| |

Different types of Clustering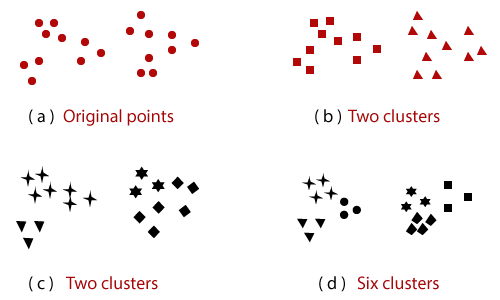
Cluster Analysis separates data into groups, usually known as clusters. If meaningful groups are the objective, then the clusters catch the general information of the data. Some time cluster analysis is only a useful initial stage for other purposes, such as data summarization. In the case of understanding or utility, cluster analysis has long played a significant role in a wide area such as biology, psychology, statistics, pattern recognition machine learning, and mining. What is Cluster Analysis?Cluster analysis is the group's data objects that primarily depend on information found in the data. It defines the objects and their relationships. The objective of the objects within a group be similar or different from the objects of the other groups. The given Figure 1 illustrates different ways of Clustering at the same sets of the point. In various applications, the concept of a cluster is not briefly defined. To better understand the challenge of choosing what establishes a group, figure 1 illustrates twenty points and three different ways to separate them into clusters. The design of the markers shows the cluster membership. The figures divide the data into two and six sections, respectively. The division of each of the two more significant clusters into three subclusters may be a product of the human visual system. It may not be logical to state that the points from four clusters. The figure represents that the meaning of a cluster is inaccurate. The best definition of cluster relies upon the nature of the data and the outcomes. Cluster analysis is similar to other methods that are used to divide data objects into groups. For example, Clustering can be view as a form of Classification. It constructs the labeling of objects with Classification, i.e., new unlabeled objects are allowed a class label using a model developed from objects with known class labels. So that, cluster analysis is sometimes defined as unsupervised Classification. If the term classification is used without any ability within data mining, then it typically refers to supervised Classification. The terms segmentation and partitioning are generally used as synonyms for Clustering. These terms are commonly used for techniques outside the traditional bounds of cluster analysis. For example, the term partitioning is usually used in making relation with techniques that separate graphs into subgraphs and that are not connected to Clustering. Segmentation often introduces the division of data into groups using simple methods. For example, an image can be broken into various sections depends on pixel frequency and color, or people can be divided into different groups based on their annual income. However, some work in graph division and market segmentation is connected to cluster analysis. Different types of ClusteringA whole group of clusters is usually referred to as Clustering. Here, we have distinguished different kinds of Clustering, such as Hierarchical(nested) vs. Partitional(unnested), Exclusive vs. Overlapping vs. Fuzzy, and Complete vs. Partial.
The most frequently discussed different features among various types of Clustering is whether the clusters sets are nested or unnested, or in more conventional terminology, partitional or hierarchical. A partitional Clustering is usually a distribution of the set of data objects into non-overlapping subsets (clusters) so that each data object is in precisely one subset. If we allow clusters to have subclusters, then we get a hierarchical Clustering, which is a group of nested clusters that are organized as a tree. Each node (cluster) in the tree (Not for the leaf nodes) is the association of its subclusters, and the tree roots are the cluster, including all the objects. Usually, the leaves of the tree are individual clusters of individual data objects. If we enable the cluster to be nested, then one clarification of figure 1 ( a) is that it has two subclusters figure 1 (b) illustrates this, each of which has three subclusters shown in figure 1 (d). The clusters have appeared in figure 1 (a-d) when taken in a specific order, also from a hierarchical (nested) Clustering, 1, 2, 4, and 6 clusters on each level. Finally, a hierarchical Clustering can be seen as an arrangement of partitional Clustering, and a partitional Clustering can be acquired by taking any member of that sequence, it means by cutting the hierarchical tree at the specific level.
