| |

What is Boosting in Data Mining?Boosting is an ensemble learning method that combines a set of weak learners into strong learners to minimize training errors. In boosting, a random sample of data is selected, fitted with a model, and then trained sequentially. That is, each model tries to compensate for the weaknesses of its predecessor. Each classifier's weak rules are combined with each iteration to form one strict prediction rule. Boosting is an efficient algorithm that converts a weak learner into a strong learner. They use the concept of the weak learner and strong learner conversation through the weighted average values and higher votes values for prediction. These algorithms use decision stamp and margin maximizing classification for processing. 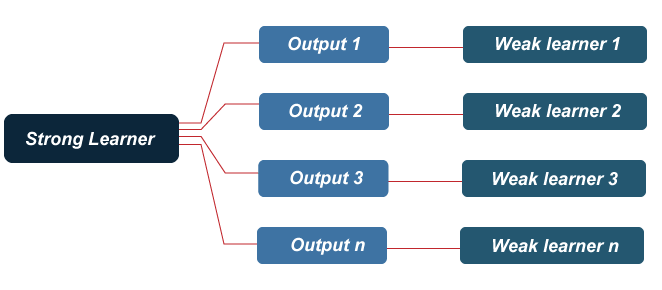
There are three types of Algorithms available such as AdaBoost or Adaptive boosting Algorithm, Gradient, and XG Boosting algorithm. These are the machine learning algorithms that follow the process of training for predicting and fine-tuning the result. Example Let's understand this concept with the help of the following example. Let's take the example of the email. How will you recognize your email, whether it is spam or not? You can recognize it by the following conditions:
The rules mentioned above are not that powerful to recognize spam or not; hence these rules are called weak learners. To convert weak learners to the strong learner, combine the prediction of the weak learner using the following methods.
Consider the 5 rules mentioned above; there are 3 votes for spam and 2 votes for not spam. Since there is high vote spam, we consider it spam. Why is Boosting Used?To solve complicated problems, we require more advanced techniques. Suppose that, given a data set of images containing images of cats and dogs, you were asked to build a model that can classify these images into two separate classes. Like every other person, you will start by identifying the images by using some rules given below:
These rules help us identify whether an image is a Dog or a cat. However, the prediction would be flawed if we were to classify an image based on an individual (single) rule. These rules are called weak learners because these rules are not strong enough to classify an image as a cat or dog. Therefore, to ensure our prediction is more accurate, we can combine the prediction from these weak learners by using the majority rule or weighted average. This makes a strong learner model. In the above example, we have defined 5 weak learners, and the majority of these rules (i.e., 3 out of 5 learners predict the image as a cat) give us the prediction that the image is a cat. Therefore, our final output is a cat. How does the Boosting Algorithm Work?The basic principle behind the working of the boosting algorithm is to generate multiple weak learners and combine their predictions to form one strict rule. These weak rules are generated by applying base Machine Learning algorithms on different distributions of the data set. These algorithms generate weak rules for each iteration. After multiple iterations, the weak learners are combined to form a strong learner that will predict a more accurate outcome. 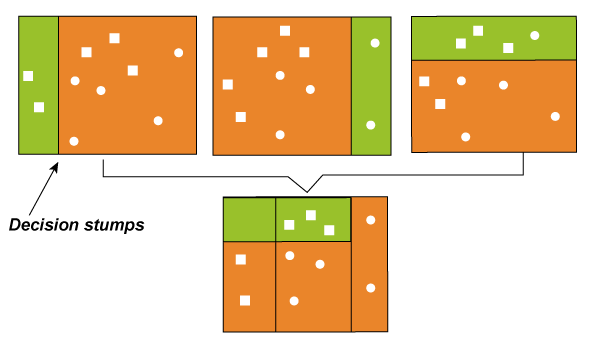
Here's how the algorithm works: Step 1: The base algorithm reads the data and assigns equal weight to each sample observation. Step 2: False predictions made by the base learner are identified. In the next iteration, these false predictions are assigned to the next base learner with a higher weightage on these incorrect predictions. Step 3: Repeat step 2 until the algorithm can correctly classify the output. Therefore, the main aim of Boosting is to focus more on miss-classified predictions. Types of BoostingBoosting methods are focused on iteratively combining weak learners to build a strong learner that can predict more accurate outcomes. As a reminder, a weak learner classifies data slightly better than random guessing. This approach can provide robust prediction problem results, outperform neural networks, and support vector machines for tasks. Boosting algorithms can differ in how they create and aggregate weak learners during the sequential process. Three popular types of boosting methods include: 1. Adaptive boosting or AdaBoost: This method operates iteratively, identifying misclassified data points and adjusting their weights to minimize the training error. The model continues to optimize sequentially until it yields the strongest predictor. AdaBoost is implemented by combining several weak learners into a single strong learner. The weak learners in AdaBoost take into account a single input feature and draw out a single split decision tree called the decision stump. Each observation is weighted equally while drawing out the first decision stump. The results from the first decision stump are analyzed, and if any observations are wrongfully classified, they are assigned higher weights. A new decision stump is drawn by considering the higher-weight observations as more significant. Again if any observations are misclassified, they're given a higher weight, and this process continues until all the observations fall into the right class. AdaBoost can be used for both classification and regression-based problems. However, it is more commonly used for classification purposes. 2. Gradient Boosting: Gradient Boosting is also based on sequential ensemble learning. Here the base learners are generated sequentially so that the present base learner is always more effective than the previous one, i.e., and the overall model improves sequentially with each iteration. The difference in this boosting type is that the weights for misclassified outcomes are not incremented. Instead, the Gradient Boosting method tries to optimize the loss function of the previous learner by adding a new model that adds weak learners to reduce the loss function. The main idea here is to overcome the errors in the previous learner's predictions. This boosting has three main components:
Like AdaBoost, Gradient Boosting can also be used for classification and regression problems. 3. Extreme gradient boosting or XGBoost: XGBoost is an advanced gradient boosting method. XGBoost, developed by Tianqi Chen, falls under the Distributed Machine Learning Community (DMLC) category. The main aim of this algorithm is to increase the speed and efficiency of computation. The Gradient Descent Boosting algorithm computes the output slower since they sequentially analyze the data set. Therefore XGBoost is used to boost or extremely boost the model's performance. XGBoost is designed to focus on computational speed and model efficiency. The main features provided by XGBoost are: 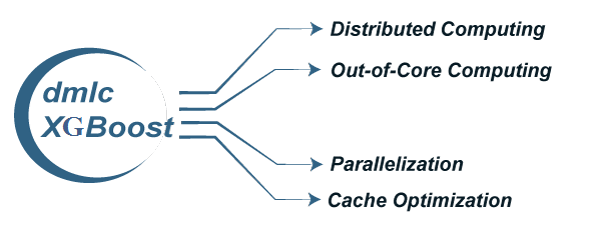
Benefits and Challenges of BoostingThe boosting method presents many advantages and challenges for classification or regression problems. The benefits of boosting include:
And the challenges of boosting include:
Applications of BoostingBoosting algorithms are well suited for artificial intelligence projects across a broad range of industries, including:
Next TopicWhat is Forecasting in Data Mining
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








