| |

Data Mining Vs Big DataData Mining uses tools such as statistical models, machine learning, and visualization to "Mine" (extract) the useful data and patterns from the Big Data, whereas Big Data processes high-volume and high-velocity data, which is challenging to do in older databases and analysis program. Big Data:Big Data refers to the vast amount that can be structured, semi-structured, and unstructured sets of data ranging in terms of tera-bytes. It is challenging to process a huge amount of data on a single system that's why the RAM of our computer stores the interim calculations during the processing and analyzing. When we try to process such a huge amount of data, it takes much time to do these processing steps on a single system. Also, our computer system doesn't work correctly due to overload. Here we will understand the concept (how much data is produced) with a live example. We all know about Big Bazaar. We as a customer goes to Big Bazaar at least once a month. These stores monitor each of its product that the customers purchase from them, and from which store location over the world. They have a live information feeding system that stores all the data in huge central servers. Imagine the number of Big bazaar stores in India alone is around 250. Monitoring every single item purchased by every customer along with the item description will make the data go around 1 TB in a month. 
What does Big Bazaar do with that data:We know some promotions are running in Big Bazaar on some items. Do we genuinely believe Big Bazaar would just run those products without any full back-up to find those promotions would increase their sales and generate a surplus? That is where Big Data analysis plays a vital role. Using Data Analysis techniques, Big Bazaar targets its new customers as well as existing customers to purchase more from its stores. Big data comprises of 5Vs that is Volume, Variety, Velocity, Veracity, and Value. 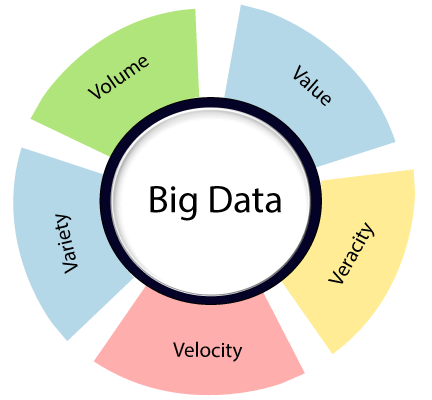
Volume: In Big Data, volume refers to an amount of data that can be huge when it comes to big data. Variety: In Big Data, variety refers to various types of data such as web server logs, social media data, company data. Velocity: In Big Data, velocity refers to how data is growing with respect to time. In general, data is increasing exponentially at a very fast rate. Veracity: Big Data Veracity refers to the uncertainty of data. Value: In Big Data, value refers to the data which we are storing, and processing is valuable or not and how we are getting the advantage of these huge data sets. How to Process Big Data:A very efficient method, known as Hadoop, is primarily used for Big data processing. It is an Open-source software that works on a Distributed Parallel processing method. The Apache Hadoop methods are comprised of the given modules:Hadoop Common:It contains dictionaries and utilities required by other Hadoop modules. Hadoop Distributed File System(HDFS):A distributed file-system which stores data on commodity machine, supporting very high gross bandwidth over the cluster. Hadoop YARN:It is a resource-management Platform responsible for administrating various resources in clusters and using them for scheduling of user's application. Hadoop MapReduce:It is a programming model for huge-scale data processing. Data Mining:As the name suggests, Data Mining refers to the mining of huge data sets to identify trends, patterns, and extract useful information is called data mining. In data Mining, we are looking for hidden data but without any idea about what exactly type of data we are looking for and what we plan to use it for once you find it. When we discover interesting information, we start thinking about how to make use of it to boost business. We will understand the data mining concept with an example: A Data Miner starts discovering the call records of a mobile network operator without any specific target from his manager. The manager probably gives him a significant objective to discover at least a few new patterns in a month. As he begins extracting the data to discover a pattern that there are some international calls on Friday (example) compared to all other days. Now he shares this data with management, and they come up with a plan to shrink international call rates on Friday and start a campaign. Call duration goes high, and customers are happy with low call rates, more customers join, the organization makes more profit as utilization percentage has increased. There are various steps involved in Data Mining:  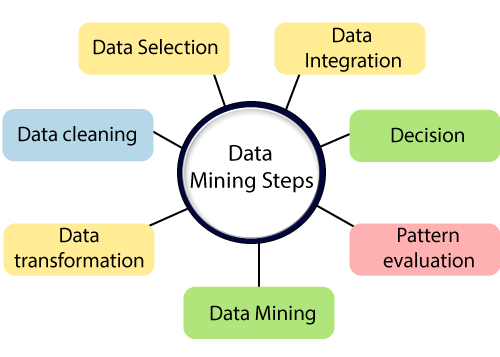
Data Integration:In step first, Data are integrated and collected from various sources. Data Selection:In the first step, we may not collect all the data simultaneously, so in this step, we select only those data which are left, and we think it is useful for data mining. Data Cleaning:In this step, the information we have collected is not clean and may consist of errors, noisy or inconsistent data, missing values. So we need to implement various strategies to get rid of such problems. Data Transformation:The data even after cleaning is not prepared for mining, so we need to transform them into structures for mining. The methods used to achieve this are aggregation, normalization, smoothing, etc. Data Mining:Once the data has transformed, we are ready to implement data mining methods on data to extract useful data and patterns from data sets. Techniques like clustering association rules are among the many various techniques used for data mining. Pattern Evaluation:Patten evaluation contains visualization, removing random patterns, transformation, etc. from the patterns we generated. Decision:It is the last step in data mining. It helps users to make use of the acquired user data to make better data-driven decisions. Difference Between Data Mining and Big Data:
Next Topic#
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








