| |

SQL Server TransactionA transaction in SQL Server is a sequential group of statements or queries to perform single or multiple tasks in a database. Each transaction may have single read, write, update, or delete operations or a combination of all these operations. Each transaction must happen two things in SQL Server:
A transaction cannot be successful until all of the operations in the set are completed. It means that if any argument fails, the transaction operation will fail. Each transaction begins with the first executable SQL statement and ends when it finds a commit or rollback, either explicitly or implicitly. It uses the COMMIT or ROLLBACK statements explicitly, as well as implicitly when a DDL statement is used. The below pictorial representation explains the transaction process: 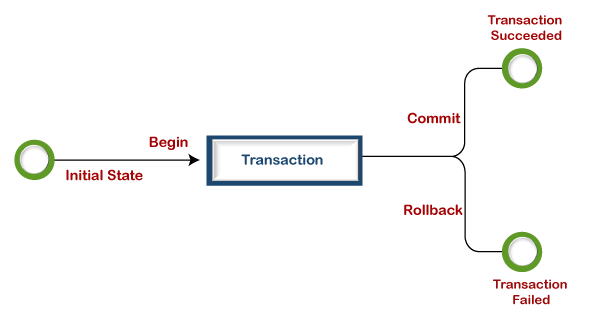
The following example will explain the concept of a transaction: This example will use the banking database system to explain the concept of a transaction. Suppose a bank customer wants to withdraw money from their account by using ATM mode. The ATM can achieve this operation in the three steps:
The basic principle behind transactions is that if one of the statements returns an error, the entire set of changes is rolled back to ensure data integrity. And if the transactions become successful, all changes will be permanent on the database. Hence, if there is a power outage or other issues when withdrawing money from an ATM, transactions guarantee that our balance remains consistent. A transaction statement best performs these operations because the transaction's four key properties make all operations more accurate and consistent. The transaction's four properties are referred to as ACID. Transaction PropertiesThe transaction properties are referred to as ACID (Atomicity, Consistency, Isolation, Durability) property, which are discussing in detail below: 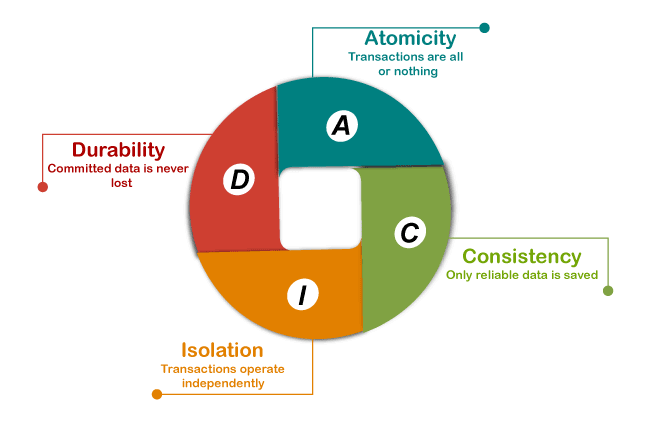
Atomicity: This property ensures that all statements or operations included in the transaction must be performed successfully. Otherwise, the whole transaction will be aborted, and all operations are rolled back into their previous state when any operation is failed. Consistency: This property ensures that the database changes state only when a transaction will be committed successfully. It is also responsible for protecting data from crashes. Isolation: This property guarantees that all transactions are isolated from other transactions, meaning each operation in the transaction is operated independently. It also ensures that statements are transparent to each other. Durability: This property guarantees that the result of committed transactions persists in the database permanently even if the system crashes or failed. Transaction Modes in SQL ServerThere are three different transaction modes that SQL Server can use: Auto-commit Transaction Mode: It is the SQL Server's default transaction mode. It will evaluate each SQL statement as a transaction, and the results are committed or rolled back accordingly. Thus the successful statements are immediately committed, while the failed statements are immediately rolled back. Implicit Transaction Mode. This mode allows SQL Server to begin the implicit transaction for each DML statement, but it explicitly requires the use of commit or rollback commands at the end of the statements. Explicit Transaction Mode: This mode is defined by the user that allows us to identify a transaction's beginning and ending points exactly. It will automatically abort in case of a fatal error. Transaction ControlThe following are the commands used to control transactions:
NOTE: We can use only DML statements (INSERT, UPDATE, and DELETE) for Transaction Control Language commands. We cannot use them while creating or dropping tables because these operations are committed to the database automatically.Transaction StateIt indicates how transactions go during their lifetime. It describes the current state of the transaction as well as how the transaction will be processed in the future. These states define the rules that determine whether a transaction commits or aborts. 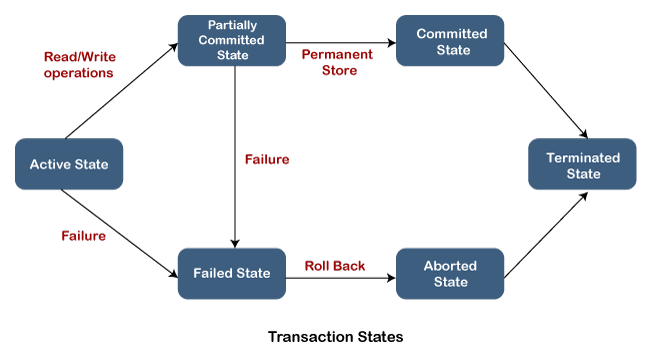
