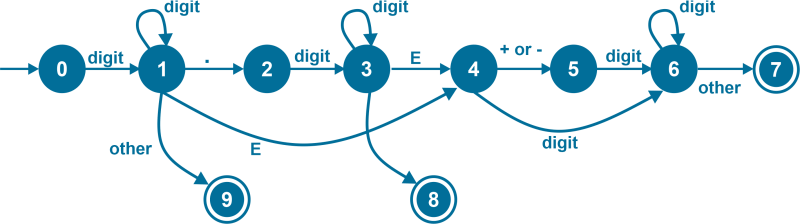
4. KeywordsIdentifies if, else, and for. As mentioned earlier, a keyword's letters are the pattern to identify a keyword. 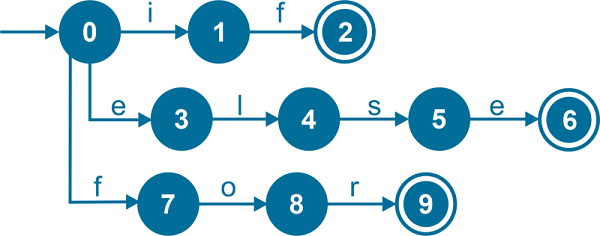
5. Relational OperatorsGE: Greater than or equal to LE: Less than or equal to GT: Greater than LT: Less than EQ: Equals to NE: Not equal to 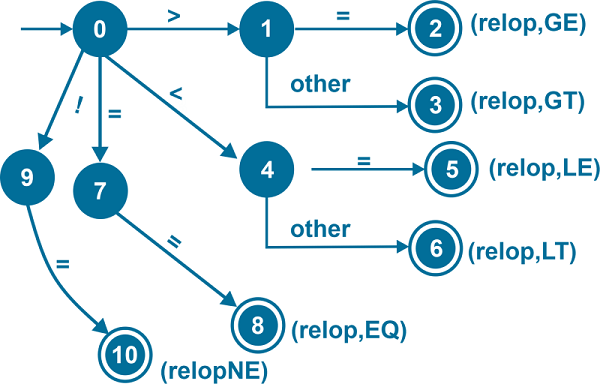
Attributes for Tokens:In a program, many lexemes can correspond to one token. We learned that the lexical analyzer sends a sequence of tokens to the next phase. Still, the rest of the phases need additional information about the lexeme to perform different operations. Both 0 and 1 are identified as Numbers. But, if we send that there is a Number in the program, it isn't sufficient for the Code generator. Hence, the tokens are sent as a pair of <Token name, Attribute value> to the Syntax analyzer. In the case of complex tokens like Identifiers, The Attribute value is a pointer pointing to the identifier's entry in the symbol table to associate more information about the identifier. Now, what exactly does the Lexical Analyzer send the Syntax Analyzer? Let us take an example of grammar for a simple if-else branching statement: Here is the output of the lexical analyzer to the next phase for this snippet:
A lexeme is like an instance of a token, and the attribute column is used to show which lexeme of the token is used. For every lexeme, the 1st and 2nd columns of the above table are sent to the Syntax Analyzer. Lexical Errors:Finding Lexical Errors is one of the tasks of the Lexical Analyzer. But, it is hard for the Lexical Analyzer to determine if a lexeme is faulty without any other components. Suppose it finds: fi (a, b)... For the lexeme fi, the Lexical analyzer can't figure out whether it is a misspelling of if or an undeclared function call identifier. 'fi' makes a valid identifier. Hence, the lexical analyzer doesn't raise any error and validates it as an identifier. Somewhere in the upcoming phases, the error will be identified. For suppose a lexeme isn't matched with any token pattern, the Lexical analyzer enters "Panic mode" and performs some error-recovery actions to repair the input:
Generally, lexical errors occur due to one character. Hence, these transformations serve adequately. The Lexical analyzer attempts to find a valid lexeme in fewer such transformations. This tutorial covered the basic concepts of "Lexical Analysis". After all the processing, the output of a lexical analyzer to the syntax analyzer is a sequence of tokens with attributes. The next article discusses all the basic concepts of the "Syntax analysis" phase. |
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








