| |

Index in SQL ServerAn index is one of the important paths to make the performance of SQL Server database high. It makes the querying process fast by providing easy access to rows in data tables, similar to how a book's index will quickly locate information inside that book. If we do not have an index, then it is very tough to locate the specific data. We can have the CREATE INDEX, DROP INDEX, and ALTER INDEX SQL commands for creating new indexes, updating existing indexes, and deleting indexes in SQL Server. This article will give you an overview of SQL Server indexes, including how they're described inside a database and how they can speed up querying. An index is a set of keys made up of single or multiple columns in a table or view. They are stored in a structure (B-tree) that helps SQL Server users quickly and efficiently find the rows or rows associated with the key values. Types of SQL Server IndexesThere are mainly two types of indexes in SQL Server: ClusteredClustered indexes use key values for sorting and storing data rows in tables or view. They are included in the index definition. It always stores the index value in a B-tree structure where the actual data is stored in the leaf node. Since the data rows are stored in one direction, each table can only have a single clustered index. A table stored the rows in sorted order only when the table has a clustered index. We can refer to a clustered table as one that has a clustered index. If a table doesn't have a clustered index, its rows are stored in a heap, which is an unordered structure. The main benefit of a clustered index is the data is physically sorted by the clustered key value in your storage system, and searching for a range of values will be fast. Its main disadvantage is the Last Page Insert Latch Contention that inserts data only at the end of the clustered index. Non-ClusteredThe structure of non-clustered indexes is similar to the clustered index except that the actual data is not contained in the leaf nodes. A non-clustered index has the non-clustered index key values, and each key-value entry contains a reference to the actual data. Depending on how the table data is stored, it could point to a data value in the clustered index or a heap structure. If a row locator is a pointer to the row, it is a heap structure. If a row locator is the clustered index key, it is a clustered table. The main benefit of the non-clustered index is to speed up query performance. Its main disadvantage is the extra overhead needed to maintain the index during DML operations. Creating an Index in SQL ServerWe can create an index in the SQL Server using the following syntax: If you want to create multiple index columns, use the following syntax: Here, index_name is a name of an index, table_name represents the name of the table on which the index is created, and column_name is the column's name on which it is applied. NOTE: Unique indexes maintains the data integrity present in the table and improve the performance by preventing multiple values from being entered into the table.When should indexes be created?We can create an index in the following cases:
When should indexes be avoided?We can avoid an index in the following cases:
ExampleLet us understand use of index in SQL Server with an example. The below statement creates a table named STUDENT in database "javatpoint" as follows: Next, we need to insert some records using the statement as follows: We can verify the table data using the SELECT statement: We will see the below output: 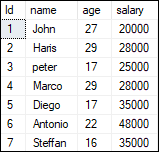
If we want to get the student records whose age is greater than 20, execute the following statement: We will get the below output. 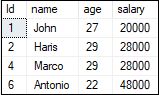
Here the query scans the whole table and returns only four rows whose age is greater than 20. This process will take a long time to retrieve the data, which makes the performance slow. We can overcome this drawback by using the concept of indexing. Now, let us create an index for an age column using the below statement: After executing the above statement, the index is created successfully. If we run the below statement again, then the query does not scan the whole table. Hence, indexing makes the query performance better. How to rename an index?Sometimes our index name is non-meaningful, so it is required to change the name or rename any user-created object in an existing database, including table, index, and column. MS SQL Server can rename or change the index name in mainly two ways:
If we use the system stored procedure to rename an index, we can use the below syntax: We can also use the explicit parameters to rename an indexes: The second way to change the name of an index is by using the SSMS. We can do this by following the below steps:
The below picture explains it more clearly: 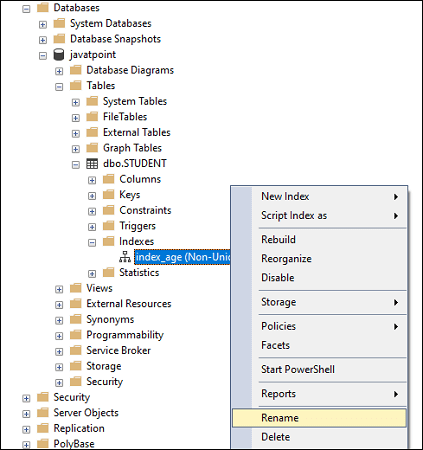
Another way to change the index name is by clicking the index name under the Indexes menu, type the new name, and press enter. See the below image: 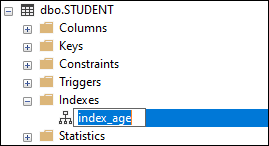
Removing an IndexWe can remove single or multiple indexes from the current database by using the DROP INDEX command. If we want to delete multiple indexes from one or more tables at the same time, we need to define a comma-separated list of index names with the corresponding table names using the below statement: We must ensure the DROP ANY INDEX privilege for deleting an index, or we must be the owner of the index in the current database. Disable IndexesWe can disable the indexes in SQL Server by using the ALTER INDEX statement as follows: If we want to disable all indexes of a table in the current database, we can use the following form of ALTER INDEX statement: Enable IndexesIf we want to enable the disabled index in the SQL Server, we need to rebuild it because we cannot simply enable it. We can use the ALTER INDEX statement or DBCC DBREINDEX command to rebuild an index in SQL Server. We can enable or rebuild the indexes on a table as follows: If we want to enable or rebuild the indexes on a table using the DBCC DBREINDEX statement, the following query will be used: Confirming IndexesWe can verify the different indexes and their uniqueness present in a specific table provided by the user or the server as below: This statement will show us all of the server's indexes, where we can also locate our own tables. Filtering IndexesThe filtered index concept comes into play when our applications just need to query a portion of a table's rows. A filtered index is a non-clustered index with a predicate that lets us select which rows to include in the index. We can use the following syntax to create a filtered index: The main benefits of filtered indexes are:
Next TopicSQL Server Row Number
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








