| |

Stemming in Data MiningStemming is the process of producing morphological variants of a root/base word. Stemming programs are commonly referred to as stemming algorithms or stemmers. Stemming reduces the word to its word stem means affixes to suffixes and prefixes, or the roots of words known as a lemma. Stemming is important in natural language understanding (NLU) and natural language processing (NLP). Stemming is a part of linguistic studies in morphology and artificial intelligence (AI) information retrieval and extraction. Stemming is also a part of queries and Internet search engines. Stemming and AI knowledge extract meaningful information from vast sources like big data or the Internet since additional word forms related to a subject may need to be searched to get the best results. When a new word is found, it can present new research opportunities. Often, the best results can be attained by using the basic morphological form of the word: the lemma. To find the lemma, stemming is performed by an individual or algorithm that an AI system may use. Stemming uses many approaches to reduce a word to its base from whatever inflected form is encountered. It can be simple to develop a stemming algorithm. Some simple algorithms will strip recognized prefixes and suffixes. However, these simple algorithms are prone to error. For example, an error can reduce words like laziness to lazi instead of lazy. Such algorithms may also have difficulty with terms whose inflectional forms don't perfectly mirror the lemma. History of StemmingJulie Beth Lovins wrote the first published stemmer in 1968. This article was groundbreaking in its day and had a significant effect on subsequent efforts in this field. Her paper refers to three previous major attempts at stemming algorithms:
Martin Porter wrote a further stemmer, published in the July 1980 edition of the journal Program. This stemmer was extensively used and eventually became the de facto norm for English stemming. In 2000, Dr. Porter was honored with the Tony Kent Strix prize for his stemming and information retrieval work. Why is Stemming Important?As previously stated, the English language has several variants of a single term. These variances in a text corpus result in data redundancy when developing NLP or machine learning models. Such models may be ineffective. It is essential to normalize text by removing repetition and transforming words to their base form through stemming from building a robust model. Errors in StemmingThere are mainly two errors in stemming, such as:
Applications of StemmingHere are the following applications of stemming, such as:
Classification of Stemming AlgorithmsAll stemming algorithms differ in respect to performance and accuracy. Stemming algorithms can be classified into truncating, statistical, and mixed methods. Each of these groups has a typical way of finding the stems of the word variants. 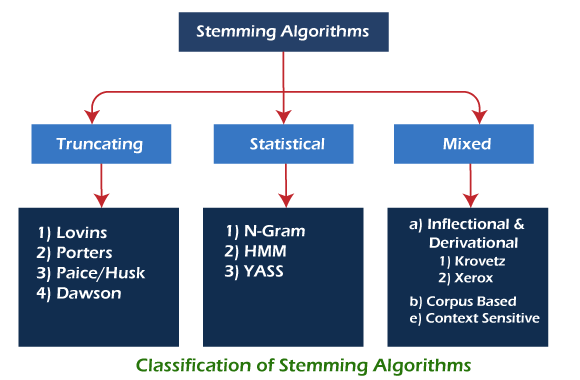
1. Truncating or Affix Removal MethodsAs the name suggests, these methods are related to removing the suffixes or prefixes of a word. The most basic stemmer was the Truncate (n) stemmer which truncated a word at the nth symbol, i.e., keep n letters and remove the rest. In this method, words shorter than n are kept as it is. The chances of over stemming increase when the word length is small. Another simple approach was the S-stemmer, which is an algorithm conflating singular and plural forms of English nouns. The algorithm has rules to remove suffixes in plurals to convert them to singular forms. Lovins Stemmer The Lovins algorithm is bigger than the Porter algorithm because of its very extensive endings list. Lovins proposed it in 1968 that removes the longest suffix from a word, and then the word is recorded to convert this stem into valid words. The main advantage of Lovins stemmer is it is faster. It has effectively traded space for time, and with its large suffix set, it needs just two major steps to remove a suffix, compared with the eight of the Porter algorithm. The Lovins stemmer has 294 endings, 29 conditions, and 35 transformation rules. Each end is associated with one of the conditions. The longest ending is found in the first step, which satisfies its associated condition and is removed. In the second step, the 35 rules are applied to transform the ending. The second step is done whether or not an ending is removed in the first step. For example: sitting -> sitt -> sit Advantage: It is fast and handles irregular plurals like 'teeth' and 'tooth' etc. Limitation: It is time and data-consuming. It is sometimes highly unreliable and frequently fails to form words from the stems or match the stems of like-meaning words. Furthermore, many suffixes are not available in the table of endings. Porter's Stemmer algorithm This stemmer is known for its speed and simplicity. It is one of the most popular stemming methods proposed in 1980. It is based on the idea that the suffixes in the English language are made up of a combination of smaller and simpler suffixes. Its main concern is removing the common endings to words so that they can be resolved to a common form. The main applications of Porter Stemmer include data mining and Information retrieval. However, its applications are only limited to English words. Also, the group of stems is mapped onto the same stem, and the output stem is not necessarily a meaningful word. The algorithms are fairly lengthy and are known to be the oldest stemmer. Typically, it's a basic stemmer, but it's not advised to use it for any production or complex application. Instead, it has its place in research as a basic stemming algorithm that can guarantee reproducibility. For example, EED -> EE means "if the word has at least one vowel and consonant plus EED ending, change the ending to EE" as 'agreed' becomes 'agree'. Advantage: It produces the best output as compared to other stemmers, and it has less error rate. Limitation: Morphological variants produced are not always real words. Paice/Husk Stemmer The Paice/Husk stemmer is an iterative algorithm with one table