| |

Cache MemoryThe data or contents of the main memory that are used frequently by CPU are stored in the cache memory so that the processor can easily access that data in a shorter time. Whenever the CPU needs to access memory, it first checks the cache memory. If the data is not found in cache memory, then the CPU moves into the main memory. Cache memory is placed between the CPU and the main memory. The block diagram for a cache memory can be represented as: 
The cache is the fastest component in the memory hierarchy and approaches the speed of CPU components. Cache memory is organised as distinct set of blocks where each set contains a small fixed number of blocks. 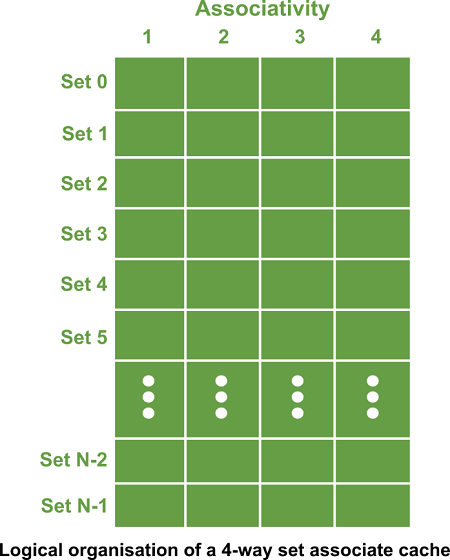
As shown in the above sets are represented by the rows. The example contains N sets and each set contains four blocks. Whenever an access is made to cache, the cache controller does not search the entire cache in order to look for a match. Rather, the controller maps the address to a particular set of the cache and therefore searches only the set for a match. If a required block is not found in that set, the block is not present in the cache and cache controller does not search it further. This kind of cache organisation is called set associative because the cache is divided into distinct sets of blocks. As each set contains four blocks the cache is said to be four way set associative. The basic operation of a cache memory is as follows:
Levels of memory:Level 1 It is a type of memory in which data is stored and accepted that are immediately stored in CPU. Most commonly used register is accumulator, Program counter, address register etc. Level 2 It is the fastest memory which has faster access time where data is temporarily stored for faster access. Level 3 It is memory on which computer works currently. It is small in size and once power is off data no longer stays in this memory. Level 4 It is external memory which is not as fast as main memory but data stays permanently in this memory. Cache Mapping:There are three different types of mapping used for the purpose of cache memory which are as follows:
Direct Mapping -In direct mapping, the cache consists of normal high-speed random-access memory. Each location in the cache holds the data, at a specific address in the cache. This address is given by the lower significant bits of the main memory address. This enables the block to be selected directly from the lower significant bit of the memory address. The remaining higher significant bits of the address are stored in the cache with the data to complete the identification of the cached data. 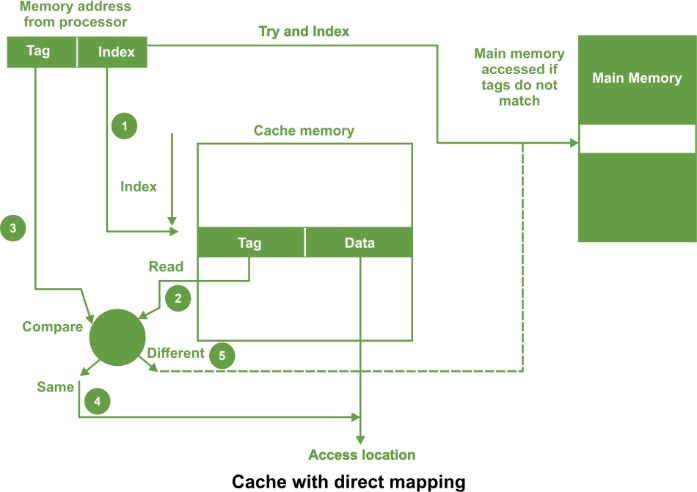
As shown in the above figure, the address from processor is divided into two field a tag and an index. The tag consists of the higher significant bits of the address and these bits are stored with the data in cache. The index consists of the lower significant b of the address. Whenever the memory is referenced, the following sequence of events occurs
For a memory read operation, the word is then transferred into the cache. It is possible to pass the information to the cache and the process simultaneously. In direct mapped cache, there can also be a line consisting of more than one word as shown in the following figure 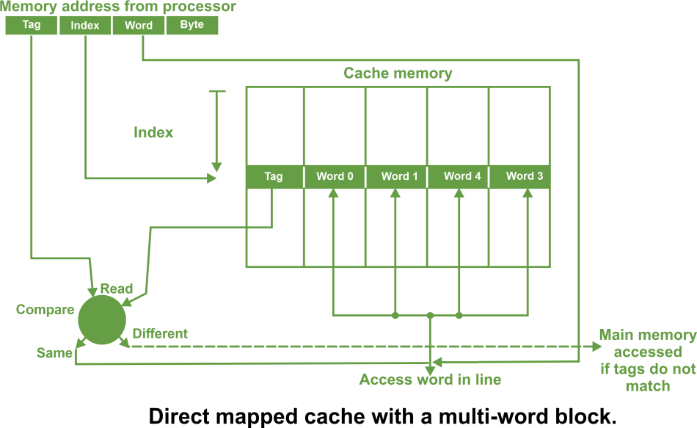
