| |

Data Cleaning in Data MiningData cleaning is an essential step in the data mining process. It is crucial to the construction of a model. The step that is required, but frequently overlooked by everyone, is data cleaning. The major problem with quality information management is data quality. Problems with data quality can happen at any place in an information system. Data cleansing offers a solution to these issues. Data cleaning is the process of correcting or deleting inaccurate, damaged, improperly formatted, duplicated, or insufficient data from a dataset. Even if results and algorithms appear to be correct, they are unreliable if the data is inaccurate. There are numerous ways for data to be duplicated or incorrectly labeled when merging multiple data sources. In general, data cleaning lowers errors and raises the caliber of the data. Although it might be a time-consuming and laborious operation, fixing data mistakes and removing incorrect information must be done. A crucial method for cleaning up data is data mining. A method for finding useful information in data is data mining. Data quality mining is a novel methodology that uses data mining methods to find and fix data quality issues in sizable databases. Data mining mechanically pulls intrinsic and hidden information from large data sets. Data cleansing can be accomplished using a variety of data mining approaches. To arrive at a precise final analysis, it is crucial to comprehend and improve the quality of your data. To identify key patterns, the data must be prepared. Exploratory data mining is understood. Before doing business analysis and gaining insights, data cleaning in data mining enables the user to identify erroneous or missing data. Data cleaning before data mining is often a time-consuming procedure that necessitates IT personnel to assist in the initial step of reviewing your data due to how time-consuming data cleaning is. But if your final analysis is inaccurate or you get an erroneous result, it's possible due to poor data quality. Steps for Cleaning DataYou can follow these fundamental stages to clean your data even if the techniques employed may vary depending on the sorts of data your firm stores: 1. Remove duplicate or irrelevant observationsRemove duplicate or pointless observations as well as undesirable observations from your dataset. The majority of duplicate observations will occur during data gathering. Duplicate data can be produced when you merge data sets from several sources, scrape data, or get data from clients or other departments. One of the most important factors to take into account in this procedure is de-duplication. Those observations are deemed irrelevant when you observe observations that do not pertain to the particular issue you are attempting to analyze. You might eliminate those useless observations, for instance, if you wish to analyze data on millennial clients but your dataset also includes observations from earlier generations. This can improve the analysis's efficiency, reduce deviance from your main objective, and produce a dataset that is easier to maintain and use. 2. Fix structural errorsWhen you measure or transfer data and find odd naming practices, typos, or wrong capitalization, such are structural faults. Mislabelled categories or classes may result from these inconsistencies. For instance, "N/A" and "Not Applicable" might be present on any given sheet, but they ought to be analyzed under the same heading. 3. Filter unwanted outliersThere will frequently be isolated findings that, at first glance, do not seem to fit the data you are analyzing. Removing an outlier if you have a good reason to, such as incorrect data entry, will improve the performance of the data you are working with. However, occasionally the emergence of an outlier will support a theory you are investigating. And just because there is an outlier, that doesn't necessarily indicate it is inaccurate. To determine the reliability of the number, this step is necessary. If an outlier turns out to be incorrect or unimportant for the analysis, you might want to remove it. 4. Handle missing dataBecause many algorithms won't tolerate missing values, you can't overlook missing data. There are a few options for handling missing data. While neither is ideal, both can be taken into account, for example: Although you can remove observations with missing values, doing so will result in the loss of information, so proceed with caution. Again, there is a chance to undermine the integrity of the data since you can be working from assumptions rather than actual observations when you input missing numbers based on other observations. To browse null values efficiently, you may need to change the way the data is used. 5. Validate and QAAs part of fundamental validation, you ought to be able to respond to the following queries once the data cleansing procedure is complete:
False conclusions can be used to inform poor company strategy and decision-making as a result of inaccurate or noisy data. False conclusions can result in a humiliating situation in a reporting meeting when you find out your data couldn't withstand further investigation. Establishing a culture of quality data in your organization is crucial before you arrive. The tools you might employ to develop this plan should be documented to achieve this. Techniques for Cleaning DataThe data should be passed through one of the various data-cleaning procedures available. The procedures are explained below: 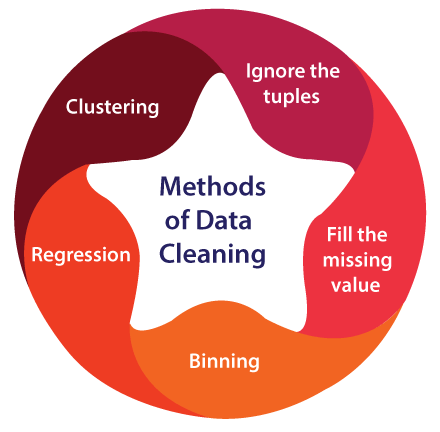
Process of Data CleaningThe data cleaning method for data mining is demonstrated in the subsequent sections.
Usage of Data Cleaning in Data Mining.The following are some examples of how data cleaning is used in data mining: 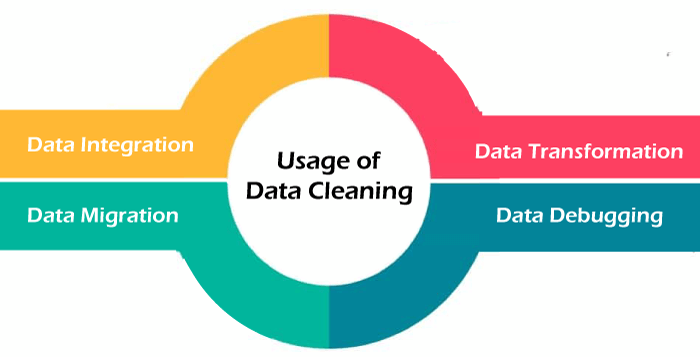
Cleaning data is essential. For instance, a retail business could receive inaccurate or duplicate data from different sources, including CRM or ERP systems. A reliable data debugging tool would find and fix data discrepancies. The deleted information will be transformed into a common format and transferred to the intended database. Characteristics of Data CleaningTo ensure the correctness, integrity, and security of corporate data, data cleaning is a requirement. These may be of varying quality depending on the properties or attributes of the data. The key components of data cleansing in data mining are as follows: 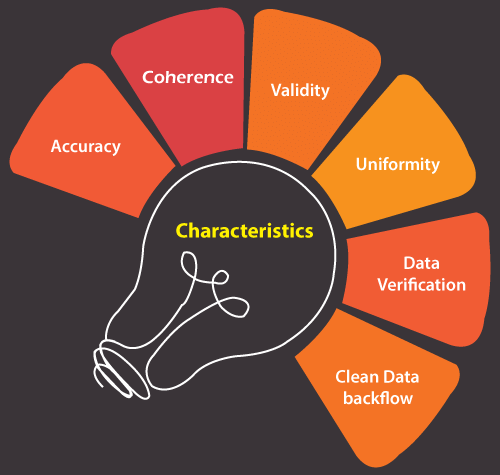
Tools for Data Cleaning in Data MiningData Cleansing Tools can be very helpful if you are not confident of cleaning the data yourself or have no time to clean up all your data sets. You might need to invest in those tools, but it is worth the expenditure. There are many data cleaning tools in the market. Here are some top-ranked data cleaning tools, such as:
Benefits of Data CleaningWhen you have clean data, you can make decisions using the highest-quality information and eventually boost productivity. The following are some important advantages of data cleaning in data mining, including:
Next TopicData Processing in Data Mining
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








