Data Wrangling?
These days almost anything can be a valuable source of information. The primary challenge lies in extracting the insights from the said information and making sense of it, which is the point of Big Data. However, you also need to prep the data first, which is Data Wrangling in a nutshell.
The nature of the information is that it requires a certain kind of organization to be adequately assessed. This process requires a crystal clear understanding of which operations need what sort of data. Let's look closer at wrangling data and explain why it is so important.
What is Data Wrangling?
Sometimes, data Wrangling is referred to as data munging. It is the process of transforming and mapping data from one "raw" data form into another format to make it more appropriate and valuable for various downstream purposes such as analytics. The goal of data wrangling is to assure quality and useful data. Data analysts typically spend the majority of their time in the process of data wrangling compared to the actual analysis of the data.
The process of data wrangling may include further munging, data visualization, data aggregation, training a statistical model, and many other potential uses. Data wrangling typically follows a set of general steps, which begin with extracting the raw data from the data source, "munging" the raw data (e.g., sorting) or parsing the data into predefined data structures, and finally depositing the resulting content into a data sink for storage and future use.
Wrangling the data is usually accompanied by Mapping. The term "Data Mapping" refers to the element of the wrangling process that involves identifying source data fields to their respective target data fields. While Wrangling is dedicated to transforming data, Mapping is about connecting the dots between different elements.
Importance of Data Wrangling
Some may question if the amount of work and time devoted to data wrangling is worth the effort. A simple analogy will help you understand. The foundation of a skyscraper is expensive and time-consuming before the above-ground structure starts. Still, this solid foundation is extremely valuable for the building to stand tall and serve its purpose for decades. Similarly, once the code and infrastructure foundation are gathered for data handling, it will deliver immediate results (sometimes almost instantly) for as long as the process is relevant. However, skipping necessary data wrangling steps will lead to significant downfalls, missed opportunities, and erroneous models that damage the reputation of analysis within the organization.
Data wrangling software has become an indispensable part of data processing. The primary importance of using data wrangling tools can be described as follows:
- Making raw data usable. Accurately wrangled data guarantees that quality data is entered into the downstream analysis.
- Getting all data from various sources into a centralized location so it can be used.
- Piecing together raw data according to the required format and understanding the business context of data.
- Automated data integration tools are used as data wrangling techniques that clean and convert source data into a standard format that can be used repeatedly according to end requirements. Businesses use this standardized data to perform crucial, cross-data set analytics.
- Cleansing the data from the noise or flawed, missing elements.
- Data wrangling acts as a preparation stage for the data mining process, which involves gathering data and making sense of it.
- Helping business users make concrete, timely decisions.
NOTE: Data wrangling is a somewhat demanding and time-consuming operation both from computational capacities and human resources. Data wrangling takes over half of what data scientist does.
Data Wrangling Process
Data Wrangling is one of those technical terms that are more or less self-descriptive. The term "wrangling" refers to rounding up information in a certain way. This operation includes a sequence of the following processes:
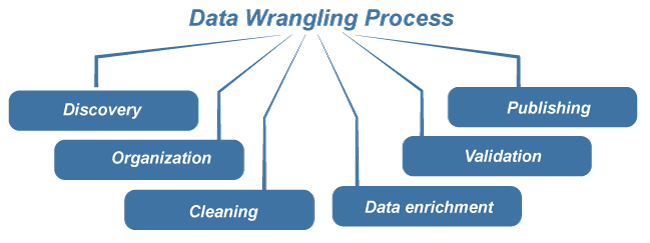
- Discovery: Before starting the wrangling process, it is critical to think about what may lie beneath your data. It is crucial to think critically about what results from you anticipate from your data and what you will use it for once the wrangling process is complete. Once you've determined your objectives, you can gather your data.
- Organization: After you've gathered your raw data within a particular dataset, you must structure your data. Due to the variety and complexity of data types and sources, raw data is often overwhelming at first glance.
