| |

KDD vs Data MiningKDD (Knowledge Discovery in Databases) is a field of computer science, which includes the tools and theories to help humans in extracting useful and previously unknown information (i.e., knowledge) from large collections of digitized data. KDD consists of several steps, and Data Mining is one of them. Data Mining is the application of a specific algorithm to extract patterns from data. Nonetheless, KDD and Data Mining are used interchangeably. What is KDD?KDD is a computer science field specializing in extracting previously unknown and interesting information from raw data. KDD is the whole process of trying to make sense of data by developing appropriate methods or techniques. This process deals with low-level mapping data into other forms that are more compact, abstract, and useful. This is achieved by creating short reports, modeling the process of generating data, and developing predictive models that can predict future cases. Due to the exponential growth of data, especially in areas such as business, KDD has become a very important process to convert this large wealth of data into business intelligence, as manual extraction of patterns has become seemingly impossible in the past few decades. For example, it is currently used for various applications such as social network analysis, fraud detection, science, investment, manufacturing, telecommunications, data cleaning, sports, information retrieval, and marketing. KDD is usually used to answer questions like what are the main products that might help to obtain high-profit next year in V-Mart. KDD Process StepsKnowledge discovery in the database process includes the following steps, such as: 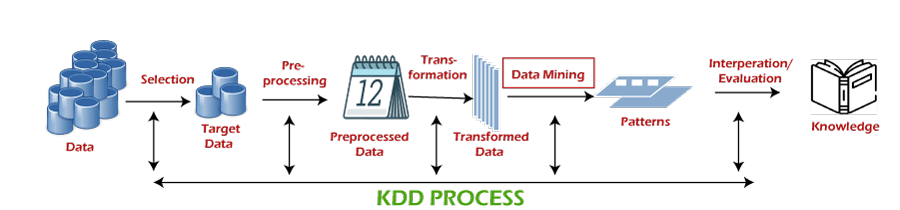
What is Data Mining?Data mining, also known as Knowledge Discovery in Databases, refers to the nontrivial extraction of implicit, previously unknown, and potentially useful information from data stored in databases. Data Mining is only a step within the overall KDD process. There are two major Data Mining goals defined by the application's goal: verification of discovery. Verification verifies the user's hypothesis about data, while discovery automatically finds interesting patterns. There are four major data mining tasks: clustering, classification, regression, and association (summarization). Clustering is identifying similar groups from unstructured data. Classification is learning rules that can be applied to new data. Regression is finding functions with minimal error to model data. And the association looks for relationships between variables. Then, the specific data mining algorithm needs to be selected. Different algorithms like linear regression, logistic regression, decision trees, and Naive Bayes can be selected depending on the goal. Then patterns of interest in one or more symbolic forms are searched. Finally, models are evaluated either using predictive accuracy or understandability. Why do we need Data Mining?The volume of information is increasing every day that we can handle from business transactions, scientific data, sensor data, Pictures, videos, etc. So, we need a system that will be capable of extracting the essence of information available and that can automatically generate reports, views, or summaries of data for better decision-making. Why is Data Mining used in business?Data mining is used in business to make better managerial decisions by:
Why KDD and Data Mining?In an increasingly data-driven world, there would never be such a thing as too much data. However, data is only valuable when you can parse, sort, and sift through it to extrapolate the actual value. Most industries collect massive volumes of data, but without a filtering mechanism that graphs, charts, and trends data models, pure data itself has little use. However, the sheer volume of data and the speed with which it is collected makes sifting through it challenging. Thus, it has become economically and scientifically necessary to scale up our analysis capability to handle the vast amount of data that we now obtain. Since computers have allowed humans to collect more data than we can process, we naturally turn to computational techniques to help us extract meaningful patterns and structures from vast amounts of data. Difference between KDD and Data MiningAlthough the two terms KDD and Data Mining are heavily used interchangeably, they refer to two related yet slightly different concepts. KDD is the overall process of extracting knowledge from data, while Data Mining is a step inside the KDD process, which deals with identifying patterns in data. And Data Mining is only the application of a specific algorithm based on the overall goal of the KDD process. KDD is an iterative process where evaluation measures can be enhanced, mining can be refined, and new data can be integrated and transformed to get different and more appropriate results.
Next TopicWhat is Noise in Data Mining
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








