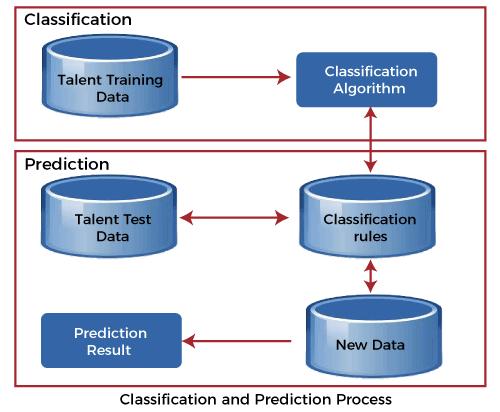
Classification and Predication in Data Mining
There are two forms of data analysis that can be used to extract models describing important classes or predict future data trends. These two forms are as follows:
- Classification
- Prediction
We use classification and prediction to extract a model, representing the data classes to predict future data trends. Classification predicts the categorical labels of data with the prediction models. This analysis provides us with the best understanding of the data at a large scale.
Classification models predict categorical class labels, and prediction models predict continuous-valued functions. For example, we can build a classification model to categorize bank loan applications as either safe or risky or a prediction model to predict the expenditures in dollars of potential customers on computer equipment given their income and occupation.
What is Classification?
Classification is to identify the category or the class label of a new observation. First, a set of data is used as training data. The set of input data and the corresponding outputs are given to the algorithm. So, the training data set includes the input data and their associated class labels. Using the training dataset, the algorithm derives a model or the classifier. The derived model can be a decision tree, mathematical formula, or a neural network. In classification, when unlabeled data is given to the model, it should find the class to which it belongs. The new data provided to the model is the test data set.
Classification is the process of classifying a record. One simple example of classification is to check whether it is raining or not. The answer can either be yes or no. So, there is a particular number of choices. Sometimes there can be more than two classes to classify. That is called multiclass classification.
The bank needs to analyze whether giving a loan to a particular customer is risky or not. For example, based on observable data for multiple loan borrowers, a classification model may be established that forecasts credit risk. The data could track job records, homeownership or leasing, years of residency, number, type of deposits, historical credit ranking, etc. The goal would be credit ranking, the predictors would be the other characteristics, and the data would represent a case for each consumer. In this example, a model is constructed to find the categorical label. The labels are risky or safe.
How does Classification Works?
The functioning of classification with the assistance of the bank loan application has been mentioned above. There are two stages in the data classification system: classifier or model creation and classification classifier.
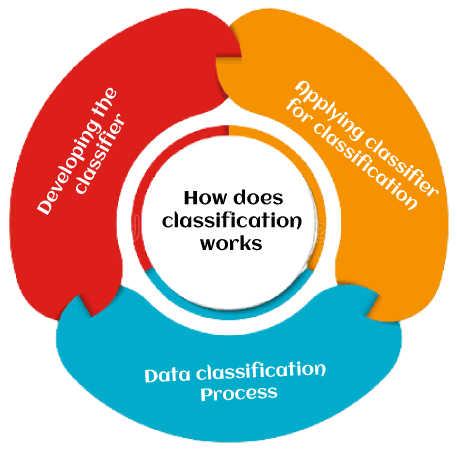
- Developing the Classifier or model creation: This level is the learning stage or the learning process. The classification algorithms construct the classifier in this stage. A classifier is constructed from a training set composed of the records of databases and their corresponding class names. Each category that makes up the training set is referred to as a category or class. We may also refer to these records as samples, objects, or data points.
- Applying classifier for classification: The classifier is used for classification at this level. The test data are used here to estimate the accuracy of the classification algorithm. If the consistency is deemed sufficient, the classification rules can be expanded to cover new data records. It includes:
- Sentiment Analysis: Sentiment analysis is highly helpful in social media monitoring. We can use it to extract social media insights. We can build sentiment analysis models to read and analyze misspelled words with advanced machine learning algorithms. The accurate trained models provide consistently accurate outcomes and result in a fraction of the time.
- Document Classification: We can use document classification to organize the documents into sections according to the content. Document classification refers to text classification; we can classify the words in the entire document. And with the help of machine learning classification algorithms, we can execute it automatically.
- Image Classification: Image classification is used for the trained categories of an image. These could be the caption of the image, a statistical value, a theme. You can tag images to train your model for relevant categories by applying supervised learning algorithms.
- Machine Learning Classification: It uses the statistically demonstrable algorithm rules to execute analytical tasks that would take humans hundreds of more hours to perform.
- Data Classification Process: The data classification process can be categorized into five steps:
- Create the goals of data classification, strategy, workflows, and architecture of data classification.
- Classify confidential details that we store.
- Using marks by data labelling.
- To improve protection and obedience, use effects.
- Data is complex, and a continuous method is a classification.
What is Data Classification Lifecycle?
The data classification life cycle produces an excellent structure for controlling the flow of data to an enterprise. Businesses need to account for data security and compliance at each level. With the help of data classification, we can perform it at every stage, from origin to deletion. The data life-cycle has the following stages, such as:
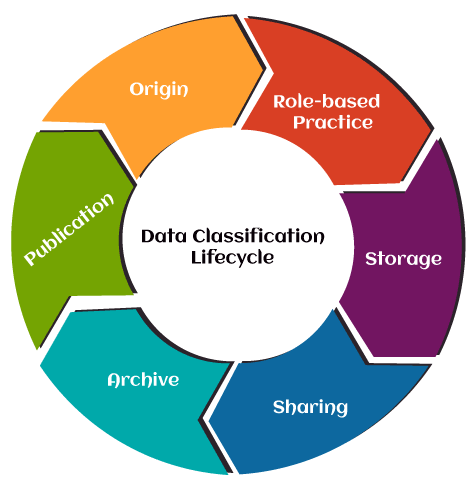
- Origin: It produces sensitive data in various formats, with emails, Excel, Word, Google documents, social media, and websites.
- Role-based practice: Role-based security restrictions apply to all delicate data by tagging based on in-house protection policies and agreement rules.
- Storage: Here, we have the obtained data, including access controls and encryption.
- Sharing: Data is continually distributed among agents, consumers, and co-workers from various devices and platforms.
- Archive: Here, data is eventually archived within an industry's storage systems.
- Publication: Through the publication of data, it can reach customers. They can then view and download in the form of dashboards.
What is Prediction?
Another process of data analysis is prediction. It is used to find a numerical output. Same as in classification, the training dataset contains the inputs and corresponding numerical output values. The algorithm derives the model or a predictor according to the training dataset. The model should find a numerical output when the new data is given. Unlike in classification, this method does not have a class label. The model predicts a continuous-valued function or ordered value.
Regression is generally used for prediction. Predicting the value of a house depending on the facts such as the number of rooms, the total area, etc., is an example for prediction.
For example, suppose the marketing manager needs to predict how much a particular customer will spend at his company during a sale. We are bothered to forecast a numerical value in this case. Therefore, an example of numeric prediction is the data processing activity. In this case, a model or a predictor will be developed that forecasts a continuous or ordered value function.
Classification and Prediction Issues
The major issue is preparing the data for Classification and Prediction. Preparing the data involves the following activities, such as:

