| |

Spring Data JPASpring Data is a high-level Spring Source project. Its purpose is to unify and easy access to the different kinds of persistence stores, both relational database systems, and NoSQL data stores. When we implement a new application, we should focus on the business logic instead of technical complexity and boilerplate code. That's why the Java Persistent API (JPA) specification and Spring Data JPA are extremely popular. Spring Data JPA adds a layer on the top of JPA. It means, Spring Data JPA uses all features defined by JPA specification, especially the entity, association mappings, and JPA's query capabilities. Spring Data JPA adds its own features such as the no-code implementation of the repository pattern and the creation of database queries from the method name. Spring Data JPASpring Data JPA handles most of the complexity of JDBC-based database access and ORM (Object Relational Mapping). It reduces the boilerplate code required by JPA. It makes the implementation of your persistence layer easier and faster. Spring Data JPA aims to improve the implementation of data access layers by reducing the effort to the amount that is needed. Spring Data JPA FeaturesThere are three main features of Spring Data JPA are as follows:
In the above example, we extend the CrudRepository that uses two generics: Employee and Long. The Employee is the entity that is to be managed, and Long is the data type of primary key Spring internally generates a JPQL (Java Persistence Query Language) query based on the method name. The query is derived from the method signature. It sets the bind parameter value, execute the query, and returns the result. There are some other features are as follows:
Spring Data RepositorySpring Data JPA provides three repositories are as follows:
Spring Boot Starter Data JPASpring Boot provides spring-boot-starter-data-jpa dependency to connect Spring application with relational database efficiently. The spring-boot-starter-data-jpa internally uses the spring-boot-jpa dependency (since Spring Boot version 1.5.3). The databases are designed with tables/relations. Earlier approaches (JDBC) involved writing SQL queries. In the JPA, we will store the data from objects into table and vice-versa. However, JPA evolved as a result of a different thought process. Before JPA, ORM was the term more commonly used to refer to these frameworks. It is the reason Hibernate is called the ORM framework. JPA allows us to map application classes to table in the database.