Let us describe each transaction states in SQL Server: Active State: The transaction is in an active state while the transaction's instructions are being executed. It changes to the "partially committed state" if all "read and write" operations are completed without errors. If any instruction fails, it changes to the "failed state." Partially Committed: When all the read and write operations are completed, the change is made to the main memory or local buffer. The state would go to "committed state" if the changes are made permanent on the database. Otherwise, it goes to the "failed state". Failed State: A transaction goes to the failed state when any transaction's instruction fails or a permanent modification on the database fails. Aborted State: The transaction moves from a "failed state" to an "aborted state" when any kind of failure occurs. The changes are removed or rolled back because these changes are only made to the local buffer or main memory in previous states. Committed State: A transaction is complete and goes into this state when the changes are made permanent on the database and terminated in the "terminated state". Terminated State: If there is no rollback and the transaction is in the "committed state," the system is consistent and ready for a new transaction while the old one is terminated. Implementation of Transaction in SQL ServerLet us take some examples to understand how we can implement the transaction in SQL Server. Here we will use the "Product" table to demonstrate all transaction states. The following SQL scripts create the Product table in the selected database: Next, execute the below scripts to insert data into this table: Execute the SELECT statement to verify the data: 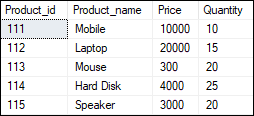
Example of COMMIT TransactionIt's a good idea to divide the SQL Statements used in the transaction into multiple logical parts. And then, we can decide whether to commit or roll back the data. The following steps illustrate to create a transaction:
Below are the commands that explain the COMMIT operations in SQL Server: If no error is found, we will see the following output where each SQL statement of transaction executed independently: 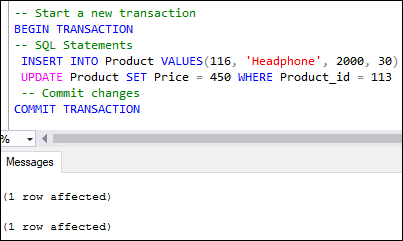
The INSERT and UPDATE statements cannot be rolled back after the transaction has been committed. When we verify the table after commit operation, we will see the following data: 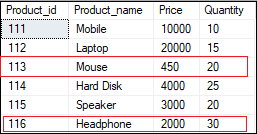
Example of ROLLBACK TransactionWe will use the ROLLBACK command to undo any transactions that haven't been saved to the database yet and return to the point where the transaction began. The following example explains the ROLLBACK operation in SQL Server: Once we execute the above transaction, we can see that it will be executed successfully. However, it will not affect any changes in the database because until we do not execute the COMMIT or ROLLBACK statement, the changes cannot become permanent. Therefore, we have the option of using the ROLLBACK transaction command to roll back all database operations. Here is the full transaction statement: Use of @@Error Global variable in transactions:This variable is used to check whether there is an error or not. The below example explains its concept. Here we will first start the transaction using the BEGIN command and then write two insert statements. Next, we will use the global system variable @@ERROR in the IF statement to check an error. If the value is greater than 0, it means there is some error. Now, the transaction is rollback; otherwise, the transaction is committed. When the above transaction is executed, we will notice that it's been rolled back. It is due to our attempt to insert duplicate a value in the Primary key column. Auto Rollback TransactionMost of the transactions contain more than one query. While executing the transaction, if any of the SQL statements produce an error, no modifications occur in the database, and the remaining statements are not executed. This concept is known as an Auto Rollback Transaction in SQL Server. Let's use a simple example to demonstrate this process. This transaction produces the following output: 
