| |
Python Tutorial
Python OOPs
Python MySQL
Python MongoDB
Python SQLite
Python Questions
Plotly
Python Tkinter (GUI)
Python Web Blocker
Python MCQ
Related Tutorials
Python Programs

How to Make the First Column an Index in PythonFoundation/ A brief on the pre-requisite knowledge: 'Pandas' is one of Python's most prominent libraries. It is used widely in different applications of machine learning and data analysis. Using Pandas, the programmer can create, read and manipulate huge amounts of data and work with any file. 'Pandas' has many ML tools to apply to huge chunks of data and get the required result. The data can be arranged in two forms in Pandas:
Here is a simple example program: Output:
name roll branch age
0 Raghav 301 ECE 19
1 Charan 202 EEE 18
2 Santhosh 103 CSE 19
Understanding: Three separate Series are created-name, age, roll, and branch. All are then combined into a data frame to represent a table.
set_index Method:Given the simplicity and abundance of methods and tools, we can set any column we want as an index using a simple method, "set_index()." Syntax:
Example: Output:
Original dataframe:
Names Branch Age CGPA
Student1 Raghav ECE 19 9.1
Student2 Charan B-Arch 18 9.4
Student3 Santosh AIML 19 9.6
Branch column as the index to the data frame:
Names Age CGPA
Branch
ECE Raghav 19 9.1
B-Arch Charan 18 9.4
AIML Santosh 19 9.6
Names and Age columns as the index to the data frame:
CGPA
Names Age
Raghav 19 9.1
Charan 18 9.4
Santosh 19 9.6
Understanding: In the above code, the column 'Branch' is made into the index in the first part. Once it is made index, it is dropped from the table as, by default, drop is set to True. Hence, in the next part, when the columns 'Names' and 'Age' are made indices, the 'Branch' column is absent.
Using pandas, the programmer can work with any files. For instance, to work with CSV files:
Program: Output:
Names Branch Age Salary Experience (yrs)
0 Sudha HR 44 112000 8
1 Harini Developer 23 94000 2
2 Venkat Sales 44 122000 8
Understanding: Using .tocsv (), the data frame is converted into a CSV file and using .read_csv (), the file is read. On this dataframe, we can change the index into any column we want, like a normal dataframe: Like a normal data frame, the data frame in the CSV file will be modified, and the index becomes the 'Names' column. The file can be found in the python directory and checked: 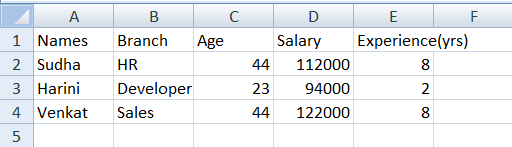
Next TopicHow to Make an App in Python
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








