| |

Decision Tree InductionDecision Tree is a supervised learning method used in data mining for classification and regression methods. It is a tree that helps us in decision-making purposes. The decision tree creates classification or regression models as a tree structure. It separates a data set into smaller subsets, and at the same time, the decision tree is steadily developed. The final tree is a tree with the decision nodes and leaf nodes. A decision node has at least two branches. The leaf nodes show a classification or decision. We can't accomplish more split on leaf nodes-The uppermost decision node in a tree that relates to the best predictor called the root node. Decision trees can deal with both categorical and numerical data. Key factors:Entropy:Entropy refers to a common way to measure impurity. In the decision tree, it measures the randomness or impurity in data sets. 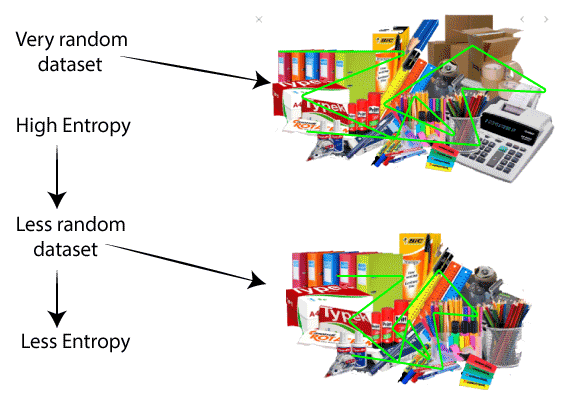
Information Gain:Information Gain refers to the decline in entropy after the dataset is split. It is also called Entropy Reduction. Building a decision tree is all about discovering attributes that return the highest data gain. 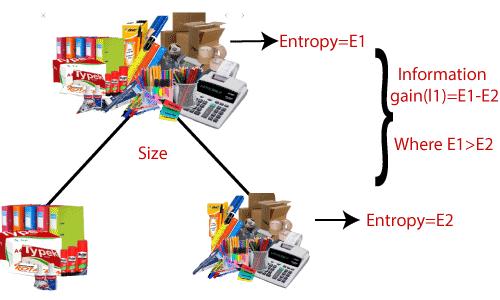
In short, a decision tree is just like a flow chart diagram with the terminal nodes showing decisions. Starting with the dataset, we can measure the entropy to find a way to segment the set until the data belongs to the same class. Why are decision trees useful?It enables us to analyze the possible consequences of a decision thoroughly. It provides us a framework to measure the values of outcomes and the probability of accomplishing them. It helps us to make the best decisions based on existing data and best speculations. In other words, we can say that a decision tree is a hierarchical tree structure that can be used to split an extensive collection of records into smaller sets of the class by implementing a sequence of simple decision rules. A decision tree model comprises a set of rules for portioning a huge heterogeneous population into smaller, more homogeneous, or mutually exclusive classes. The attributes of the classes can be any variables from nominal, ordinal, binary, and quantitative values, in contrast, the classes must be a qualitative type, such as categorical or ordinal or binary. In brief, the given data of attributes together with its class, a decision tree creates a set of rules that can be used to identify the class. One rule is implemented after another, resulting in a hierarchy of segments within a segment. The hierarchy is known as the tree, and each segment is called a node. With each progressive division, the members from the subsequent sets become more and more similar to each other. Hence, the algorithm used to build a decision tree is referred to as recursive partitioning. The algorithm is known as CART (Classification and Regression Trees) Consider the given example of a factory where 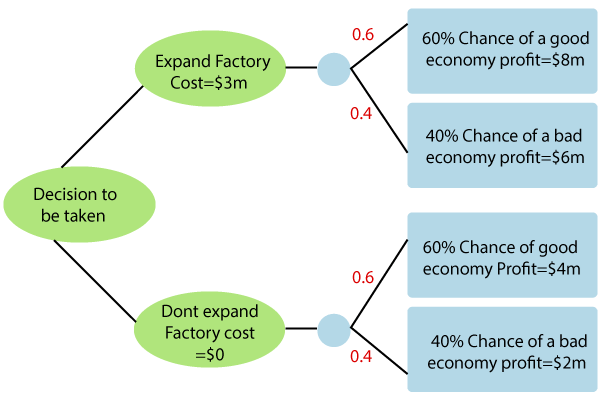
Expanding factor costs $3 million, the probability of a good economy is 0.6 (60%), which leads to $8 million profit, and the probability of a bad economy is 0.4 (40%), which leads to $6 million profit. Not expanding factor with 0$ cost, the probability of a good economy is 0.6(60%), which leads to $4 million profit, and the probability of a bad economy is 0.4, which leads to $2 million profit. The management teams need to take a data-driven decision to expand or not based on the given data. Net Expand = ( 0.6 *8 + 0.4*6 ) - 3 = $4.2M Decision tree Algorithm:The decision tree algorithm may appear long, but it is quite simply the basis algorithm techniques is as follows: The algorithm is based on three parameters: D, attribute_list, and Attribute _selection_method. Generally, we refer to D as a data partition. Initially, D is the entire set of training tuples and their related class levels (input training data). The parameter attribute_list is a set of attributes defining the tuples. Attribute_selection_method specifies a heuristic process for choosing the attribute that "best" discriminates the given tuples according to class. Attribute_selection_method process applies an attribute selection measure. Advantages of using decision trees:A decision tree does not need scaling of information. Missing values in data also do not influence the process of building a choice tree to any considerable extent. A decision tree model is automatic and simple to explain to the technical team as well as stakeholders. Compared to other algorithms, decision trees need less exertion for data preparation during pre-processing. A decision tree does not require a standardization of data.
Next TopicEducational Data Mining
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








