| |

SQL Server ReplicationReplication in SQL Server is a technology for copying and distributing data and database objects from one database to another, as well as synchronizing the databases to ensure consistency and integrity of data. This technique distributes the selected part of the database, such as tables and views, unlike other replication techniques where the entire database is distributed. It allows using multiple copies of data at different locations simultaneously. It is also used to copy and synchronize data continually, or it can be scheduled to run at pre-defined intervals. Advantages of ReplicationThe following are the main benefits of using replication in SQL Server:
SQL Server Replication ArchitectureThe replication technique in SQL Server is based on the "Publish and Subscribe" concept. The following diagram help to understand each entity or component of replication architecture: 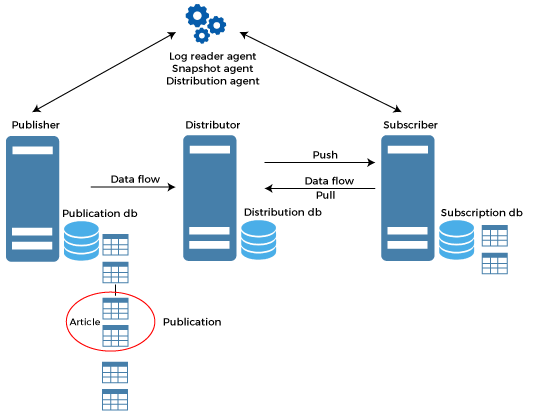
ArticleIt is the basic unit of replication technique that consists of tables, views, functions, and stored procedures. It can be scaled vertically or horizontally by using a filter option. It is possible to create several articles on the same object with some restrictions or limitations. We can use the New Publication Wizard to navigate an article. This wizard enables us to view the article's attributes and set permissions as needed. We can also set the properties at the time of publication creation, but these are simply read-only permissions. If we want to change the property of a publication after it is created, we must generate a new replication snapshot. If the publication contains one or more subscriptions, the modification requires the re-initialization of all subscriptions independently. We can use the following SQL statements to list all articles that are published: If we want to fetch the article details in transactional or merge replication in a published database, we need to execute the below SQL statement: If we want to fetch the article information in a listed publisher, use the following SQL statement: PublicationIt's a logical collection of articles with a database that exists on a publisher. The publication enables us to define and configure article properties at a higher level so that the properties being inherited to all articles in the group. It indicates the final set of entities for a database. It is important for articles to distribute them independently. Publisher databaseIt is a database that holds a list of objects that have been identified as replication articles. It can have one or more publications where each publisher creates many internal replication stored procedures together to define a data propagation method. PublisherIt indicates the source database where replication starts and makes data available for other servers configured for use in the replication process. DistributorIt is a storehouse for replication data associated with one or more publishers. Sometimes, the distributor acts as the publisher and distributor both. It is called "local distributer" in the context of the SQL Server replication, where a single server instance runs both publisher and distributor. It is called a "remote distributer" when distributed on a different server. Each publisher is associated with a distribution database and a distributor. It also identifies and stores replication status data and publication metadata. It sometimes acts as a queue for data moving from publisher to subscriber. It also tells subscribers who have subscribed to a publication that an article has changed based on the replication type. Distribution databasesThe article detail, replication metadata, and data are all stored in this database. A distributor should have at least one distribution database, and in some cases, it may have multiple databases. We make sure that all publications defined by a single Publisher are distributed using the same database. We can use the following statement to check whether a server is a distributor or not: The below command checks whether the distribution database is installed or not: The following command checks whether the publisher uses this distributer or not: The following command used for fetching the Distributor and Distribution database properties: SubscriberA subscriber is a database instance that receives replication data from a publication. Each subscriber can receive data from one or more publishers and publications. When there is only one subscriber, a single-subscriber model is implemented. When many subscribers are linked to a single publication, a multi-subscriber technique is implemented. Depending on the replication design and model, the subscriber can also send data modifications back to the publisher or republish the data to other subscribers. SubscriptionsThe term "subscription" refers to a request for a copy of a publication to be sent to the Subscriber. The subscription specifies the publication data that must be obtained, as well as where and when it will be delivered. We can categorize the subscriptions into two forms Push and pull.
