| |

What is Multimedia Data Mining?Multimedia mining is a subfield of data mining that is used to find interesting information of implicit knowledge from multimedia databases. Mining in multimedia is referred to as automatic annotation or annotation mining. Mining multimedia data requires two or more data types, such as text and video or text video and audio. Multimedia data mining is an interdisciplinary field that integrates image processing and understanding, computer vision, data mining, and pattern recognition. Multimedia data mining discovers interesting patterns from multimedia databases that store and manage large collections of multimedia objects, including image data, video data, audio data, sequence data and hypertext data containing text, text markups, and linkages. Issues in multimedia data mining include content-based retrieval and similarity search, generalization and multidimensional analysis. Multimedia data cubes contain additional dimensions and measures for multimedia information. The framework that manages different types of multimedia data stored, delivered, and utilized in different ways is known as a multimedia database management system. There are three classes of multimedia databases: static, dynamic, and dimensional media. The content of the Multimedia Database management system is as follows:
Types of Multimedia ApplicationsTypes of multimedia applications based on data management characteristics are:
Challenges with Multimedia DatabaseThere are still many challenges to multimedia databases, such as: 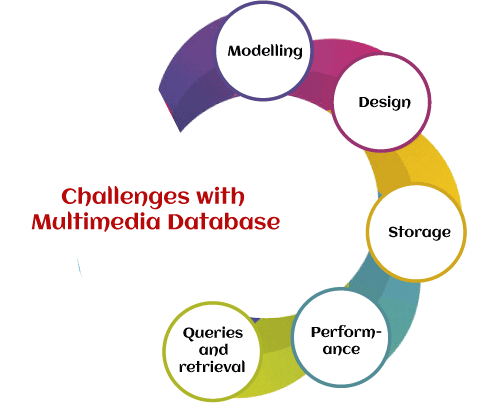
Where is Multimedia Database Applied?Below are the following areas where a multimedia database is applied, such as:
Categories of Multimedia Data MiningMultimedia mining refers to analyzing a large amount of multimedia information to extract patterns based on their statistical relationships. Multimedia data mining is classified into two broad categories: static and dynamic media. Static media contains text (digital library, creating SMS and MMS) and images (photos and medical images). Dynamic media contains Audio (music and MP3 sounds) and Video (movies). The below image shows the categories of multimedia data mining. 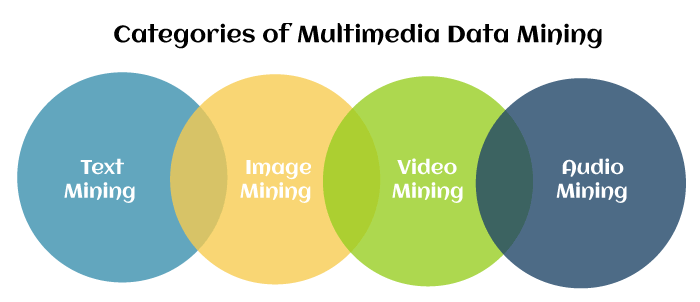
1. Text Mining Text is the foremost general medium for the proper exchange of information. Text Mining evaluates a huge amount of usual language text and detects exact patterns to find useful information. Text Mining also referred to as text data mining, is used to find meaningful information from unstructured texts from various sources. 2. Image Mining Image mining systems can discover meaningful information or image patterns from a huge collection of images. Image mining determines how low-level pixel representation consists of a raw image or image sequence that can be handled to recognize high-level spatial objects and relationships. It includes digital image processing, image understanding, database, AI, etc. 3. Video Mining Video mining is unsubstantiated to find interesting patterns from many video data; multimedia data is video data such as text, image, metadata, visuals and audio. It is commonly used in security and surveillance, entertainment, medicine, sports and education programs. The processing is indexing, automatic segmentation, content-based retrieval, classification and detecting triggers. 4. Audio Mining Audio mining plays an important role in multimedia applications, is a technique by which the content of an audio signal can be automatically searched, analyzed and rotten with wavelet transformation. It is generally used in automatic speech recognition, where the analysis efforts to find any speech within the audio. Band energy, frequency centroid, zero-crossing rate, pitch period and bandwidth are often used for audio processing. Application of Multimedia MiningThere are different kinds of applications of multimedia data mining, some of which are as follows: 
Process of Multimedia Data MiningThe below image shows the present architecture, which includes the types of the multimedia mining process. Data Collection is the initial stage of the learning system; Pre-processing is to extract significant features from raw data. It includes data cleaning, transformation, normalization, feature extraction, etc. Learning can be direct if informative types can be recognized at preprocessing stage. The complete process depends extremely on the nature of raw data and the difficulty field. The product of preprocessing is the training set. A learning model must be selected for the specified training set to learn from it and make the multimedia model more constant. 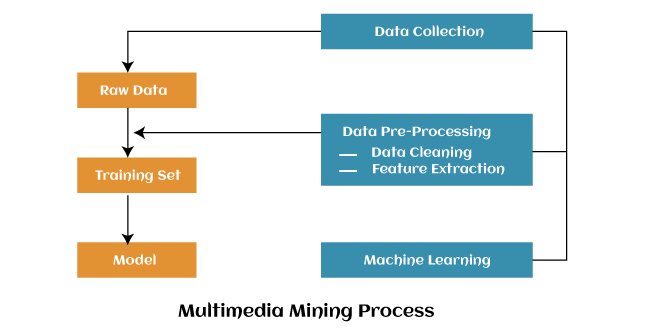
Converting Un-structured data to structured data: Data resides in a fixed field within a record or file is called structured data, and these data are stored in sequential form. Structured data has been easily entered, stored, queried and analyzed. Unstructured data is bitstream, for example, pixel representation for an image, audio, video and character representation for text. These files may have an internal structure, but they are still considered "unstructured" because their data does not fit neatly in a database. For example, images and videos of different objects have some similarities - each represents an interpretation of a building without a clear structure. 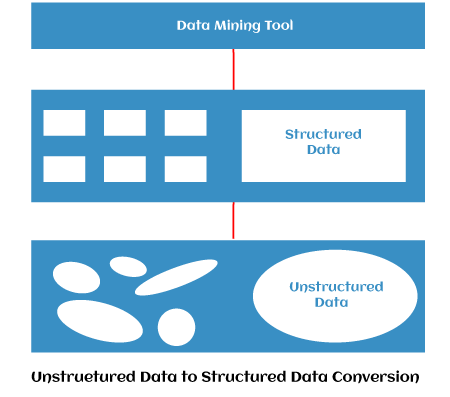
