| |

Weka Data MiningWeka contains a collection of visualization tools and algorithms for data analysis and predictive modelling, together with graphical user interfaces for easy access to these functions. The original non-Java version of Weka was a Tcl/Tk front-end to (mostly third-party) modelling algorithms implemented in other programming languages, plus data preprocessing utilities in C and a makefile-based system for running machine learning experiments. This original version was primarily designed as a tool for analyzing data from agricultural domains. Still, the more recent fully Java-based version (Weka 3), developed in 1997, is now used in many different application areas, particularly for educational purposes and research. Weka has the following advantages, such as:
Weka supports several standard data mining tasks, specifically, data preprocessing, clustering, classification, regression, visualization, and feature selection. Input to Weka is expected to be formatted according to the Attribute-Relational File Format and filename with the .arff extension. All Weka's techniques are predicated on the assumption that the data is available as one flat file or relation, where a fixed number of attributes describes each data point (numeric or nominal attributes, but also supports some other attribute types). Weka provides access to SQL databases using Java Database Connectivity and can process the result returned by a database query. Weka provides access to deep learning with Deeplearning4j. It is not capable of multi-relational data mining. Still, there is separate software for converting a collection of linked database tables into a single table suitable for processing using Weka. Another important area currently not covered by the algorithms included the Weka distribution in sequence modelling. History of Weka
Features of WekaWeka has the following features, such as: 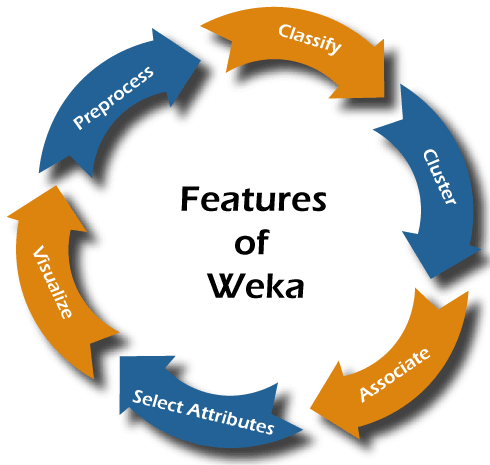
1. PreprocessThe preprocessing of data is a crucial task in data mining. Because most of the data is raw, there are chances that it may contain empty or duplicate values, have garbage values, outliers, extra columns, or have a different naming convention. All these things degrade the results. To make data cleaner, better and comprehensive, WEKA comes up with a comprehensive set of options under the filter category. Here, the tool provides both supervised and unsupervised types of operations. Here is the list of some operations for preprocessing:
2. ClassifyClassification is one of the essential functions in machine learning, where we assign classes or categories to items. The classic examples of classification are: declaring a brain tumour as "malignant" or "benign" or assigning an email to a "spam" or "not_spam" class. After selecting the desired classifier, we select test options for the training set. Some of the options are:
Other than these, we can also use more test options such as Preserve order for % split, Output source code, etc. 3. ClusterIn clustering, a dataset is arranged in different groups/clusters based on some similarities. In this case, the items within the same cluster are identical but different from other clusters. Examples of clustering include identifying customers with similar behaviours and organizing the regions according to homogenous land use. 4. AssociateAssociation rules highlight all the associations and correlations between items of a dataset. In short, it is an if-then statement that depicts the probability of relationships between data items. A classic example of association refers to a connection between the sale of milk and bread. The tool provides Apriori, FilteredAssociator, and FPGrowth algorithms for association rules mining in this category. 5. Select AttributesEvery dataset contains a lot of attributes, but several of them may not be significantly valuable. Therefore, removing the unnecessary and keeping the relevant details are very important for building a good model. Many attribute evaluators and search methods include BestFirst, GreedyStepwise, and Ranker. 6. VisualizeIn the visualize tab, different plot matrices and graphs are available to show the trends and errors identified by the model. Requirements and Installation of WekaWe can install WEKA on Windows, MAC OS, and Linux. The minimum requirement is Java 8 or above for the latest stable versions of Weka. 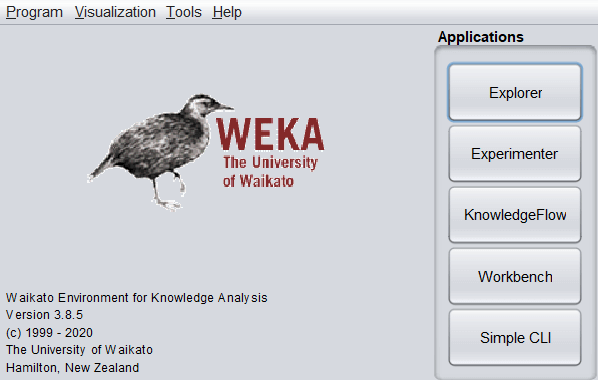
As shown in the above screenshot, five options are available in the Applications category.
java weka.classifiers.trees.ZeroR -t iris.arff Weka Datatypes and Format of DataNumeric (Integer and Real), String, Date, and Relational are the only four datatypes provided by WEKA. By default, WEKA supports the ARFF format. The ARFF, attribute-relation file format, is an ASCII format that describes a list of instances sharing a set of attributes. Every ARFF file has two sections: header and data.