Subscription databaseIt refers to a target database in the SQL Server replication technique. Replication AgentsAgents are the pre-defined set of standalone programs and events for performing a task associated with the data. They are configured to execute as scheduled jobs under SQL Server Agent by default. We can also start it from the command line or by an application using Replication Management Objects (RMO). We use the Replication Monitor and SQL Server Management Studio for monitoring and managing replication agents. We can categorize the replication agents into five types as shown in the diagram: 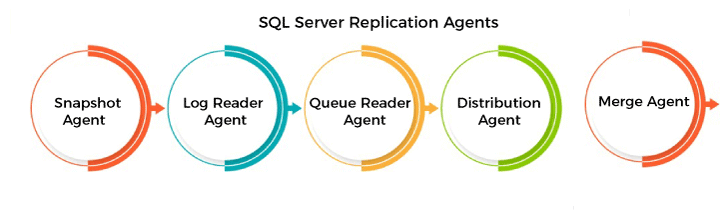
Snapshot AgentIt's an executable program that helps in the creation of snapshot files, including schema, published articles, snapshots files, records, and database objects. It is used with all types of replication technology because it supplies the required data set for the initial data synchronization of the publication and subscription databases. The data is normally saved in a snapshot folder, and the synchronized jobs are kept in a distributed database. Distribution AgentIt is used only with transactional and snapshot replication. The initial replication snapshot is applied to the subscription database via this agent, and data updates are tracked and recorded in the distribution database before being applied to the subscription database. It can be used by the distributor to push subscriptions or by the subscriber to pull subscriptions. Log Reader AgentIt is only used in conjunction with transactional replication, which moves transactions from the publications database transaction log to the distribution database. Each database has its own Log Reader Agent, which runs on the distributor and can communicate with the Publisher. Merge AgentIt is used with the merge replication model. It, by default, uploads the subscriber modifications to the publisher and then downloads publisher updates to the subscriber. It is associated with each subscription, which communicates with both the publisher and the subscriber to keep them up to date. It runs at the distributor for push subscriptions and at the subscriber for the pull subscriptions. The synchronization is bi-directional in this case. A set of triggers that support the entire process handles data conflicts. Queue Reader AgentThe transactional replication used this agent along with the queued update option. Queue reader agent always runs at the distributer, and if any changes are found at the subscriber, it transfers them to the publisher. There is only one instance of Queue Reader Agent to handle all publications and publishers for an authorized distribution database. Replication TypesSQL Server categorizes the replication technique into three main types, which are depicted in the following diagram: 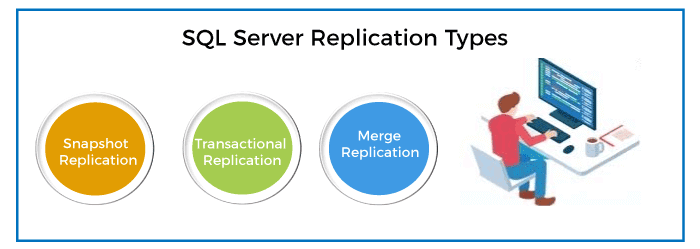
Snapshot ReplicationSnapshot replication is used for copying and distributing data exactly as it appeared when the database snapshot was taken. We can use this replication type when data is not modified frequently, or having a database replica older than the master database isn't important, or when a high number of changes are done in a short period of time. This method does not log the changes. For example, suppose a single product company changes their items price once or twice a year. In that case, it is highly suggested to replicate the entire snapshot of data in this scenario. 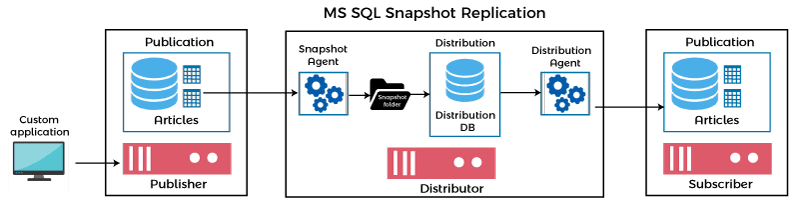
How does snapshot replication work? We can understand how snapshot replication works using the following points:
In simple terms, snapshot replication does just what its name implies. Here the publisher takes a picture of the full database and shares it with subscribers. We use it in the following two main scenarios:
Transactional Replication It provides a more flexible solution to databases that changes frequently. The replication agent keeps an eye on the publisher for database changes and sends them to the subscribers. These transmissions can be scheduled either periodically or on a regular basis. This makes it more complex in comparison to the snapshot replication. A snapshot is applied to the subscriber at the start of the transaction plication process, and then data is continually sent from a master database to a database replica after it is altered. One-way replication is commonly used with transactional replication. 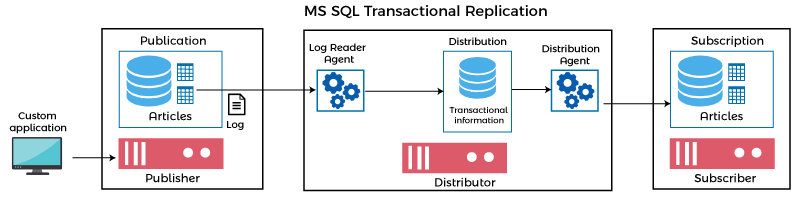
Merge Replication It is a bidirectional replication used in server-to-client environments for synchronizing data on several database servers when they can't be connected continuously. After establishing the connection, merge replication agents detect modifications and changes databases for synchronization and update their state. It is similar to transactional replication, but here publishers and subscribers make changes to the database individually. If there are any conflicts in the modifications, the agent checks the appropriate data using a pre-defined conflict resolution procedure. It is used rarely because it is the most complex among all replication types. 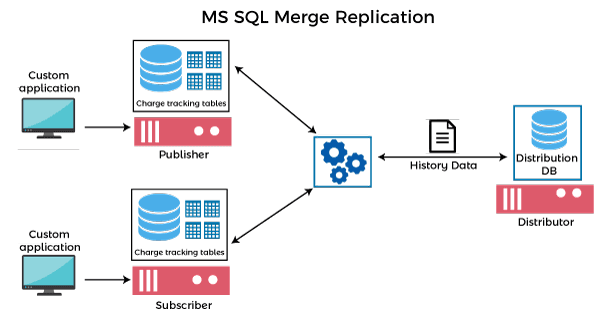
Next TopicSQL Server Transaction
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