Current data mining tools operate on structured data, which resides in a huge volume of the relational database, while data in multimedia databases are semi-structured or unstructured. Hence, the semi-structured or unstructured multimedia data is converted into structured one, and then the current data mining tools are used to extract the knowledge. The sequence or time element is different between unstructured and structured data mining. The architecture of converting unstructured data to structured data and which is used for extracting information from the unstructured database, is shown in the above image. Then data mining tools are applied to the stored structured databases. Architecture for Multimedia Data MiningMultimedia mining architecture is given in the below image. The architecture has several components. Important components are Input, Multimedia Content, Spatiotemporal Segmentation, Feature Extraction, Finding similar Patterns, and Evaluation of Results. 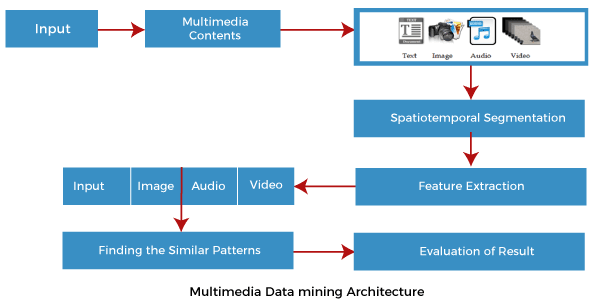
Models for Multimedia MiningThe models which are used to perform multimedia data are very important in mining. Commonly four different multimedia mining models have been used. These are classification, association rule, clustering and statistical modelling. 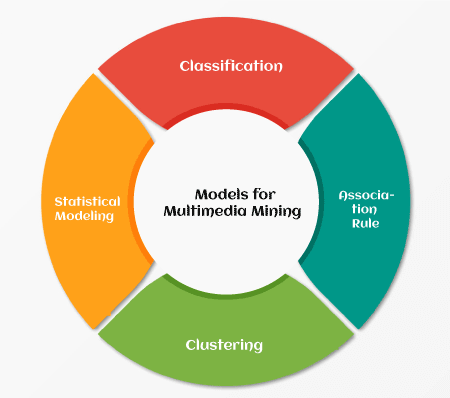
Issues in Multimedia MiningMajor Issues in multimedia data mining contains content-based retrieval, similarity search, dimensional analysis, classification, prediction analysis and mining associations in multimedia data. 1. Content-based retrieval and Similarity search Content-based retrieval in multimedia is a stimulating problem since multimedia data is required for detailed analysis from pixel values. We considered two main families of multimedia retrieval systems, i.e. similarity search in multimedia data.
2. Multidimensional Analysis To perform multidimensional analysis of large multimedia databases, multimedia data cubes may be designed and constructed similarly to traditional data cubes from relational data. A multimedia data cube has several dimensions. For example, the size of the image or video in bytes; the width and height of the frames, creating two dimensions, the date on which image or video was created or last modified, the format type of the image or video, frame sequence duration in seconds, Internet domain of pages referencing the image or video, the keywords like a colour dimension and edge orientation dimension. A multimedia data cube can have additional dimensions and measures for multimedia data, such as colour, texture, and shape. The Multimedia data mining system prototype is MultiMediaMiner, the extension of the DBMiner system that handles multimedia data. The Image Excavator component of MultiMediaMiner uses image contextual information, like HTML tags on Web pages, to derive keywords. By navigating online directory structures, like Yahoo! directory, it is possible to build hierarchies of keywords mapped on the directories in which the image was found. 3. Classification and Prediction Analysis Classification and predictive analysis has been used for mining multimedia data, particularly in scientific analysis like astronomy, seismology, and geoscientific analysis. Decision tree classification is an important method for reported image data mining applications. For example, consider the sky images, which astronomers have carefully classified as the training set. It can create models for recognizing galaxies, stars and further stellar objects based on properties like magnitudes, areas, intensity, image moments and orientation. Image data mining classification and clustering are carefully connected to image analysis and scientific data mining. The image data are frequently in large volumes and need substantial processing power, such as parallel and distributed processing. Hence, many image analysis techniques and scientific data analysis methods could be applied to image data mining. 4. Mining Associations in Multimedia Data Association rules involving multimedia objects have been mined in image and video databases. Three categories can be observed:
First, an image contains multiple objects, each with various features such as colour, shape, texture, keyword, and spatial locations, so that many possible associations can be made. Second, a picture containing multiple repeated objects is essential in image analysis. The recurrence of similar objects should not be ignored in association analysis. Third, to find the associations between the spatial relationships and multimedia images can be used to discover object associations and correlations. With the associations between multimedia objects, we can treat every image as a transaction and find commonly occurring patterns among different images.
Next TopicCorrelation Analysis in Data Mining
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