Hibernate vs. JPAHibernate is the implementation of JPA. It is the most popular ORM framework, while JPA is an API that defines the specification. Hibernate understands the mapping that we add between objects and tables. It ensures that data is retrieved/ stored from the database based on the mapping. It also provides additional features on the top of the JPA. Spring Boot JPA ExampleIn this example, we will use spring-boot-starter-data-jpa dependency to create a connection with the H2 database. Step 1: Open spring Initializr https://start.spring.io/. Step 2: Provide the Group name. We have provided com.javatpoint. Step 3: Provide the Artifact Id. We have provided spring-boot-jpa-example. Step 4: Add the dependencies: Spring Web, Spring Data JPA, and H2 Database. Step 5: Click on the Generate button. When we click on the Generate button, it wraps the project in Jar file and downloads it to the local system. 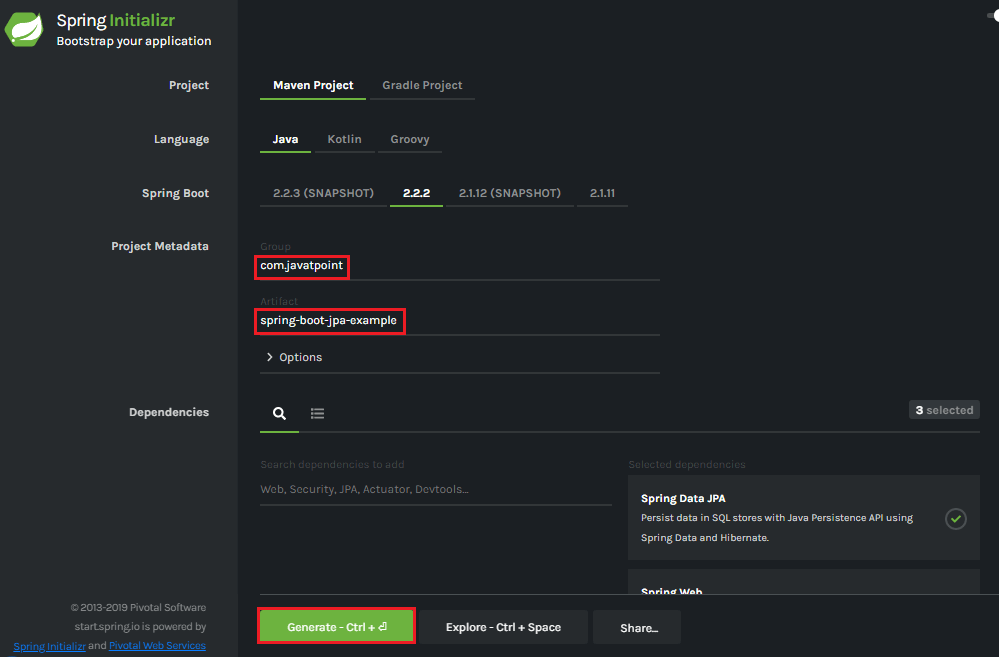
Step 6: Extract the Jar file and paste it into the STS workspace. Step 7: Import the project folder into STS. File -> Import -> Existing Maven Projects -> Browse -> Select the folder spring-boot-jpa-example -> Finish It takes some time to import. Step 8: Create a package with the name com.javatpoint.controller in the folder src/main/java. Step 9: Create a Controller class with the name ControllerDemo in the package com.javatpoint.controller. ControllerDemo.java Step 10: Create another package with the name com.javatpoint.model in the folder src/main/java. Step 11: Create a class with the name User in the package com.javatpoint.model. User.java Now we need to Configure the H2 database. Step 12: Open the application.properties file and configure the following things: port, enable the H2 console, datasource, and URL. application.properties Step 13: Create a SQL file in the folder src/main/resources. Right-click on the folder src/main/resources -> New -> File -> Provide the File name -> Finish We have provided the file name data.sql and insert the following data into it. data.sql Step 14: Create a folder with the name webapp in the src folder. Step 15: Create a JSP file with the name that we have returned in the ControllerDemo. In the ControllerDemo.java, we have returned home.jsp. home.jsp Step 16: Run the SpringBootJpaExampleApplication.java file. We can see in the console that our application is successfully running on port 8085. 
Step 17: Open the browser and invoke the URL http://localhost:8085/h2-console/. It shows the Driver Class, JDBC URL that we have configured in the application.properties file, and the default User Name sa. 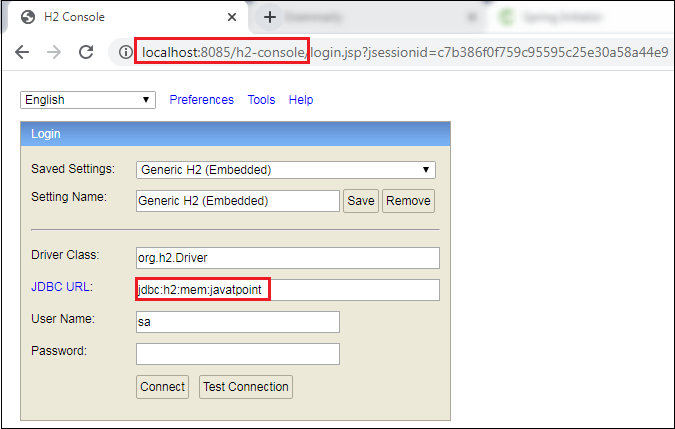
We can also test the connection by clicking on the Test Connection button. If the connection is successful, it shows a message Test Successful. Step 18: Click on the Connect button. It shows the structure of the table userdata that we have defined in the User.java. 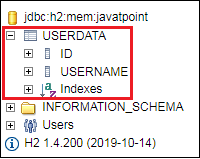
Step 19: Execute the following query to see the data that we have inserted in the data.sql file. 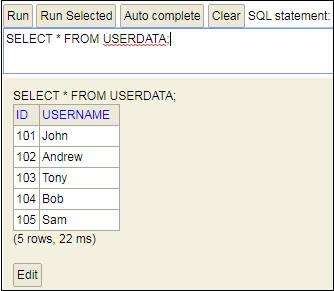
Next TopicSpring Boot Starter Actuator
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