- Cleaning: When your data is organized, you can begin cleaning your data. Data cleaning involves removing outliers, formatting nulls, and eliminating duplicate data. It is important to note that cleaning data collected from web scraping methods might be more tedious than cleaning data collected from a database. Essentially, web data can be highly unstructured and require more time than structured datafrom a database.
- Data enrichment: This step requires that you take a step back from your data to determine if you have enough data to proceed. Finishing the wrangling process without enough data may compromise insights gathered from further analysis. For example, investors looking to analyze product review data will want a significant amount of data to portray the market and increase investment intelligence
- Validation: After determining you gathered enough data, you will need to apply validation rules to your data. Validation rules, performed in repetitive sequences, confirm that your data is consistent throughout your dataset. Validation rules will also ensure quality as well as security. This step follows similar logic utilized in data normalization, a data standardization process involving validation rules.
- Publishing: The final step of the data munging process is data publishing. Data publishing involves preparing the data for future use. This may include providing notes and documentation of your wrangling process and creating access for other users and applications.
NOTE: Like many other data transformation processes, data wrangling is an iterative process requiring you to revisit your data regularly. To better understand the munging process, let's look at data mining, a subset of data wrangling.
Use Case of Data Wrangling
Data munging is used for diverse use-cases as follows:
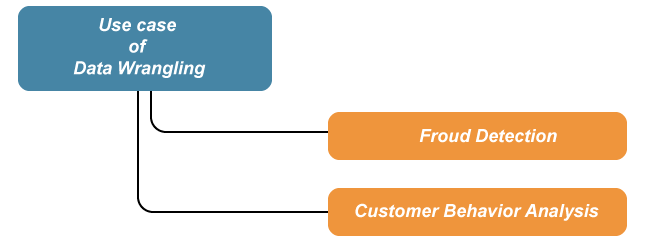
1. Fraud Detection: Using a data wrangling tool, a business can perform the following:
- Distinguish corporate fraud by identifying unusual behavior by examining detailed information like multi-party and multi-layered emails or web chats.
- Support data security by allowing non-technical operators to examine and wrangle data quickly to keep pace with billions of daily security tasks.
- Ensure precise and repeatable modeling outcomes by standardizing and quantifying structured and unstructured data sets.
- Enhance compliance by ensuring your business complies with industry and government standards by following security protocols during integration.
2. Customer Behavior Analysis: A data-munging tool can quickly help your business processes get precise insights via customer behavior analysis. It empowers the marketing team to take business decisions into their hands and make the best of them. You can use data wrangling tools to:
- Decrease the time spent on data preparation for analysis
- Quickly understand the business value of your data
- Allow your analytics team to utilize the customer behavior data directly
- Empower data scientists to discover data trends via data discovery and visual profiling.
Data Wrangling Tools
There are different tools for data wrangling that can be used for gathering, importing, structuring, and cleaning data before it can be fed into analytics and BI apps. You can use automated tools for data wrangling, where the software allows you to validate data mappings and scrutinize data samples at every step of the transformation process. This helps to detect and correct errors in data mapping quickly.
Automated data cleaning becomes necessary in businesses dealing with exceptionally large data sets. The data team or data scientist is responsible for Wrangling manual data cleaning processes. However, in smaller setups, non-data professionals are responsible for cleaning data before leveraging it.
Various data wrangling methods range from munging data with scripts to spreadsheets. Additionally, with some of the more recent all-in-one tools, everyone utilizing the data can access and utilize their data wrangling tools. Here are some of the more common data wrangling tools available.
- Spreadsheets / Excel Power Query is the most basic manual data wrangling tool.
- OpenRefine - An automated data cleaning tool that requires programming skills
- Tabula
It is a tool suited for all data types
- Google DataPrep
It is a data service that explores, cleans, and prepares data
- Data wrangler
It is a data cleaning and transforming tool
- Plotly (data wrangling with Python) is useful for maps and chart data.
- CSVKit converts data.
