| |

Entity Identification Problem in Data MiningNowadays, data mining is used in almost all places where a large amount of data is stored and processed. Data Integration is one of the major tasks of data preprocessing. Integrating multiple databases or data files into a single store of identical data is known as Data Integration. Data Integration is usually performed to create data sets for machine learning algorithms and to predict the statistical information from the data during the data mining. We integrate data from various resources like banking transactions, invoices, customer records, Twitter, blog postings, image, audio or video data, electronic data interchange (EDI) files, spreadsheets, and sensor data. Data mining often requires data integration, merging data from multiple data stores, which combines data from multiple sources into a coherent data store, as in data warehousing. These sources may include multiple databases, data cubes, or flat files. There are many issues to consider during data integration, like Schema integration and object matching. So careful integration can help reduce and avoid redundancies and inconsistencies in the resulting data set. This can help improve the accuracy and speed of the subsequent data mining process. The semantic heterogeneity and structure of data pose great challenges in data integration. How can we match schema and objects from different sources? Or How can equivalent real-world entities from multiple data sources be matched up? This problem is known as the entity identification problem. Issues in Data IntegrationHere are the following issues in data integration, such as: 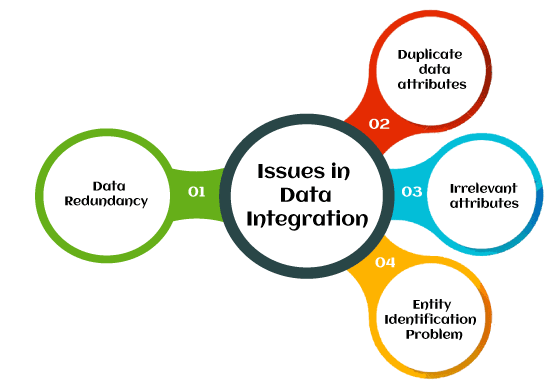
1. Data redundancy Redundant data occurs while we merge data from multiple databases. If the redundant data is not removed, incorrect results will be obtained during data analysis. Redundant data occurs due to the following reasons.
2. Duplicate data attributes Duplicates are usually present in the information in one or more other attributes. 3. Irrelevant attributes Some attributes in the data are not important, and they are not considered while performing the data mining tasks. For example, students' ID is often irrelevant to the task of predicting students' GPA . There is no use in having such irrelevant attributes in the data. 4. Entity Identification Problem Entity Identification Problem occurs during the data integration. While integrating data from multiple resources, some data resources match each other, becoming reductant if they are integrated. Equivalent real-world entities from multiple data sources matched up are referred to as this problem. For example: A.cust-id =B.cust-number. Here A, B are two different database tables. Cust-id is the attribute of table A,cust-number is the attribute of table B. Here cust-id and cust-number are attributes of different tables, and there is no relationship between these tables, but the cust-id attribute and cust-number attribute are taking the same values. This is an example of an Entity Identification Problem in the relation. Meta Data can be used to avoid errors in such schema integration. This ensures that the source system's functional dependencies and referential constraints match the target system. Entity Identification Problem helps in detecting and resolving data value conflicts. Data is usually collected from multiple resources into a coherent store, and it can be of different dimensions and datatypes. There are different representations of data and different scales of data. Entity identification problems can occur in both virtual and actual database integration.
In a single database context, it is usually the case that an object instance can uniquely model a real-world entity. This property does not hold for multiple autonomous databases, and the problem of entity identification therefore arises. For example, when we add two object instances to a relation in a single database, the one-to-one correspondence between object instances and real-world entities assures that the two new object instances refer to distinct real-world entities. However, when the two object instances are added to relations in different databases, such one-to-one correspondence property may disappear. Pre-existing databases in most organizations are defined and populated by different people at different times in response to different organizational or end-user requirements. Such independent development of databases often results in two databases capturing parts of the same real-world domain. Typically, when there is a need to provide integrated access to these related databases, relating the representations of the same real-world entity from the two databases is often difficult, if not impossible, without specifying additional semantic information that resolves this ambiguity. Entity Identification in Database IntegrationThe task of integrating pre-existing autonomous databases has to resolve the logical heterogeneity that arises when the participating databases are designed independently of one another. Logical heterogeneity can occur at two levels, namely, schema level and instance level. The resolution of schema level heterogeneity is known as schema integration. The resolution of instance-level heterogeneity is known as instance integration. 1. Schema Level The meta-data information of the participating databases, equally applicable to all instances, is incompatible. The incompatibility problems at this level include:
2. Instance Level The schemas are compatible in structure (attribute domains), and semantics (attribute meaning), but the instances corresponding to the same real-world entity have yet to be identified and merged. The two problems that occur at this level are:
Schema level homonym and synonym problems are usually resolved at the schema integration stage. In the case of actual database integration, the instance level problems must be resolved subsequently to complete the integration process. In the case of virtual database integration, the strategies and information required for resolving instance-level problems have to be specified during design time, i.e., the schema integration phase, but the actual processing only takes place during the query time. Instance integration may have to be performed whenever updating is done on the participating databases. Because entity identification is the first problem to be tackled in instance integration, effective and efficient approaches to handle it are necessary. ApproachesThe existing approaches to entity identification can be categorized as follows: 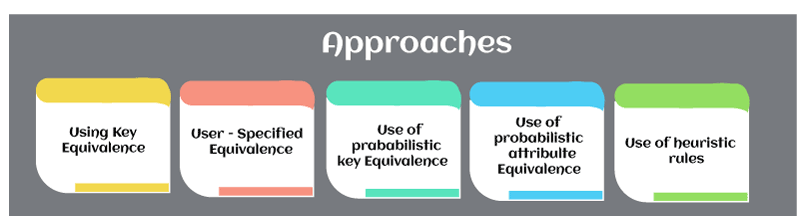
1. Using key equivalence: Many approaches assume some common key exists between relations from different databases modeling the same entity type, e.g., Multibase. Because a key can be used for uniquely associating object instances with real-world entities, the equivalence of values of the common key can be used to resolve the problem. This approach, however, is limited because the relations may have no common key, even though they might share some common key attributes. 2. User-specified equivalence: This approach requires the user to specify equivalence between object instances, e.g., as a table that maps local object ids to global object ids, i.e., the responsibility of matching the object instance is assigned to the user. Because the matching table can be very large, this approach can potentially be extremely cumbersome. Nevertheless, it is a general approach and can handle synonym and homonym problems. This technique has been suggested for the Pegasus project. 3. Use of probabilistic key equivalence: Instead of insisting on full key equivalence, Pu suggested matching object instances using only a portion of the key values in the restricted domain. As an instance of the key equivalence, the name matching problem has been addressed by matching the subfields of names. If most of the subfields in two given names match, the names are considered to be identical. Although this approach can produce high confidence in the matching result, it applies only when a common key exists between relations. The probabilistic nature of matching may also admit erroneous matching. 4. Probabilistic attribute equivalence: Chatterjee and Segev proposed using all common attributes between two relations to determine entity equivalence. A comparison value is assigned based on a probabilistic model for each pair of records from two relations. 5. Using heuristic rules: Wang and Madnick attacked the problem using a knowledge-based approach. A set of heuristic rules is used to infer additional information about the object instances to be matched. Because the knowledge used is heuristic in nature, the matching result produced may not be correct. Solution of Entity Identification ProblemWe propose a new approach to solve the entity identification problem. This approach differs from previous approaches in the following aspects:
Next TopicNumerosity Reduction in Data Mining
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








