| |

What is CRISP in Data Mining?CRISP-DM stands for the cross-industry standard process for data mining. The CRISP-DM methodology provides a structured approach to planning a data mining project. It is a robust and well-proven methodology. We do not claim any ownership over it. We did not invent it. We are a converter of its powerful practicality, flexibility, and usefulness when using analytics to solve business issues. It is the golden thread that runs through almost every client meeting. This model is an idealized sequence of events. In practice, many tasks can perform in a different order, and it will often be necessary to backtrack to previous tasks and repeat certain actions. The model does not try to capture all possible routes through the data mining process. How does CRISP Help?CRISP DM provides a roadmap, it gives you best practices, and it provides structures for better and faster results of using data mining, so that's how it helps the business follow while planning and carrying out a data mining project. Phases of CRISP-DMCRISP-DM provides an overview of the data mining life cycle as a process model. The life cycle model comprises six phases, with arrows indicating the most important and frequent dependencies between phases. The sequence of the phases is not strict. And most projects move back and forth between phases as necessary. The CRISP-DM model is flexible and can be customized easily. For example, if your organization aims to detect money laundering, you will likely sift through large amounts of data without a specific modelling goal. Instead of modelling, your work will focus on data exploration and visualization to uncover suspicious patterns in financial data. CRISP-DM allows you to create a data mining model that fits your needs. It includes descriptions of typical phases of a project, the tasks involved with each phase, and an explanation of the relationships between these tasks. 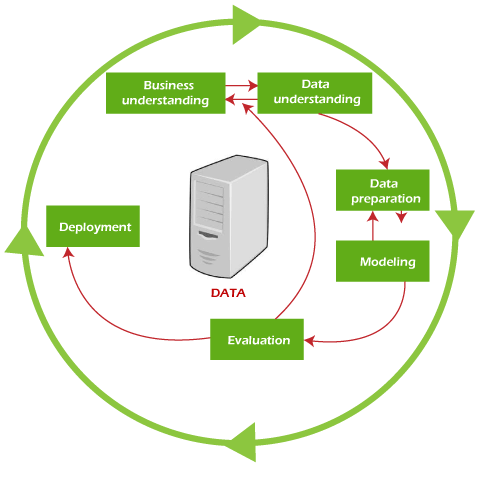
Phase 1: Business UnderstandingThe first stage of the CRISP-DM process is understanding what you want to accomplish from a business perspective. Your organization may have competing objectives and constraints that must be properly balanced. This process stage aims to uncover important factors influencing the project's outcome. Neglecting this step can mean much effort is put into producing the right answers to the wrong questions. What are the desired outputs of the project?
Assess the current situation This involves more detailed fact-finding about the resources, constraints, assumptions and other factors you'll need to consider when determining your data analysis goal and project plan.
Determine data mining goals A business goal states objectives in business terminology. A data mining goal states project objectives in technical terms. For example, the business goal might be Increase catalogue sales to existing customers. A data mining goal might be to Predict how many widgets a customer will buy, given their purchases over the past three years, demographic information (age, salary, city, etc.), and the item's price.
Produce project plan Describe the intended plan for achieving the data mining goals and business goals. Your plan should specify the steps to perform during the rest of the project, including the initial selection of tools and techniques. 1. Project plan: List the stages to be executed in the project, with their duration, resources required, inputs, outputs, and dependencies. Where possible, try and make explicit the large-scale iterations in the data mining process, for example, repetitions of the modelling and evaluation phases. As part of the project plan, it is important to analyze the dependencies between time schedules and risks. Mark the results of these analyses explicitly in the project plan, ideally with actions and recommendations if the risks are manifested. Decide which evaluation strategy will be used in the evaluation phase. Your project plan will be a dynamic document. At the end of each phase, you'll review progress and achievements and update the project plan accordingly. Specific review points for these updates should be part of the project plan. 2. Initial assessment of tools and techniques: At the end of the first phase, you should undertake an initial assessment of tools and techniques. For example, you select a data mining tool that supports various methods for different stages of the process. It is important to assess tools and techniques early in the process since the selection of tools and techniques may influence the entire project. Phase 2: Data UnderstandingThe second phase of the CRISP-DM process requires you to acquire the data listed in the project resources. This initial collection includes data loading if this is necessary for data understanding. For example, if you use a specific tool for data understanding, it makes perfect sense to load your data into this tool. If you acquire multiple data sources, you need to consider how and when you will integrate these.