- Data Cleaning: Data cleaning involves removing the noise and treatment of missing values. The noise is removed by applying smoothing techniques, and the problem of missing values is solved by replacing a missing value with the most commonly occurring value for that attribute.
- Relevance Analysis: The database may also have irrelevant attributes. Correlation analysis is used to know whether any two given attributes are related.
- Data Transformation and reduction: The data can be transformed by any of the following methods.
- Normalization: The data is transformed using normalization. Normalization involves scaling all values for a given attribute to make them fall within a small specified range. Normalization is used when the neural networks or the methods involving measurements are used in the learning step.
- Generalization: The data can also be transformed by generalizing it to the higher concept. For this purpose, we can use the concept hierarchies.
NOTE: Data can also be reduced by some other methods such as wavelet transformation, binning, histogram analysis, and clustering.
Comparison of Classification and Prediction Methods
Here are the criteria for comparing the methods of Classification and Prediction, such as:

- Accuracy: The accuracy of the classifier can be referred to as the ability of the classifier to predict the class label correctly, and the accuracy of the predictor can be referred to as how well a given predictor can estimate the unknown value.
- Speed: The speed of the method depends on the computational cost of generating and using the classifier or predictor.
- Robustness: Robustness is the ability to make correct predictions or classifications. In the context of data mining, robustness is the ability of the classifier or predictor to make correct predictions from incoming unknown data.
- Scalability: Scalability refers to an increase or decrease in the performance of the classifier or predictor based on the given data.
- Interpretability: Interpretability is how readily we can understand the reasoning behind predictions or classification made by the predictor or classifier.
Difference between Classification and Prediction
The decision tree, applied to existing data, is a classification model. We can get a class prediction by applying it to new data for which the class is unknown. The assumption is that the new data comes from a distribution similar to the data we used to construct our decision tree. In many instances, this is a correct assumption, so we can use the decision tree to build a predictive model. Classification of prediction is the process of finding a model that describes the classes or concepts of information. The purpose is to predict the class of objects whose class label is unknown using this model. Below are some major differences between classification and prediction.
| Classification |
Prediction |
| Classification is the process of identifying which category a new observation belongs to based on a training data set containing observations whose category membership is known. |
Predication is the process of identifying the missing or unavailable numerical data for a new observation. |
| In classification, the accuracy depends on finding the class label correctly. |
In prediction, the accuracy depends on how well a given predictor can guess the value of a predicated attribute for new data. |
| In classification, the model can be known as the classifier. |
In prediction, the model can be known as the predictor. |
| A model or the classifier is constructed to find the categorical labels. |
A model or a predictor will be constructed that predicts a continuous-valued function or ordered value. |
| For example, the grouping of patients based on their medical records can be considered a classification. |
For example, We can think of prediction as predicting the correct treatment for a particular disease for a person. |
|

 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now