Benefits of Data Wrangling
As previously mentioned, big data has become an integral part of business and finance today. However, the full potential of said data is not always clear. Data processes, such as data discovery, are useful for recognizing your data's potential. But to fully unleash the power of your data, you will need to implement data. Here are some of the key benefits of data wrangling.
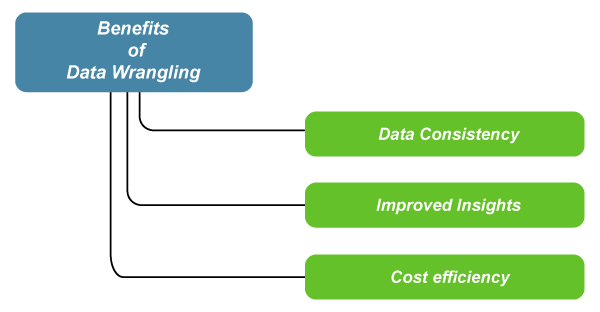
- Data consistency: The organizational aspect of data wrangling offers a resulting dataset that is more consistent. Data consistency is crucial for business operations that involve collecting data input by consumers or other human end-users. For example, if a human-end user submits personal information incorrectly, such as making a duplicate customer account, which would consequently impact further performance analysis.
- Improved insights: Data wrangling can provide statistical insights about metadata by transforming the metadata to be more constant. These insights are often the result of increased data consistency, as consistent metadata allows automated tools to analyze the data faster and more accurately. Particularly, if one were to build a model regarding projected market performance, data wrangling would clean the metadata to allow your model to run without any errors.
- Cost efficiency: As previously mentioned, because data-wrangling allows for more efficient data analysis and model-building processes, businesses will ultimately save money in the long run. For instance, thoroughly cleaning and organizing data before sending it off for integration will reduce errors and save developers time.
- Data wrangling helps to improve data usability as it converts data into a compatible format for the end system.
- It helps to quickly build data flows within an intuitive user interface and easily schedule and automate the data-flow process.
- Integrates various types of information and sources (like databases, web services, files, etc.)
- Help users to process very large volumes of data easily and easily share data-flow techniques.
Data Wrangling Formats
Depending on the type of data you are using, your final result will fall into four final formats: de-normalized transactions, analytical base table (ABT), time series, or document library. Let's take a closer look at these final formats, as understanding these results will inform the first few steps of the data wrangling process, which we discussed above.
- Transactional data: Transactional data refers to business operation transactions. This data type involves detailed subjective information about particular transactions, including client documentation, client interactions, receipts, and notes regarding any external transactions.
- Analytical Base Table (ABT): Analytical Base Table data involves data within a table with unique entries for each attribute column. ABT data is the most common business data type as it involves various data types that contribute to the most common data sources. Even more notable is that ABT data is primarily used for AI and ML, which we will examine later.
- Time-series: Time series data involves data that has been divided by a particular amount of time or data that has a relation with time, particularly sequential time. For example, tracking data regarding an application's downloads over a year or tracking traffic data over a month would be considered time series data.
- Document library: Lastly, document library data is information that involves a large amount of textual data, particularly text within a document. While document libraries contain rather massive amounts of data, automated data mining tools specifically designed for text mining can help extract entire texts from documents for further analysis.
Data Wrangling Examples
Data wrangling techniques are used for various use cases. The most commonly used examples of data wrangling are for:
- Merging several data sources into one data set for analysis
- Identifying gaps or empty cells in data and either filling or removing them
- Deleting irrelevant or unnecessary data
- Identifying severe outliers in data and either explaining the inconsistencies or deleting them to facilitate analysis
Businesses also use data wrangling tools to
- Detect corporate fraud
- Support data security
- Ensure accurate and recurring data modeling results
- Ensure business compliance with industry standards
- Perform Customer Behavior Analysis
- Reduce time spent on preparing data for analysis
- Promptly recognize the business value of your data
- Find out data trends
|

 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now