The Clustering that appeared in the figure is all exclusive, as they give the responsibility to each object to a single cluster. There are numerous circumstances in which a point could sensibly be set in more than one cluster, and these circumstances are better addressed by non-exclusive Clustering. In general terms, an overlapping or non-exclusive Clustering is used to reflect the fact that an object can together belong to more than one group (class). For example, a person at a company can be both a trainee student and an employee of the company. A non-exclusive Clustering is also usually used if an object is "between" two or more then two clusters and could sensibly be allocated to any of these clusters. Consider a point somewhere between two of the clusters rather than make an entirely random task of the object to a single cluster. it is put in all of the clusters to "equally good" clusters. In fuzzy Clustering, each object belongs to each cluster with a membership weight that is between 0 and 1. In other words, clusters are considered as fuzzy sets. Mathematically, a fuzzy set is defined as one in which an object is associated with any set with a weight that ranges between 0 and 1. In fuzzy Clustering, we usually set the additional constraint, and the sum of weights for each object must be equal to 1. Similarly, probabilistic Clustering systems compute the probability in which each point belongs to a cluster, and these probabilities must sum to 1. Since the membership weights or probabilities for any object sum to 1, a fuzzy or probabilistic Clustering doesn't address actual multiclass situations. Complete versus PartialA complete Clustering allocates each object to a cluster, whereas partial Clustering does not. The inspiration for a partial Clustering is that a few objects in a data set may not belong to distinct groups. Most of the time, objects in the data set may produce outliers, noise, or "uninteresting background." For example, some news headlines stories may share a common subject, such that " Industrial production shrinks globally by 1.1 percent," While different stories are more frequent or one-of-a-kind. Consequently, to locate the significant topics in the last month's stories, we might need to search only for clusters of documents that are firmly related by a common subject. In other cases, a complete Clustering of objects is desired. For example, an application that utilizes Clustering to sort out documents for browsing needs to ensure that all documents can be browsed. Different types of ClustersClustering addresses to discover helpful groups of objects (Clusters), where the objectives of the data analysis characterize utility. Of course, there are various notions of a cluster that demonstrate utility in practice. In order to visually show the differences between these kinds of clusters, we utilize two-dimensional points, as shown in the figure that types of clusters described here are equally valid for different sorts of data.
A cluster is a set of objects where each object is closer or more similar to every other object in the cluster. Sometimes a limit is used to indicate that all the objects in a cluster must be adequately close or similar to each other. The definition of a cluster is satisfied only when the data contains natural clusters that are quite far from one another. The figure illustrates an example of well-separated clusters that comprise of two points in a two-dimensional space. Well-separated clusters do not require to be spherical but can have any shape. 
A cluster is a set of objects where each object is closer or more similar to the prototype that characterizes the cluster to the prototype of any other cluster. For data with continuous characteristics, the prototype of a cluster is usually a centroid. It means the average (Mean) of all the points in the cluster when a centroid is not significant. For example, when the data has definite characteristics, the prototype is usually a medoid that is the most representative point of a cluster. For some sorts of data, the model can be viewed as the most central point, and in such examples, we commonly refer to prototype-based clusters as center-based clusters. As anyone might expect, such clusters tend to be spherical. The figure illustrates an example of center-based clusters. 
If the data is depicted as a graph, where the nodes are the objects, then a cluster can be described as a connected component. It is a group of objects that are associated with each other, but that has no association with objects that is outside the group. A significant example of graph-based clusters is contiguity-based clusters, where two objects are associated when they are placed at a specified distance from each other. It suggests that every object in a contiguity-based cluster is the same as some other object in the cluster. Figures demonstrate an example of such clusters for two-dimensional points. The meaning of a cluster is useful when clusters are unpredictable or intertwined but can experience difficulty when noise present. It is shown by the two circular clusters in the figure; the little extension of points can join two different clusters. Other kinds of graph-based clusters are also possible. One such way describes a cluster as a clique. Clique is a set of nodes in a graph that is completely associated with each other. Particularly, we add connections between the objects according to their distance from one another. A cluster is generated when a set of objects forms a clique. It is like prototype-based clusters, and such clusters tend to be spherical. 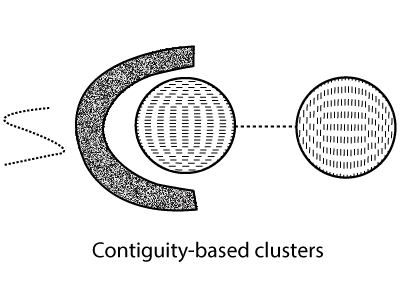
A cluster is a compressed domain of objects that are surrounded by a region of low density. The two spherical clusters are not merged, as in the figure, because the bridge between them fades into the noise. Similarly, the curve that is present in the Figure disappears into the noise and does not form a cluster in Figure. It also disappears into the noise and does not form a cluster shown in the figure. A density-based definition of a cluster is usually occupied when the clusters are irregularly and intertwined, and when noise and outliers exist. The other hand contiguity-based definition of a cluster would not work properly for the data of Figure. Since the noise would tend to form a network between clusters. 

We can describe a cluster as a set of objects that offer some property. The object in a center-based cluster shares the property that they are all closest to the similar centroid or medoid. However, the shared-property approach additionally incorporates new types of the cluster. Consider the cluster given in the figure. A triangular area (cluster) is next to a rectangular one, and there are two intertwined circles (clusters). In both cases, a Clustering algorithm would require a specific concept of a cluster to recognize these clusters effectively. The way of discovering such clusters is called conceptual Clustering.
Next TopicBitcoin Data Mining
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








