| |

SQL Server COUNT() FunctionThe COUNT() function in SQL Server is a part of the aggregate function used for calculating the total number of rows present in the table. When the result set does not have any rows, it returns NULL. It is usually used with the SELECT statement, and its return type is INT. The COUNT() is a built-in function, which accepts a single parameter that can be a column or valid expression and returns a single result to summarize the input data set. This function does not ignore the NULL values as it considers them too while calculating the query's result. It can also work with the WHERE, GROUP BY, ORDER BY, and HAVING clauses to get the filtered result. SyntaxThe syntax of a COUNT() function in SQL Server are given below: This function contains the following parameters: Expression: It is the required expression that represents the column name whose non-null values will be counted. table_name(s): It indicates the name of a table from where we want to retrieve records. There can be specified more than one table. WHERE conditions: It is an optional clause to define a condition that should satisfy the records to be selected. SQL Server allows us to use the count function in three forms that are listed below:
COUNT() Function ExampleLet us understand how the COUNT() function works in SQL Server with the help of various examples. We are going to take the 'employee_info' table to demonstrate the COUNT function practically. This table contains the following data: 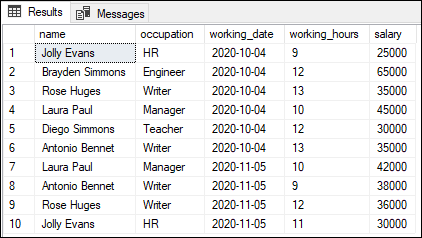
Basic Example of COUNT FunctionThis example explains the very basic use of a COUNT function. It displays the total number of rows present in the table, including null, non-null, and duplicates. Suppose we want to calculate the total number of employees listed in the given table. We can write the query as below: Executing the query will return the below output: 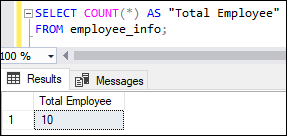
COUNT Function with DISTINCT ClauseThe DISTINCT keyword considered only the unique data of the table. Suppose we want to calculate the total number of unique employees listed in the employee_info table. We can write the query to do the same as below: Executing the query will return the following output that shows only the number of unique employees in the table: 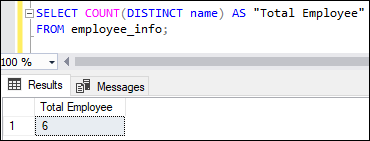
It is another example that uses the COUNT(expression) function to calculate the total number of non-null values in the employee_info table: This statement will count all employees as there are no NULL records found: 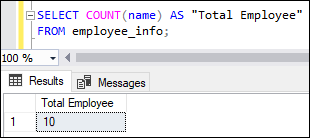
COUNT Function with WHERE ClauseThe WHERE clause is used to filter the records of a table. This example will use the WHERE clause with the COUNT() function to return the total number of employees whose salary is less than 50000 and working hours greater than 9. When we execute the query, we see that seven employee's salary is less than 50000 and working hours are greater than 9: 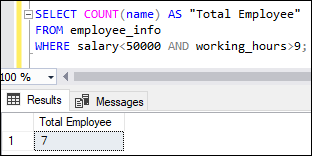
COUNT Function with GROUP BY ClauseThe GROUP BY clause is used to groups rows that have the same values into summary rows. It is very useful in the aggregate function to produce summary reports. The below query will use the COUNT() function to count the total number of employees in each occupation: Executing the query will return the number of employees associated with each occupation: 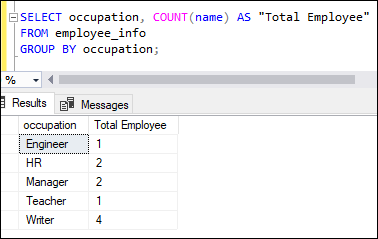
If we try to combine aggregate and non-aggregated columns in a SELECT statement, we will get an error. Here is the error message: 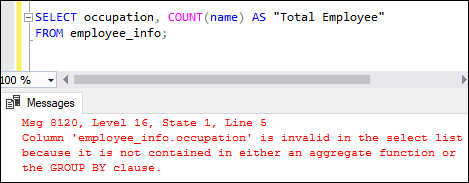
COUNT Function with ORDER BY ClauseThe ORDER BY clause allows us to display the table either in ascending or descending order. The below example will use the COUNT() function with the ORDER BY clause, calculate the total number of employees in each occupation and then sorts the result set based on the number of employees in the ascending order: Executing the statement will display the result in the ascending order of the number of employees: 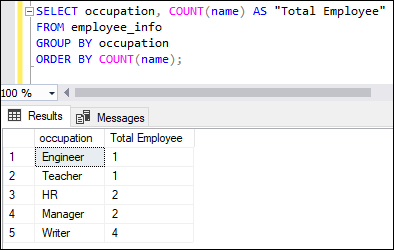
COUNT Function with HAVING ClauseThe HAVING clause is used to filter the grouped rows. We must use the GROUP BY clause with the HAVING clause. This example uses the HAVING clause with the COUNT() function. It counts the number of employees in each occupation and then checks whether the aggregated count is greater than one or not. If this is true, the corresponding records return in the ascending order of a number of employees: Executing the statement will return the number of employees greater than one in each occupation: 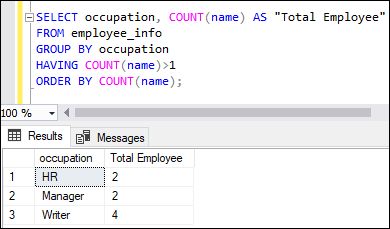
COUNT Function with OVER()The OVER() clause determines which rows from the query are applied to the function, in what order the function evaluates them, and when the function's calculations should restart. The below query provide a cumulative total number of employees for each occupation in the employee_info table and organize the output in ascending order: Executing the query will return the below result: 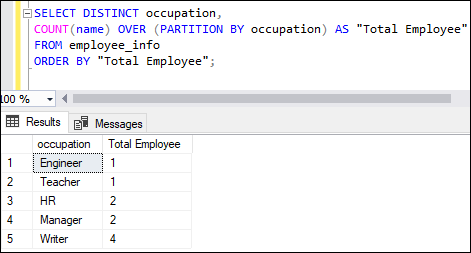
How COUNT() is different from COUNT_BIG() function?The COUNT and COUNT_BIG function in SQL Server essentially do the same thing, i.e., count the number of items present in the table. But sometimes we make a choice between them for the application. In that case, we might prefer which is best for the application based on the data types. The COUNT() function returns the result as an INT, whereas COUNT_BIG() function returns the result as BIGINT data types. Thus, if we have a table with millions of records and we need to get the count of these records, the COUNT() function will give an error, but the COUNT_BIG() function will display such a result. Another major difference between them is while creating an index on the view. COUNT() does not allow the creation of the clustered index on the view. However, we can create clustered index on view when we use the COUNT_BIG() function. ConclusionThis article will explain a complete overview of how and when to use the COUNT() function in SQL Server. We must be careful while using this function as it works with numeric data types only. Here we have discussed various examples based on several use cases of the COUNT function, such as how to get the total number of items present in the table using the WHERE, GROUP BY, HAVING, and OVER clauses.
Next TopicSQL Server Comparison Operator
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








