| |

Data Representation in Computer OrganizationIn computer organization, data refers to the symbols that are used to represent events, people, things and ideas. Data RepresentationThe data can be represented in the following ways: Data Data can be anything like a number, a name, notes in a musical composition, or the color in a photograph. Data representation can be referred to as the form in which we stored the data, processed it and transmitted it. In order to store the data in digital format, we can use any device like computers, smartphones, and iPads. Electronic circuitry is used to handle the stored data. Digitization Digitization is a type of process in which we convert information like photos, music, number, text into digital data. Electronic devices are used to manipulate these types of data. The digital revolution has evolved with the help of 4 phases, starting with the big, expensive standalone computers and progressing to today's digital world. All around the world, small and inexpensive devices are spreading everywhere. Binary Digits The binary digits or bits are used to show the digital data, which is represented by 0 and 1. The binary digits can be called the smallest unit of information in a computer. The main use of binary digit is that it can store the information or data in the form of 0s and 1s. It contains a value that can be on/off or true/false. On or true will be represented by the 1, and off or false will be represented by the 0. The digital file is a simple file, which is used to collect data contained by the storage medium like the flash drive, CD, hard disk, or DVD. 
Representing NumbersThe number can be represented in the following way: Numeric Data Numeric data is used to contain numbers, which helps us to perform arithmetic operations. The digital devices use a binary number system so that they can represent numeric data. The binary number system can only be represented by two digits 0 and 1. There can't be any other digits like 2 in the system. If we want to represent number 2 in binary, then we will write it as 10. 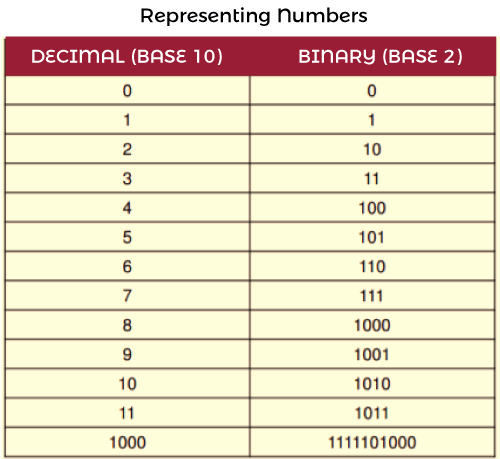
Representing TextThe text can be represented in the following ways: Character Data Character data can be formed with the help of symbols, letters, and numerals, but they can?t be used in calculations. Using the character data, we can form our address, hair colour, name, etc. Character data normally takes the data in the form of text. With the help of the text, we can describe many things like our father name, mother name, etc. Digital Devices Several types of codes are employed by the digital devices to represent character data, including Unicode, ASCII, and other types of variants. The full form of ASCII is American Standard Code for Information Interchange. It is a type of character encoding standard, which is used for electronic communication. With the help of telecommunication equipment, computers and many other devices, ASCII code can represent the text. The ASCII code needs 7 bits for each character, where the unique character is represented by every single bit. For the uppercase letter A, the ASCII code is represented as 1000001. Extended ASCII Extended ASCII can be described as a superset of ASCII. The ASCII set uses 7 bits to represent every character, but the Extended ASCII uses 8 bits to represent each character. The extended ASCII contains 7 bits of ASCII characters and 1 bit for additional characters. Using the 7 bits, the ASCII code provides code for 128 unique symbols or characters, but Extended ASCII provides code for 256 unique symbols or characters. For the uppercase letter A, the Extended ASCII code is represented as 01000001. Unicode Unicode is also known as the universal character encoding standard. Unicode provides a way through which an individual character can be represented in the form of web pages, text files, and other documents. Using ASCII, we can only represent the basic English characters, but with the help of Unicode, we can represent characters from all languages around the World. ASCII code provides code for 128 characters, while Unicode provide code for roughly 65,000 characters with the help of 16 bits. In order to represent each character, ASCII code only uses 1 bit, while Unicode supports up to 4 bytes. The Unicode encoding has several different types, but UTF-8 and UTF-16 are the most commonly used. UTF-8 is a type of variable length coding scheme. It has also become the standard character encoding, which is used on the web. Many software programs also set UTF-8 as their default encoding. 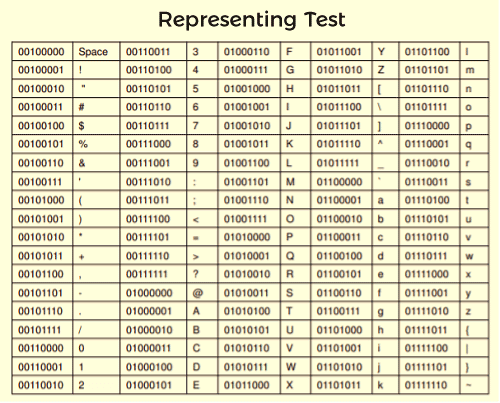
ASCII Code ASCII code can be used for numerals like phone numbers and social security numbers. ASCII text contains plain and unformatted text. This type of file will be saved in a text file format, which contains a name ending with .txt. These files are labelled differently on different systems, like Windows operating system labelled these files as "Text document" and Apple devices labelled these files as "Plain Text". There will have no formatting in the ASCII text files. If we want to make the documents with styles and formats, then we have to embed formatting codes in the text. Microsoft Excel Microsoft word is used to create formatted text and documents. It uses the DOCX format to do this. If we create a new document using the Microsoft Word 2007 or later version, then it always uses DOCX as the default file format. Apple pages use PAGES format to produce the documents. As compared to Microsoft Word, it is simpler to create and edit documents using page format. Adobe Acrobat uses the PDF format to create the documents. The files that saved in the PDF format cannot be modified. But we can easily print and share these files. If we save our document in PDF format, then we cannot change that file into the Microsoft Office file or any other file without specified software. HTML is the hypertext markup language. It is used for document designing, which will be displayed in a web browser. It uses HTML format to design the documents. In HTML, hypertext is a type of text in any document containing links through which we can go to other places in the document or in other documents also. The markup language can be called as a computer language. In order to define the element within a document, this language uses tags. 