In such a case, the main memory address consists of a tag, an index and a word within a line. All the words within a line in the cache have the same stored tag The index part in the address is used to access the cache and the stored tag is compared with required tag address. For a read operation, if the tags are same, the word within the block is selected for transfer to the processor. If tags are not same, the block containing the required word is first transferred to the cache. In direct mapping, the corresponding blocks with the same index in the main memory will map into the same block in the cache, and hence only blocks with different indices can be in the cache at the same time. It is important that all words in the cache must have different indices. The tags may be the same or different. Set Associative Mapping -In set associative mapping a cache is divided into a set of blocks. The number of blocks in a set is known as associativity or set size. Each block in each set has a stored tag. This tag together with index completely identify the block. Thus, set associative mapping allows a limited number of blocks, with the same index and different tags. An example of four way set associative cache having four blocks in each set is shown in the following figure 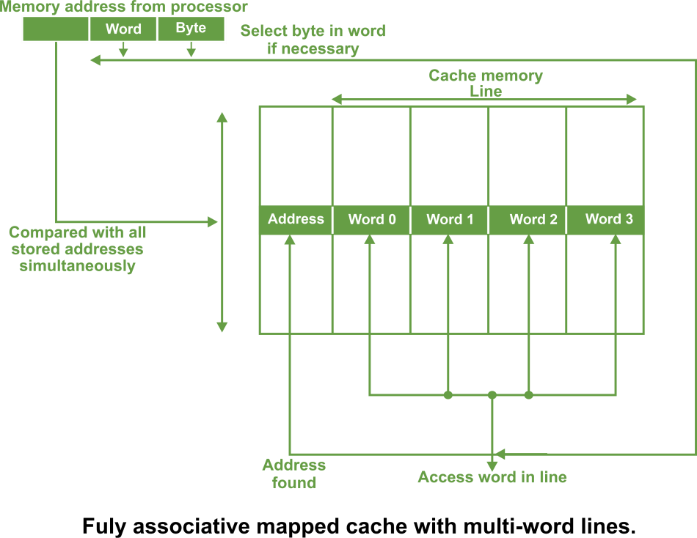
In this type of cache, the following steps are used to access the data from a cache:
The tag address bits are always chosen to be the most significant bits of the full address, the block address bits are the next significant bits and the word/byte address bits are the least significant bits. The number of comparators required in the set associative cache is given by the number of blocks in a set. The set can be selected quickly and all the blocks of the set can be read out simultaneously with the tags before waiting for the tag comparisons to be made. After a tag has been identified, the corresponding block can be selected. Fully associative mappingIn fully associative type of cache memory, each location in cache stores both memory address as well as data. 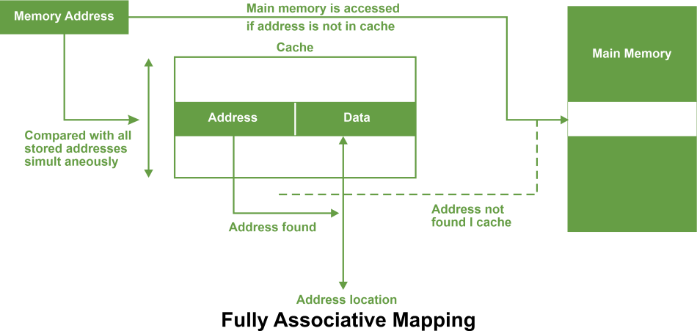
Whenever a data is requested, the incoming memory address a simultaneously compared with all stored addresses using the internal logic the associative memory. If a match is found, the corresponding is read out. Otherwise, the main memory is accessed if address is not found in cache. This method is known as fully associative mapping approach because cached data is related to the main memory by storing both memory address and data in the cache. In all organisations, data can be more than one word as shown in the following figure. 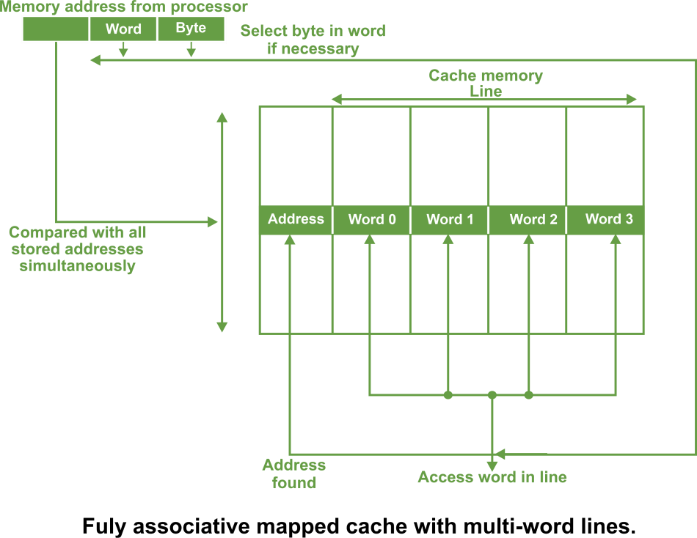
A line constitutes four words, each word being 4 bytes. In such case, the least significant part of the address selects the particular byte, the next part selects the word, and the remaining bits form the address. These address bits are compared to the address in the cache. The whole line can be transferred to and from the cache in one transaction if there are sufficient data paths between the main memory and the cache. With only one data word path, the words of the line have to be transferred in separate transactions. The main advantage of fully associative mapped cache is that it provides greatest flexibility of holding combinations of blocks in the cache and conflict for a given cache. It suffers from certain disadvantages:
The fully associative mechanism is usually employed by microprocessors with small internal cache.
Next Topic#
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