containing about 120 rules indexed by the last letter of a suffix. Each rule specifies either a deletion or replacement of an ending. On each iteration, it tries to find an applicable rule by the last character of the word. If there is no such rule, it terminates. It also terminates if a word starts with a vowel and only two letters are left or if a word starts with a consonant and only three characters are left. Otherwise, the rule is applied, and the process repeats. Advantage: It is simple, and every iteration takes care of both deletion and replacement as per the rule applied. Limitation: It is a very heavy algorithm, and over stemming may occur. Dawson Stemmer This stemmer extends the Lovins approach, except it covers a more comprehensive list of about 1200 suffixes. Like Lovins, it is a single pass stemmer and is pretty fast. The suffixes are stored in the reversed order indexed by their length and last letter. They are organized as a set of branched character trees for rapid access. Advantage: It is fast execution, covers more suffice, and produces a more accurate stemming output. Limitation: It is very complex to implement and lacks a standard reusable implementation. 2. Statistical MethodsThese are the stemmers that are based on statistical analysis and techniques. Most of the methods remove the affixes after implementing some statistical procedure. N-Gram Stemmer This is a very interesting method, and it is language-independent. Over here string-similarity approach is used to convert word inflation to its stem. An n-gram is a string of n, usually adjacent, characters extracted from a section of continuous text. To be precise, an n-gram is a set of n consecutive characters extracted from a word. The main idea behind this approach is that similar words will have a high proportion of n-grams in common. Some stemming techniques use the n-gram context to choose the correct stem for a word. For n equals 2 or 3, the words extracted are digrams or trigrams. For example: 'INTRODUCTIONS' for n=2 becomes : *I, IN, NT, TR, RO, OD, DU, UC, CT, TI, IO, ON, NS, S* And for n=3 becomes: **I, *IN, INT, NTR, TRO, ROD, ODU, DUC, UCT, CTI, TIO, ION, ONS, NS*, S** Where '*' denotes a padding space, there are n+1 such diagrams and n+2 such trigrams in a word containing n characters. Most stemmers are language-specific. Generally, a value of 4 or 5 is selected for n. After that, textual data or document is analyzed for all the n-grams. It is obvious that a word root generally occurs less frequently than its morphological form. This means a word generally has an affix associated with it. A typical statistical analysis based on the inverse document frequency (IDF) can be used to identify them. Advantage: It is based on string comparisons, and it is language-dependent, and hence very useful in many applications. Limitation: It requires a significant amount of memory and storage to create and store the n-grams and indexes. Hence, it is not time efficient or not a very practical approach. HMM Stemmer This stemmer is based on the Hidden Markov Model (HMMs) concept, finite-state automata where probability functions rule transitions between states. The new state emits a symbol with a given probability at each transition. To apply HMMs to stemming, a sequence of letters that forms a word can be considered the result of a concatenation of two subsequences: a prefix and a suffix. The probability of each path can be computed, and the most probable path is found using the Viterbi coding in the automata graph. This method is based on unsupervised learning and does not need prior linguistic knowledge of the dataset. Transitions between states define the word-building process. A way to model this process is through an HMM where the states are divided into two disjoint sets: the initial can be the stems only, and the latter can be the stems or suffixes. Some assumptions can be made in this method:
For any word, the most probable path from initial to final states will produce the split point (a transition from roots to suffixes). Then the sequence of characters before this point can be considered a stem. Advantage: It is unsupervised, so knowledge of the language is not required. Limitation: It is a little complex and may over stem the words sometimes. YASS Stemmer The name is an acronym for Yet Another Suffix Striper. This stemmer comes under the category of statistical as well as corpus-based. It does not rely on linguistic expertise. The performance of a stemmer generated by clustering a lexicon without any linguistic input is comparable to that obtained using standard, rule-based stemmers such as Porters. Retrieval experiments by the authors on English, French, and Bengali datasets show that the proposed approach is effective for languages that are primarily suffixing in nature. The clusters are created using hierarchical approach and distance measures. Then the resulting clusters are considered equivalence classes and their centroids as the stems. 3. Inflectional and Derivational MethodsThis is another approach to stemming, and it involves both the inflectional and the derivational morphology analysis. In inflectional, the word variants are related to specific language syntactic variations like a plural, gender, case, etc. In derivational, the word variants are related to the part-of-speech (POS) of a sentence where the word occurs. The corpus should be very large to develop these types of stemmers, and hence they are part of corpus base stemmers. Krovetz Stemmer (KSTEM) The Krovetz stemmer was presented in 1993 by Robert Krovetz and is a linguistic lexical validation stemmer. Since it is based on the inflectional property of words and the language syntax, it isn't very easy in nature. It effectively and accurately removes inflectional suffixes in three steps:
The conversion process first removes the suffix and then, through checking in a dictionary for any recoding, returns the stem to a word. The dictionary lookup also performs any transformations required due to spelling exceptions and converts any stem produced into a real word, whose meaning can be understood. The strength of the derivational and inflectional analysis is in their ability to produce morphologically correct stems, cope with exceptions, and process prefixes and suffixes. Since this stemmer does not find the stems for all word variants, it can be used as a prestemmer before applying a stemming algorithm. This would increase the speed and effectiveness of the main stemmer. This is a very light stemmer compared to Porter and Paice / Husk. The major and obvious flaw in dictionary-based algorithms is their inability to cope with words that are not in the lexicon. The Krovetz stemmer attempts to increase accuracy and robustness by treating spelling errors and meaningless stems. If the input document size is large, this stemmer becomes weak and does not perform very effectively. Also, a lexicon must be manually created in advance, which requires significant effort. This stemmer does not consistently produce a good recall and precision performance. Xerox Inflectional and Derivational Analyzer The linguistics groups at Xerox have developed several linguistic tools for English which can be used in information retrieval. They have produced an English lexical database that provides a morphological analysis of any word in the lexicon and identifies the base form. Xerox linguists have also developed a lexical database for English and some other languages to analyze and generate inflectional and derivational morphology. The inflectional database reduces each surface word to the form which can be found in the dictionary, as follows:
The derivational database reduces surface forms to stems related to the original in both form and semantics. For example, 'government' stems to 'govern' while 'department' is not reduced to 'depart' since the two forms have different meanings. All items are valid English terms, and irregular forms are handled correctly. Unlike most conventional stemming algorithms, the derivational process uses suffix and prefix removal, relying solely on suffix removal. A sample of the suffixes and prefixes that are removed is given below: Suffixes: ly, ness, ion, size, ant, ent, ic, al, Ic, ical, able, ance, ary, ate, ce, y, dom, ee, er, ence, ency, ery, ess, ful, hood, ible, icity, ify, ing, ish, ism, ist, istic, ity, ive, less, let, like, ment, ory, ous, ty, ship, some, ure Prefixes: anti, bi, co, contra, counter, de, di, dis, en, extra, in, inter, intra, micro, mid, mini, multi, non, over, para, poly, post, pre, pre, re, semi, sub, super, supra, sur, trans, tn, ultra, un Corpus-Based Stemmer Corpus-based stemming using co-occurrence of word variants. They have suggested an approach that tries to overcome some of the drawbacks of Porter's stemmer. For example, the words 'policy' and 'police' are conflated though they have different meanings, the words 'index' and 'indices' are not conflated though they have the same root. Porter stemmer also generates stems that are not real words like 'iteration' becomes 'iter', and 'general' becomes 'gener'. Another problem is that while some stemming algorithms may be suitable for one corpus, they will produce too many errors on another. Corpus-based stemming refers to the automatic modification of conflation classes - words that have resulted in a common stem to suit the characteristics of a given text corpus using statistical methods. The basic hypothesis is that word forms that should be conflated for a given corpus will co-occur in documents from that corpus. Using this concept, some of them over stemming or under stemming drawbacks are resolved, e.g., 'policy' and 'police' will no longer be conflated. To determine the significance of word form co-occurrence, the statistical measure used in Em(a, b) = nab / (na + nb) Where, a and b are a pair of words, na, and nb is the number of occurrences of a and b in the corpus, nab is the number of times both a and b fall in a text window of size win in the corpus (they co-occur). The way this stemmer works is first to use the Porter stemmer to identify the stems of conflated words, and then the next step is to use the corpus statistics to redefine the conflation. Sometimes, the Krovetz stemmer (KSTEM) and Porter stemmer are used in the initial step to ensure that word conflations are not missed. Advantage: It can potentially avoid making inappropriate conflations for a given corpus, and the result is an actual word and not an incomplete stem. Limitation: You need to develop the statistical measure for every corpus separately. The processing time increases as in the first step, and two stemming algorithms are first used before using this method. Context-Sensitive Stemmer In this method, stemming is done before indexing a document. Over here, for a Web Search, context-sensitive analysis is done using statistical modeling on the query side. Basically, for the words of the input query, the morphological variants which would be useful for the search are predicted before the query is submitted to the search engine. This dramatically reduces the number of bad expansions, reducing the cost of additional computation and improving precision simultaneously. After the predicted word variants from the query have been derived, context-sensitive document matching is done for these variants. This conservative strategy serves as a safeguard against spurious stemming, and it turns out to be very important for improving precision. This stemming process is divided into four steps after the query is fired:
Because queries and documents may not represent the intent the same way, this proximity constraint allows variant occurrences within a fixed-size window. The smaller the window size is, the more restrictive the matching. Advantage: It improves selective word expansion on the query side and conservative word occurrence matching on the document side. Limitation: The processing time and the complex nature of the stemmer. There can be errors finding the noun phrases in the query and the proximity words.
Next TopicFeature Transformation in Data Mining
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








