| |

Social Media Data Mining MethodsApplying data mining techniques to social media is relatively new as compared to other fields of research related to social network analytics. When we acknowledge the research in social media network analysis dates back to the 1930s. The application that uses data mining techniques developed by industry and academia are already being used commercially. For example, a "Social Media Analytics" organization offers services to us and track social media to provide customers data about how goods and services recognized and discussed through social media networks. Analysts in the organizations have applied text mining algorithms, and detect the propagation models to blogs to create techniques to understand better how data moves through the blogosphere. Data mining techniques can be implemented to social media sites to comprehend information better and to make use of data for analytics, research, and business purposes. Representative Fields include a community or group detection, data diffusion, propagation of audiences, subject detection and tracking, individual behavior analysis, group behavior analysis, and market research for organizations. Representation of DataSimilar to other social media data, it is accepted to use a graph representation to study social media data sets. A graph comprises a set including vertexes (nodes) and edges (links). Users are usually shown as the nodes in the graph. Relationships or corporation between individuals (nodes) is shown as the links in the graph. The graph depiction is common for information extracted from social networking sites where people interact with friends, family, and business associates. It helps to create a social network of friends, family, or business associates. Less apparent is how the graph structure is applied to blogs, wikis, opinion mining, and similar types of online social media platforms. If we consider blogs, One graph representation blogged as nodes and can be regarded as "blog network," and another graph description has blog posts as the nodes, and can be regarded as "post-network." Edges are created in a blog post network when another blog post references another blog post. Other techniques used to represent blog networks concurrently account for individuals, relationships, content, and time simultaneously- called Internet Online Analytical Processing (iOLAP). Wikis can be considered from the context of depicting authors as nodes, and edges are created when the authors contribute to an object. The graphical representation allows the application of classic mathematical graph theory, traditional techniques of analyzing social media platforms and work on mining graph data. The probably big size of the graph used to depict social media platforms can present difficulties for automated processing as restricts on computer memory. The processing speeds are maximized and usually exceeded when trying to cope with huge social media data set. Other challenges to implementing automated procedures to allow social media data mining include identifying and dealing with spam, the variety of formats used in the same subcategory of social media, and continuously altering content and structure. Data Mining- A ProcessNo matter what sort of social media is being studied, some fundamental things are essential to consider the most meaningful outcomes are feasible. Every kind of social media and every data mining purpose applied to social media may involve distinctive methods and algorithms to produce an advantage from data mining. Various data sets and data issues include different kinds of tools. If it is known how to organize the data, a classification tool might be appropriate. If we understand what the data is about, but cannot determine trends and patterns in the data, the use of a clustering tool may be the best. The problem itself can conclude the best approach. There is no other option for understanding the data as much possible before applying data mining techniques as well as understanding the various data mining tools that are available. A subject analyst might be required to help better understand the data set. To better understand the various tools available for data mining, there are a host of data mining and machine learning text and different resources that are available to support more accurate information about a variety of particular data mining techniques and algorithms. Once you understand the issues and select an appropriate data mining approach, consider any preprocessing that needs to be done. A systematic process may also be required to develop an adequate set of data to allow reasonable processing times. Pre-processing should include suitable privacy protection mechanisms. Although social media platforms incorporate huge amounts of openly accessible data, it is important to guarantee individual rights, and social media platform copyrights are secured. The effect of spam should be considered along with the temporal representation. In addition to preprocessing, it is essential to think about the effect of time. Depending upon the inquiry and the research, we may get different outcomes at one time compared to another, although the time segment is an accessible consideration for specific areas. For example, subject detection, influence propagation, and network development, less evident is the effect of time on network identification, group behavior, and marketing. What defines a network at one point in time can be significantly different at another point in time. Group behavior and interests will change after some time, and what was offered to the individuals or groups today may not be trendy tomorrow. With data depicted as a graph, the tasks start with a selected number of nodes, known as seeds. Graphs are traversed, starting with the arrangement of seeds, and as the link structure from the seed nodes is used, data is collected, and the structure itself is also reviewed. Utilizing the link structure to stretch out from the seed set and gather new information is known as crawling the network. The application and algorithms that are executed as a crawler should effectively manage the challenges present in powerful social media platforms such as restricted sites, format changes, and structure errors (invalid links). As the crawler finds the new data, it stores the new data in a repository for further analysis. As link data is found, the crawler updates the data about the network structure. Some social media platforms such as Facebook, Twitter, and Technorati provide Application Programmer Interfaces (APIs) that allow crawler applications to interact with the data sources directly. However, these platforms usually restrict the number of API transactions per day, relying on the affiliation the API user has with the platform. For some platforms, it is possible to collect data (crawl) without utilizing APIs. Given the huge size of the social media platform data available, it might be necessary to restrict the amount of data that the crawler collects. When the crawler has collected the data, some postprocessing may be needed to validate and clean up the data. Traditional social media platforms analysis methods can be applied, for example, centrality measures and group structure studies. In many cases, additional data will be related to a node or a link opening opportunities for more complex methods to consider the more thoughtful semantics that can be exposed with text and data mining techniques. We now focus on two particular social media platform data to further represent how data mining techniques are applied to social media sites. The two major areas are social media platforms, and Blogs are powerful, and rich data sources portray both these areas. The two areas offer potential value to the more extensive scientific network as well as a business organization. Social media platforms: Illustrative ExamplesSocial media platforms like Facebook or LinkedIn comprises of connected users with unique profiles. Users can interact with their friends and family and can share news, photos, story, videos, favorite links, etc. Users have an option to customize their profiles relying on individual preferences, but some common data may incorporate relationship status, birthday, an Email address, and hometown. Users have alternatives to choose how much data they include in their profile and who has access to it. The amount of data accessible via social media platforms have raised security concerns and is a related societal issue. Here, the figure illustrates the hypothetical graph structure diagram for typical social media platforms, and Arrows indicate links to a larger part of the graph. It is important to secure personal identity when working with social media platforms data. Recent reports highlight the need to secure privacy as it has been demonstrated that even anonymizing this sort of data can still reveal individual data when advanced data analysis strategies are utilized. Security settings also can restrict the ability of data mining applications to think about each data on social media platforms. However, some heinous techniques can be utilized to take over the security settings. 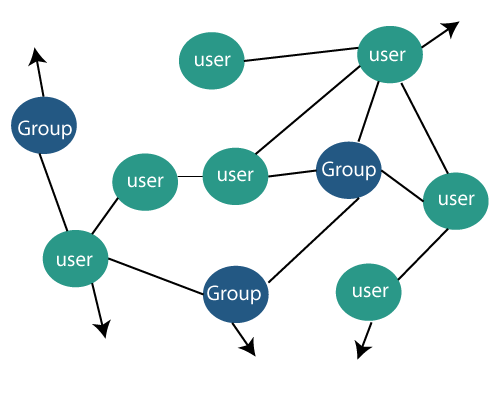
Next TopicClustering in Data Mining
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








