| |

Data Processing in Data MiningData processing is collecting raw data and translating it into usable information. The raw data is collected, filtered, sorted, processed, analyzed, stored, and then presented in a readable format. It is usually performed in a step-by-step process by a team of data scientists and data engineers in an organization. The data processing is carried out automatically or manually. Nowadays, most data is processed automatically with the help of the computer, which is faster and gives accurate results. Thus, data can be converted into different forms. It can be graphic as well as audio ones. It depends on the software used as well as data processing methods. After that, the data collected is processed and then translated into a desirable form as per requirements, useful for performing tasks. The data is acquired from Excel files, databases, text file data, and unorganized data such as audio clips, images, GPRS, and video clips. Data processing is crucial for organizations to create better business strategies and increase their competitive edge. By converting the data into a readable format like graphs, charts, and documents, employees throughout the organization can understand and use the data. The most commonly used tools for data processing are Storm, Hadoop, HPCC, Statwing, Qubole, and CouchDB. The processing of data is a key step of the data mining process. Raw data processing is a more complicated task. Moreover, the results can be misleading. Therefore, it is better to process data before analysis. The processing of data largely depends on the following things, such as:
Stages of Data ProcessingThe data processing consists of the following six stages. 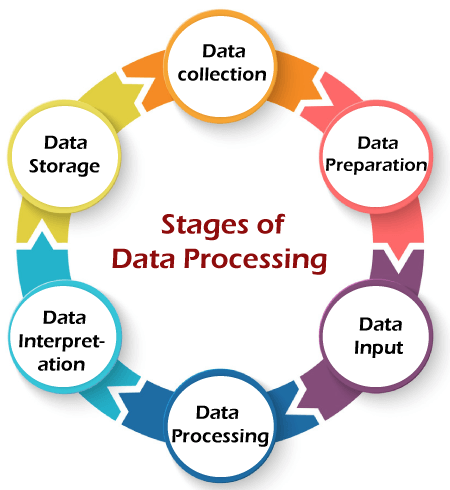
1. Data Collection The collection of raw data is the first step of the data processing cycle. The raw data collected has a huge impact on the output produced. Hence, raw data should be gathered from defined and accurate sources so that the subsequent findings are valid and usable. Raw data can include monetary figures, website cookies, profit/loss statements of a company, user behavior, etc. 2. Data Preparation Data preparation or data cleaning is the process of sorting and filtering the raw data to remove unnecessary and inaccurate data. Raw data is checked for errors, duplication, miscalculations, or missing data and transformed into a suitable form for further analysis and processing. This ensures that only the highest quality data is fed into the processing unit. 3. Data Input In this step, the raw data is converted into machine-readable form and fed into the processing unit. This can be in the form of data entry through a keyboard, scanner, or any other input source. 4. Data Processing In this step, the raw data is subjected to various data processing methods using machine learning and artificial intelligence algorithms to generate the desired output. This step may vary slightly from process to process depending on the source of data being processed (data lakes, online databases, connected devices, etc.) and the intended use of the output. 5. Data Interpretation or Output The data is finally transmitted and displayed to the user in a readable form like graphs, tables, vector files, audio, video, documents, etc. This output can be stored and further processed in the next data processing cycle. 6. Data Storage The last step of the data processing cycle is storage, where data and metadata are stored for further use. This allows quick access and retrieval of information whenever needed. Effective proper data storage is necessary for compliance with GDPR (data protection legislation). Why Should We Use Data Processing?In the modern era, most of the work relies on data, therefore collecting large amounts of data for different purposes like academic, scientific research, institutional use, personal and private use, commercial purposes, and lots more. The processing of this data collected is essential so that the data goes through all the above steps and gets sorted, stored, filtered, presented in the required format, and analyzed. The amount of time consumed and the intricacy of processing will depend on the required results. In situations where large amounts of data are acquired, the necessity of processing to obtain authentic results with the help of data processing in data mining and data processing in data research is inevitable. Methods of Data ProcessingThere are three main data processing methods, such as: 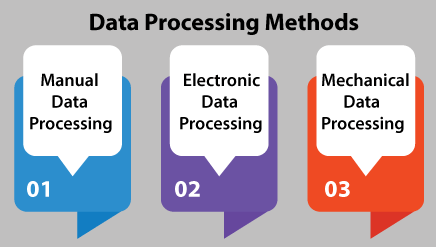
1. Manual Data Processing Data is processed manually in this data processing method. The entire procedure of data collecting, filtering, sorting, calculation and alternative logical operations is all carried out with human intervention without using any electronic device or automation software. It is a low-cost methodology and does not need very many tools. However, it produces high errors and requires high labor costs and lots of time. 2. Mechanical Data Processing Data is processed mechanically through the use of devices and machines. These can include simple devices such as calculators, typewriters, printing press, etc. Simple data processing operations can be achieved with this method. It has much fewer errors than manual data processing, but the increase in data has made this method more complex and difficult. 3. Electronic Data Processing Data is processed with modern technologies using data processing software and programs. The software gives a set of instructions to process the data and yield output. This method is the most expensive but provides the fastest processing speeds with the highest reliability and accuracy of output. Types of Data ProcessingThere are different types of data processing based on the source of data and the steps taken by the processing unit to generate an output. There is no one size fits all method that can be used for processing raw data. 
Examples of Data ProcessingData processing occurs in our daily lives whether we may be aware of it or not. Here are some real-life examples of data processing, such as:
Importance of Data Processing in Data MiningIn today's world, data has a significant bearing on researchers, institutions, commercial organizations, and each individual user. Data is often imperfect, noisy, and incompatible, and then it requires additional processing. After gathering, the question arises of how to store, sort, filter, analyze and present data. Here data mining comes into play. The complexity of this process is subject to the scope of data collection and the complexity of the required results. Whether this process is time-consuming depends on steps, which need to be made with the collected data and the type of output file desired to be received. This issue becomes actual when the need for processing a big amount of data arises. Therefore, data mining is widely used nowadays. When data is gathered, there is a need to store it. The data can be stored in physical form using paper-based documents, laptops and desktop computers, or other data storage devices. With the rise and rapid development of such things as data mining and big data, the process of data collection becomes more complicated and time-consuming. It is necessary to carry out many operations to conduct thorough data analysis. At present, data is stored in a digital form for the most part. It allows processing data faster and converting it into different formats. The user has the possibility to choose the most suitable output.
Next TopicData Reduction in Data Mining
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








