| |

What is Outlier in data miningWhenever we talk about data analysis, the term outliers often come to our mind. As the name suggests, "outliers" refer to the data points that exist outside of what is to be expected. The major thing about the outliers is what you do with them. If you are going to analyze any task to analyze data sets, you will always have some assumptions based on how this data is generated. If you find some data points that are likely to contain some form of error, then these are definitely outliers, and depending on the context, you want to overcome those errors. The data mining process involves the analysis and prediction of data that the data holds. In 1969, Grubbs introduced the first definition of outliers. Difference between outliers and noiseAny unwanted error occurs in some previously measured variable, or there is any variance in the previously measured variable called noise. Before finding the outliers present in any data set, it is recommended first to remove the noise. Types of OutliersOutliers are divided into three different types

Global OutliersGlobal outliers are also called point outliers. Global outliers are taken as the simplest form of outliers. When data points deviate from all the rest of the data points in a given data set, it is known as the global outlier. In most cases, all the outlier detection procedures are targeted to determine the global outliers. The green data point is the global outlier. 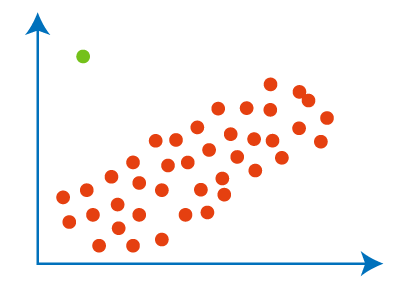
Collective OutliersIn a given set of data, when a group of data points deviates from the rest of the data set is called collective outliers. Here, the particular set of data objects may not be outliers, but when you consider the data objects as a whole, they may behave as outliers. To identify the types of different outliers, you need to go through background information about the relationship between the behavior of outliers shown by different data objects. For example, in an Intrusion Detection System, the DOS package from one system to another is taken as normal behavior. Therefore, if this happens with the various computer simultaneously, it is considered abnormal behavior, and as a whole, they are called collective outliers. The green data points as a whole represent the collective outlier. 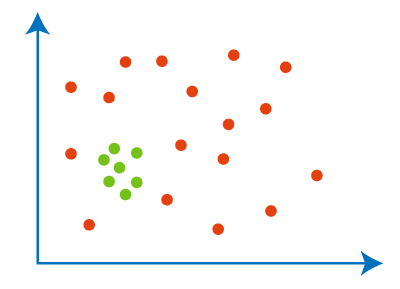
Contextual OutliersAs the name suggests, "Contextual" means this outlier introduced within a context. For example, in the speech recognition technique, the single background noise. Contextual outliers are also known as Conditional outliers. These types of outliers happen if a data object deviates from the other data points because of any specific condition in a given data set. As we know, there are two types of attributes of objects of data: contextual attributes and behavioral attributes. Contextual outlier analysis enables the users to examine outliers in different contexts and conditions, which can be useful in various applications. For example, A temperature reading of 45 degrees Celsius may behave as an outlier in a rainy season. Still, it will behave like a normal data point in the context of a summer season. In the given diagram, a green dot representing the low-temperature value in June is a contextual outlier since the same value in December is not an outlier. 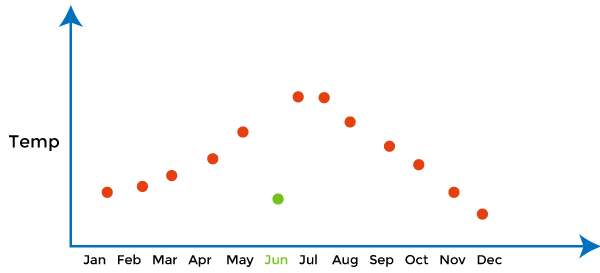
Outliers AnalysisOutliers are discarded at many places when data mining is applied. But it is still used in many applications like fraud detection, medical, etc. It is usually because the events that occur rarely can store much more significant information than the events that occur more regularly. Other applications where outlier detection plays a vital role are given below. Any unusual response that occurs due to medical treatment can be analyzed through outlier analysis in data mining.
The process in which the behavior of the outliers is identified in a dataset is called outlier analysis. It is also known as "outlier mining", the process is defined as a significant task of data mining.
Next TopicData Cleaning in Data Mining
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








