| |

Text Generation using Gated Recurrent Unit NetworksWhat are Gated Recurrent Unit Networks?A Gated Recurrent Unit Network is a Recurrent Neural Network alternative to Long Short-Term Memory Networks (LSTM). The GRU can work on sequential data like text, speech, and time series. The core idea behind GRU is to employ gating techniques to selectively update the network's hidden state at each time step. The gating mechanisms govern the flow of information into and out of the network. The GRU contains two gating mechanisms: the reset and update gates. Problem StatementWe will build a Text Generator using the Gated Recurrent Unit. We will train the network by passing a text file that will map each character to a unique number. Then, we will hot-encode each character into a vector that the network needs. We will use a collection of famous singers' song lyrics for the Text Generation in .txt format. It can be downloaded from Song Lyrics. Approach to implementation of the Text Generation using the Gated Recurrent Unit NetworkStep 1: Libraries and Dataset The first step is to import the required libraries like numpy, tensorflow, and keras and their different models like LSTM, Sequential, etc. Then, we will load and read the text file., and store it in a string. Code: Output: 
Step 2: Mapping of the characters After reading the file, we will store all the unique characters in a list. Then, we will make dictionaries that map all the characters to indexes. Code: Output:
['\n', ' ', '!', '"', '&', "'", '(', ')', ',', '-', '.', ';', '?', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'Y', '[', ']', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
Step 3: Preprocessing the data After getting the unique words, we will preprocess the data, divide the text into the longest subsequence of the maximum length and then hot encode each character into a vector. Code: Step 4: Making the GRU network We will make a sequential model and add multiple layers like GRU, Dense, Activation, etc. We can build the network with as many layers as we want. Code: Output: Step 5: Making the helper functions We will make some helper functions that will be used at the time of training of the model.
It will sample an index from the probability array and convert the vector into a numpy array. Code:
This function will generate random text after the execution of each epoch. Code:
The random text will generate whenever the model executes with epochs, and the model will decrease loss after every epoch and get saved to the path defined in the function. Code:
This function helps to reduce the learning rate after each epoch. Code: Step 5: Training of the Model Now, we will train the model with different batches and epochs. Here, we have taken a batch size of 140 and an epoch of 40. Code: Output: 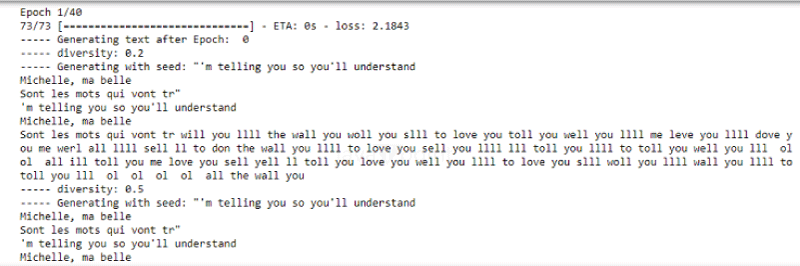
Step 6: Generate the text It will generate random and new text. Code: Output: nd kept out of sight But other girls were never quite Like this, di-di-di-di'n'd say stame tome trre tars tarl ther stand that there tars in ther stars tame to me st man tars tome trre tars that that on ther stars that on ther stars that the ske stars in ther stars tarl ing and warl that that thatting san that stack in that there tome stass and that the can stars that the trre to ther can tars tome trre tars that the ske stand and that that the skn tars tome trre tome tore tome tore tome And you say stame tome trre tome that to grin a long tome trre that long tore thars tom.
Next TopicViterbi Algorithm in NLP
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