Representing Bits and BytesThe bits and bytes can be represented in the following ways: Bits and Bytes In the field of digital communication or computers, bits are the most basic unit of information or smallest unit of data. It is short of binary digit, which means it can contain only one value, either 0 or 1. So bits can be represented by 0 or 1, - or +, false or true, off or on, or no or yes. Many technologies are based on bits and bytes, which is extensively useful to describe the network access speed and storage capacity. The bit is usually abbreviated as a lowercase b. In order to execute the instructions and store the data, the bits are grouped into multiple bits, which are known as bytes. Bytes can be defined as a group of eight bits, and it is usually abbreviated as an uppercase B. If we have four bytes, it will equal 32 bits (4*8 = 32), and 10 bytes will equal 80 bits (8*10 = 80). Uses Bits are used for data rates like speeds while movie download, speed while internet connection, etc. Bytes are used to get the storage capacity and file sizes. When we are reading something related to digital devices, it will be frequently encountered references like 90 kilobits per second, 1.44 megabytes, 2.8 gigahertz, and 2 terabytes. To quantify digital data, we have many options such as Kilo, Mega, Giga, Tera and many more similar terms, which are described as follows: 104 KB: Kb is also called a kilobyte or Kbyte. It is mostly used while referring to the size of small computer files. 56 Kbps: Kbps is also called kilobit, Kbit or Kb. The 56 kbps means 56 kilobits per second which are used to show the slow data rates. If our internet speed is 56 kbps, we have to face difficulty while connecting more than one device, buffering while streaming videos, slow downloading, and many other internet connectivity problems. 50 Mbps: Mbps is also called Megabit, MB or Mbit. The 50 Mbps means 50 Megabit per second, which are used to show the faster data rates. If our internet speed is 50 Mbps, we will experience online activity without any buffering, such as online gaming, downloading music, streaming HD, web browsing, etc. 50 Mbps or more than that will be known as fast internet speed. With the help of fast speed, we can easily handle more than one online activity for more than one user at a time without major interruptions in services. 3.2 MB: 3.2 MB is also called Megabyte, MB or MByte. It is used when we are referring to the size of files, which contains videos and photos. 100 Gbit: 100 Gbit is also called Gigabit or GB. It is used to show the really fast network speeds. 16 GB: 16 GB is also called Gigabyte, GB or GByte. It is used to show the storage capacity. 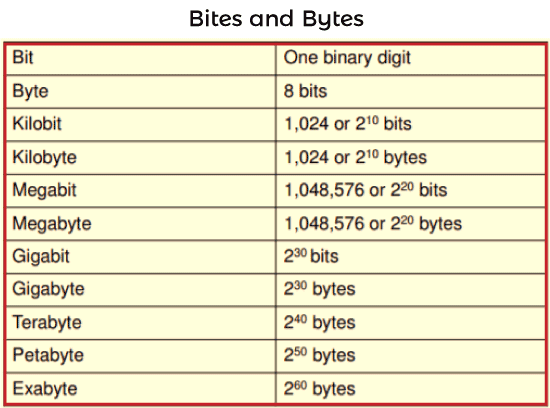
Data CompressionThe digital data is compressed to reduce transmission times and file size. Data compression is the process of reducing the number of bits used to represent data. Data compression typically uses encoding techniques to compress the data. The compressed data will help us to save storage capacity, reduce costs for storage hardware, increase file transfer speed. Compression uses some programs, which also uses algorithms and functions to find out the way to reduce the data size. Compression can be referred "zipping". The process of reconstructing files will be known as unzipping or extracting. The compressed files will contain .gz, or.tar.gz, .pkg, or .zip at the end of the files. Compression can be divided into two techniques: Lossless compression and Lossy compression. 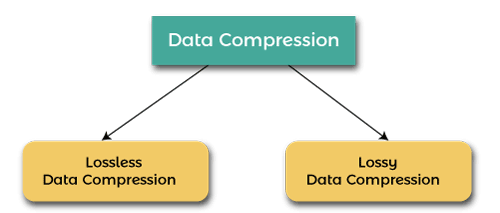
Lossless Compression As the name implies, lossless compression is the process of compressing the data without any loss of information or data. If we compressed the data with the help of lossless compression, then we can exactly recover the original data from the compressed data. That means all the information can be completely restored by lossless compression. Many applications want to use data loss compression. For example, lossless compression can be used in the format of ZIP files and in the GNU tool gzip. The lossless data compression can also be used as a component within the technologies of lossy data compression. It is generally used for discrete data like word processing files, database records, some images, and information of the video. 
According to this image, when we compress the original data using the lossless, we are able to restore all the original data. Lossy Compression Lossy compression is the process of compressing the data, but that data cannot be recovered 100% of original data. This compression is able to provide a high degree of compression, and the result of this compression will be in smaller compressed files. But in this process, some number of video frames, sound waves and original pixels are removed forever. If the compression is greater, then the size of files will be smaller. Business data and text, which needs a full restoration, will never use lossy compression. Nobody likes to lose the information, but there are a lot of files that are very large, and we don't have enough space to maintain all of the original data or many times, we don't require all the original data in the first place. For example, videos, photos and audio recording files to capture the beauty of our world. In this case, we use lossy compression. 
According to this image, when we compress the original data using the lossy, we are only able to restore some amount of data. We will not restore 100% of the original data. |
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