It is important to note that the declaration of the header (@attribute) and the declaration of the data (@data) are case-insensitive. Let's look at the format with a weather forecast dataset: Besides ARFF, the tool supports different file formats such as CSV, JSON, and XRFF. Loading of Data in WekaWEKA allows you to load data from four types of sources:
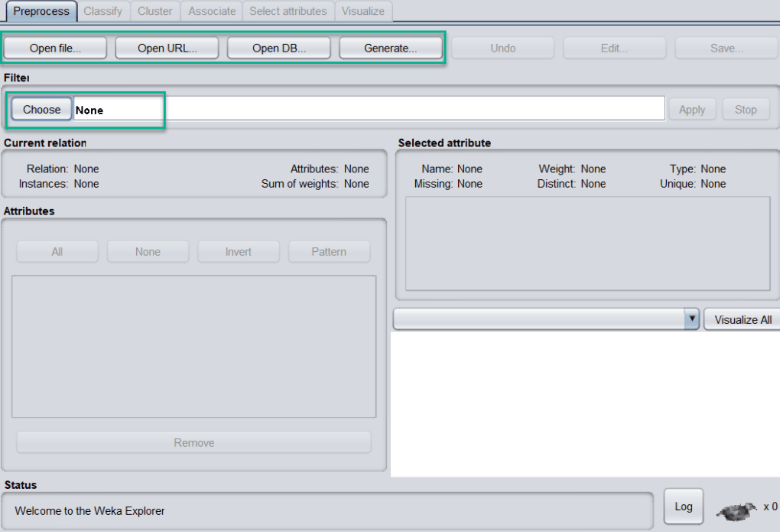
Once data is loaded from different sources, the next step is to preprocess the data. For this purpose, we can choose any suitable filter technique. All the methods come up with default settings that are configurable by clicking on the name: 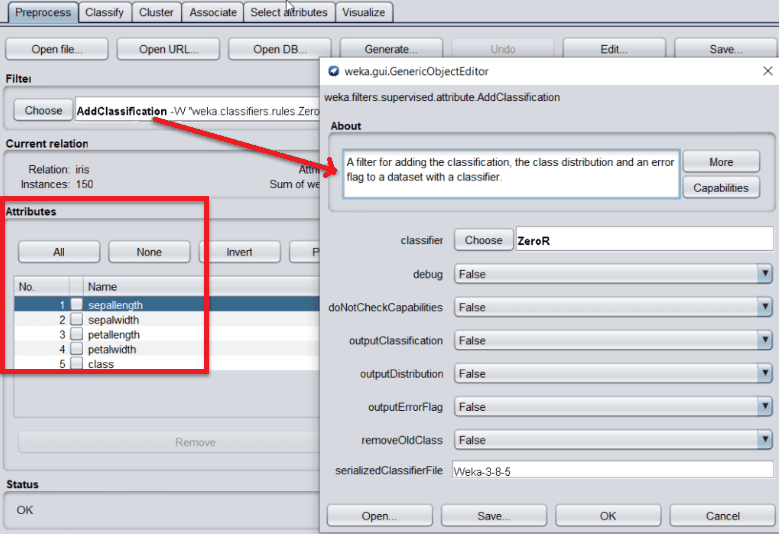
If there are some errors or outliers in one of the attributes, such as sepallength, in that case, we can remove or update it from the Attributes section. Types of Algorithms by WekaWEKA provides many algorithms for machine learning tasks. Because of their core nature, all the algorithms are divided into several groups. These are available under the Explorer tab of the WEKA. Let's look at those groups and their core nature:
Each algorithm has configuration parameters such as batchSize, debug, etc. Some configuration parameters are common across all the algorithms, while some are specific. These configurations can be editable once the algorithm is selected to use. Weka Extension PackagesIn version 3.7.2, a package manager was added to allow the easier installation of extension packages. Some functionality that includes Weka before this version has moved into such extension packages, but this change also makes it easier for others to contribute extensions to Weka and maintain the software, as this modular architecture allows independent updates of the Weka core and individual extensions.
Next Topic#
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








