| |

Cursor in SQL ServerA cursor in SQL Server is a database object that allows us to retrieve each row at a time and manipulate its data. A cursor is nothing more than a pointer to a row. It's always used in conjunction with a SELECT statement. It is usually a collection of SQL logic that loops through a predetermined number of rows one by one. A simple illustration of the cursor is when we have an extensive database of worker's records and want to calculate each worker's salary after deducting taxes and leaves. The SQL Server cursor's purpose is to update the data row by row, change it, or perform calculations that are not possible when we retrieve all records at once. It's also useful for performing administrative tasks like SQL Server database backups in sequential order. Cursors are mainly used in the development, DBA, and ETL processes. This article explains everything about SQL Server cursor, such as cursor life cycle, why and when the cursor is used, how to implement cursors, its limitations, and how we can replace a cursor. Life Cycle of the cursorWe can describe the life cycle of a cursor into the five different sections as follows: 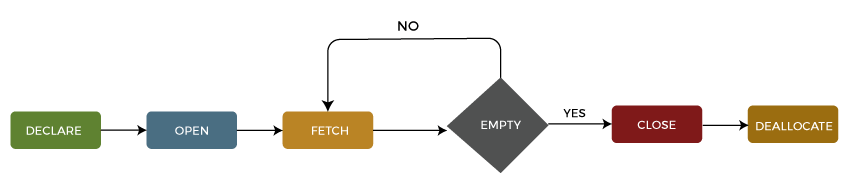
1: Declare CursorThe first step is to declare the cursor using the below SQL statement: We can declare a cursor by specifying its name with the data type CURSOR after the DECLARE keyword. Then, we will write the SELECT statement that defines the output for the cursor. 2: Open CursorIt's a second step in which we open the cursor to store data retrieved from the result set. We can do this by using the below SQL statement: 3: Fetch CursorIt's a third step in which rows can be fetched one by one or in a block to do data manipulation like insert, update, and delete operations on the currently active row in the cursor. We can do this by using the below SQL statement: We can also use the @@FETCHSTATUS function in SQL Server to get the status of the most recent FETCH statement cursor that was executed against the cursor. The FETCH statement was successful when the @@FETCHSTATUS gives zero output. The WHILE statement can be used to retrieve all records from the cursor. The following code explains it more clearly: 4: Close CursorIt's a fourth step in which the cursor should be closed after we finished work with a cursor. We can do this by using the below SQL statement: 5: Deallocate CursorIt is the fifth and final step in which we will erase the cursor definition and release all the system resources associated with the cursor. We can do this by using the below SQL statement: Uses of SQL Server CursorWe know that relational database management systems, including SQL Server, are excellent in handling data on a set of rows called result sets. For example, we have a table product_table that contains the product descriptions. If we want to update the price of the product, then the below 'UPDATE' query will update all records that match the condition in the 'WHERE' clause: Sometimes the application needs to process the rows in a singleton fashion, i.e., on row by row basis rather than the entire result set at once. We can do this process by using cursors in SQL Server. Before using the cursor, we must know that cursors are very bad in performance, so it should always use only when there is no option except the cursor. The cursor uses the same technique as we use loops like FOREACH, FOR, WHILE, DO WHILE to iterate one object at a time in all programming languages. Hence, it could be chosen because it applies the same logic as the programming language's looping process. Types of Cursors in SQL ServerThe following are the different types of cursors in SQL Server listed below:
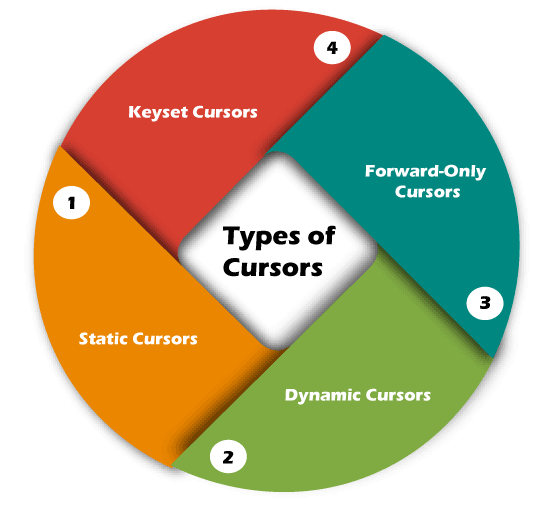
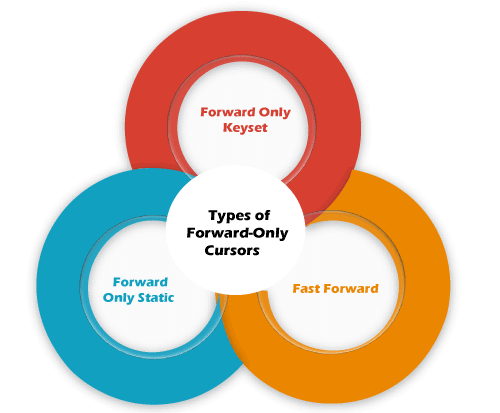
