| |

MySQL Delete Duplicate RecordsMySQL is a database application that stores data in tables in the form of rows and columns. This database application can store duplicate records in the table, which can impact the database's performance in MySQL. However, data duplication occurs due to various reasons and removing the duplicate values in the table is an important task while working with a database in MySQL. Generally, it is good to always use unique constraints on a table to store data that prevent having duplicate rows. In this article, we are going to learn how we can remove duplicate records from the MySQL database. Let us understand it with the help of an example. Suppose we have a table named "student_contacts" that contains many duplicate records: 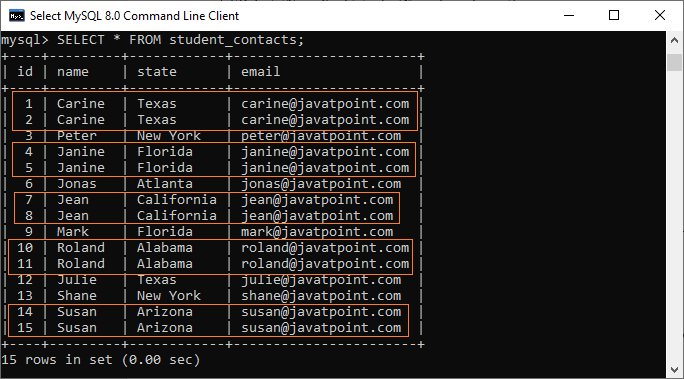
Now, we will see how to delete duplicate records from the table. MySQL can remove duplicates record mainly in three ways. 1. Delete Duplicate Record Using Delete JoinWe can use the DELETE JOIN statement in MySQL that allows us to remove duplicate records quickly. The following statement removes duplicate rows from the table and keeps the greatest id: This query references the student_contacts table twice. Therefore, we will use table alias S1 and S2. After executing the statement, we will get the following output: 
The above output indicates that five records have been deleted from the table. We can verify this by executing the below query that returns the duplicates records of the table. It will return the output as follows that shows an empty set. It means duplicate records have been successfully removed from the table. 
We can also verify it by using the SELECT statement. In the below image, we can see that there are no duplicate records available in the table. 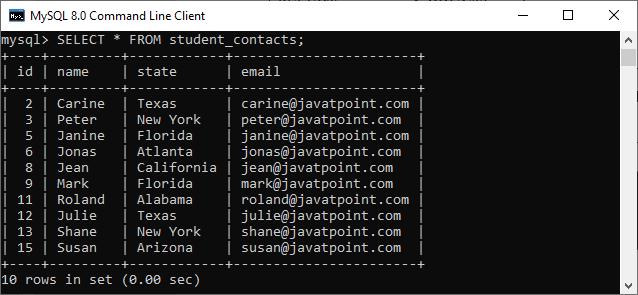
Suppose we want to remove duplicate records and keep the lowest id in the table. In that case, we will use the statement as follows: It is to note that we need to create a table again containing duplicate records before executing the query. After executing the statement, we will get the following output: 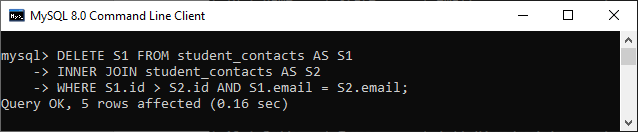
We can also verify it by using the SELECT statement. In the below image, we can see that the duplicate records with higher id have been removed. 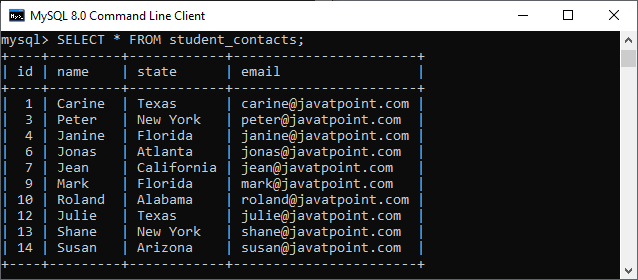
2. Delete Duplicate Record Using the ROW_NUMBER() FunctionT ROW_NUMBER() function returns the sequential number for each row within its partition, which starts from 1 to the number of rows present in the partition. We can use the below statement that assigns a sequential number to each row using the ROW_NUMBER() function. If this query finds the name column of the table duplicate, it will assign the row number greater than one. After execution, we will get the output as below: 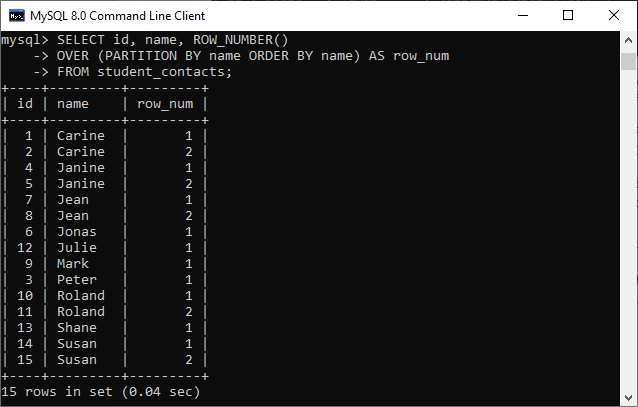
If you want to get only duplicate id rows, use the below statement: This statement reruns the following output: 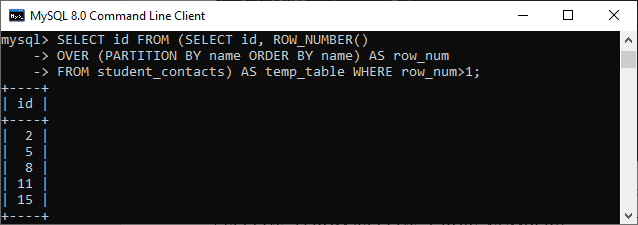
We can now remove the duplicate records from the student_contacts table with the help of the DELETE statement and a subquery in the WHERE clause. See the below statement: After execution, we will get the output as below image where we can see that this statement has been removed five records from the table. You can verify whether duplicate rows are removed or not using the SELECT statement. 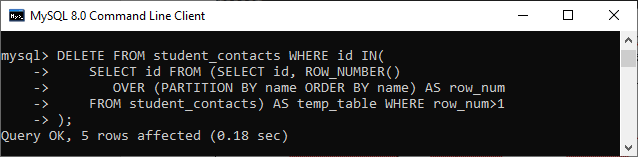
3. DELETE Duplicate Rows Using Intermediate TableWe can also remove duplicate records from the table using an intermediate table. The following are the points to delete duplicate records with the help of an intermediate table: 1. Create a new table with the same structure as the original table that we will use to remove duplicate records. 2. Insert unique (distinct) rows of the original table into the newly created table. 3. Delete the original table and rename the newly created table same as the original table. Let us understand the above steps with the help of the below queries that deletes the duplicates records using an intermediate table: Step 1: Step 2: Step 3: See the below image to understand the above steps. 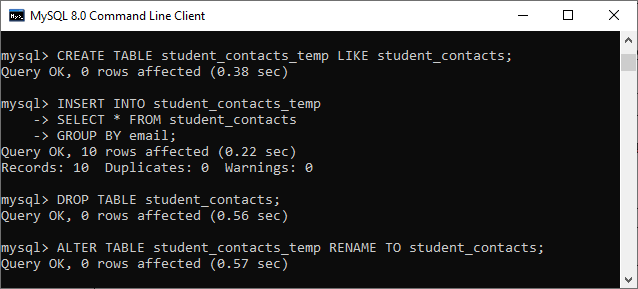
Next TopicMySQL Select Random Records
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