In this output, we can see that the insert statement was executed successfully. However, executing the update statement found an error due to the data type conversion issue. In this case, the SQL Server does not allow any changes in the database, which means the insert operation does not add any value, and the select statement is not executed. Savepoint in TransactionsThe savepoint inserts a special mark into a transaction that allows us to rollbacks all changes executed after savepoint. It is also used to roll back any specific portion of the transaction rather than the entire transaction. We can define it by using the SAVE TRANSACTION sp_name statement. The following example will explain the use of savepoint in transactions that commits the insert statement and rollbacks the delete statement. See the below result where we can see the product id 116 is deleted, and 117 is inserted in the first output. However, in the second output, the deletion operation is rolled back because of the savepoint. 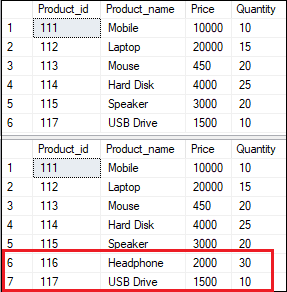
How to release a savepoint in a transaction? Release savepoint is used to remove the named savepoint from the current transaction without reverting the results of queries executed after the savepoint. MySQL has this command, but SQL Server does not provide any command to release a savepoint. Instead, they are automatically released at the end of a commit or rollback transaction, so we do not have to worry about them intermediately. Implicit Transaction in SQL ServerWe can define an implicit transaction by enabling the IMPLICIT_TRANSACTIONS option. The following example will explain this concept easily: In this transaction, we have used two options @@OPTION and @@TRANCOUNT. The @@OPTOPN provides the information regarding current SET options, and @@TRANCOUNT provides the BEGIN TRANSACTION statement in the current session. Now, executing the transaction will return the below output: 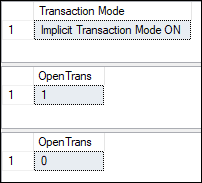
Explicit Transaction in SQL ServerAn explicit transaction must be defined through the BEGIN TRANSACTION command because it identifies the starting point of the explicit transaction. We can define the explicit transaction in SQL Server as below: In the syntax, the trans_name option indicates a unique name of a transaction. The @trans_name_var indicates a user-defined variable that stores the transaction name. Finally, the MARK option allows us to mark a specific transaction in the log file. The explicit transaction through the BEGIN TRANSACTION command acquired a lock depending on the isolation level of the transaction-related resources. It helps to reduce lock issues. See the below example: Here is the output: 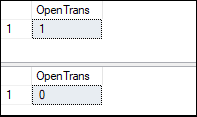
Marked Transaction in SQL ServerThe marked transaction is used to add a description to a specific transaction in the log files. We can use it as a recovery point in place of a date and time when restoring a database to a previous state. We must know that the mark is added in the log files only when the marked transaction modifies the database. We can understand its concept using the following example. Suppose we have modified the database accidently, and we don't know the exact moment of the data alteration; in that case, data recovery can take a long time. However, if we use the marked transactions, it can be a useful tool for determining the exact timing of data alterations. The following syntax illustrates the marked transaction in SQL Server: Here we must define the name of the transaction and then add WITH MARK option. In the below example, we are going to delete records and add the mark in the log file: The logmarkhistory table is included in the msdb database and stores information regarding each marked transaction that has been committed. Execute the below statement to get the details from the logmarkhistory table: Named Transaction in SQL ServerWe can also provide a name for our transaction in SQL Server. It is always recommended to use the named transaction when working with many transactions in a single query. The below example explains how to rename a transaction: Here is the output: 
Conclusion This article will give a complete overview of the transaction in SQL Server statements. Transactions are helpful in relational database systems because they ensure database integrity.
Next TopicSQL Server Constraints
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