Static CursorsThe result set shown by the static cursor is always the same as when the cursor was first opened. Since the static cursor will store the result in tempdb, they are always read-only. We can use the static cursor to move both forward and backward. In contrast to other cursors, it is slower and consumes more memory. As a result, we can use it only when scrolling is necessary, and other cursors aren't suitable. This cursor shows rows that were removed from the database after it was opened. A static cursor does not represent any INSERT, UPDATE, or DELETE operations (unless the cursor is closed and reopened). Dynamic CursorsThe dynamic cursors are opposite to the static cursors that allow us to perform the data updation, deletion, and insertion operations while the cursor is open. It is scrollable by default. It can detect all changes made to the rows, order, and values in the result set, whether the changes occur inside the cursor or outside the cursor. Outside the cursor, we cannot see the updates until they are committed. Forward-Only CursorsIt is the default and fastest cursor type among all cursors. It is called a forward-only cursor because it moves only forward through the result set. This cursor doesn't support scrolling. It can only retrieve rows from the beginning to the end of the result set. It allows us to perform insert, update, and delete operations. Here, the effect of insert, update and delete operations made by the user that affect rows in the result set are visible as the rows are fetched from the cursor. When the row was fetched, we cannot see the changes made to rows through the cursor. The Forward-Only cursors are three categorize into three types:
Keyset Driven CursorsThis cursor functionality lies between a static and a dynamic cursor regarding its ability to detect changes. It can't always detect changes in the result set's membership and order like a static cursor. It can detect changes in the result set's rows values as like a dynamic cursor. It can only move from the first to last and last to the first row. The order and the membership are fixed whenever this cursor is opened. It is operated by a set of unique identifiers the same as the keys in the keyset. The keyset is determined by all rows that qualified the SELECT statement when the cursor was first opened. It can also detect any changes to the data source, which supports update and delete operations. It is scrollable by default. Implementation of ExampleLet us implement the cursor example in the SQL server. We can do this by first creating a table named "customer" using the below statement: Next, we will insert values into the table. We can execute the below statement to add data into a table: We can verify the data by executing the SELECT statement: After executing the query, we can see the below output where we have eight rows into the table: 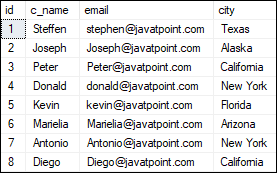
Now, we will create a cursor to display the customer records. The below code snippets explain the all steps of the cursor declaration or creation by putting everything together: After executing a cursor, we will get the below output: 
Limitations of SQL Server CursorA cursor has some limitations so that it should always use only when there is no option except the cursor. These limitations are:
How can we avoid cursors?The main job of cursors is to traverse the table row by row. The easiest way to avoid cursors are given below: Using the SQL while loop The easiest way to avoid the use of a cursor is by using a while loop that allows the inserting of a result set into the temporary table. User-defined functions Sometimes cursors are used to calculate the resultant row set. We can accomplish this by using a user-defined function that meets the requirements. Using Joins Join processes only those columns that meet the specified condition and thus reduces the lines of code that give faster performance than cursors in case huge records need to be processed.
Next TopicIndex in SQL Server
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