Describe data Examine the "gross" or "surface" properties of the acquired data and report on the results.
Explore data During this stage, you'll address data mining questions using querying, data visualization and reporting techniques. These may include:
These analyses may directly address your data mining goals. They may contribute to or refine the data description and quality reports and feed into the transformation and other data preparation steps needed for further analysis.
Verify data quality Examine the quality of the data, addressing questions such as:
Data quality report List the results of the data quality verification. If quality problems exist, suggest possible solutions. Solutions to data quality problems generally depend heavily on data and business knowledge. Phase 3: Data PreparationIn this project phase, you decide on the data you will use for analysis. The criteria you might use to make this decision include the relevance of the data to your data mining goals, the data's quality, and technical constraints such as limits on data volume or data types.
Clean your data This task involves raising the data quality to the level required by the analysis techniques that you've selected. This may involve selecting clean subsets of the data, the insertion of suitable defaults, or more ambitious techniques such as estimating missing data by modelling.
Construct required data This task includes constructive data preparation operations such as producing derived attributes, entire new records, or transformed values for existing attributes.
Integrate data These methods combine information from multiple databases, tables or records to create new records or values.
Phase 4: ModellingSelect modelling technique: As the first step, you'll select the basic modelling technique you will use. Although you may have already selected a tool during the business understanding phase, at this stage, you'll be selecting the specific modelling technique, e.g. decision-tree building with C5.0 or neural network generation with back propagation. If multiple techniques are applied, perform this task separately for each technique.
Generate test design Before you build a model, you need to generate a procedure or mechanism to test the model's quality and validity. For example, in supervised data mining tasks such as classification, it is common to use error rates as quality measures for data mining models. Therefore, you typically separate the dataset into train and test sets, build the model on the train set, and estimate its quality on the separate test set.
Build model Run the modelling tool on the prepared dataset to create one or more models.
Assess model Interpret the models according to your domain knowledge, data mining success criteria, and desired test design. Judge the success of the application of modelling and discovery techniques, and then contact business analysts and domain experts later to discuss the data mining results in the business context. This task only considers models, whereas the evaluation phase also considers all other results produced during the project. At this stage, you should rank the models and assess them according to the evaluation criteria. You should consider the business objectives and success criteria as far as you can here. In most data mining projects, a single technique is applied more than once, and data mining results are generated with several different techniques.
Phase 5: EvaluationEvaluate your results: Previous evaluation steps dealt with factors such as the accuracy and generality of the model. During this step, you'll assess the degree to which the model meets your business objectives and seek to determine if there is some business reason why this model is deficient. Another option is to test the model on test applications in the real application if time and budget constraints permit. The evaluation phase also involves assessing any other data mining results you've generated. Data mining results involve models that are necessarily related to the original business objectives and all other findings that are not necessarily related to the original business objectives but might also unveil additional challenges, information, or hints for future directions.
Review process At this point, the resulting models appear to be satisfactory and satisfy business needs. It is now appropriate for you to do a more thorough review of the data mining engagement to determine if there is an important factor or task that has somehow been overlooked. This review also covers quality assurance issues. For example: did we correctly build the model? Did we use only the attributes that we are allowed to use and that are available for future analyses?
Determine next steps You now decide how to proceed depending on the assessment results and the process review. Do you finish this project and move on to deployment, initiate further iterations, or set up new data mining projects? You should also take stock of your remaining resources and budget, which may influence your decisions.
Phase 6: DeploymentPlan deployment: In the deployment stage, you'll take your evaluation results and determine a strategy for their deployment. If a general procedure has been identified to create the relevant model(s), this procedure is documented here for later deployment. It makes sense to consider the ways and means of deployment during the business understanding phase because deployment is crucial to the project's success. This is where predictive analytics helps improve your business's operational side.
Plan monitoring and maintenance Monitoring and maintenance are important issues if the data mining result becomes part of the day-to-day business and its environment. The careful preparation of a maintenance strategy helps to avoid unnecessarily long periods of incorrect usage of data mining results. The project needs a detailed monitoring process plan to monitor the deployment of the data mining result(s). This plan takes into account the specific type of deployment.
Produce final report At the end of the project, you will write a final report. Depending on the deployment plan, this report may be only a summary of the project and its experiences (if they have not already been documented as an ongoing activity), or it may be a final and comprehensive presentation of the data mining result.
Review project Assess what went right and wrong, what was done well and what needs improvement.
Next TopicFP Growth Algorithm in Data Mining
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








