| |

Clustering in Data MiningClustering is an unsupervised Machine Learning-based Algorithm that comprises a group of data points into clusters so that the objects belong to the same group. Clustering helps to splits data into several subsets. Each of these subsets contains data similar to each other, and these subsets are called clusters. Now that the data from our customer base is divided into clusters, we can make an informed decision about who we think is best suited for this product. 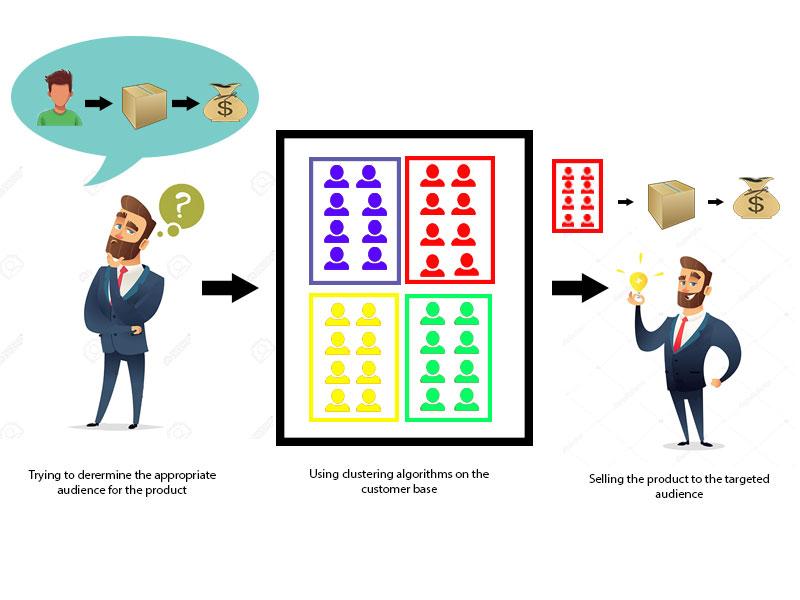
Let's understand this with an example, suppose we are a market manager, and we have a new tempting product to sell. We are sure that the product would bring enormous profit, as long as it is sold to the right people. So, how can we tell who is best suited for the product from our company's huge customer base? 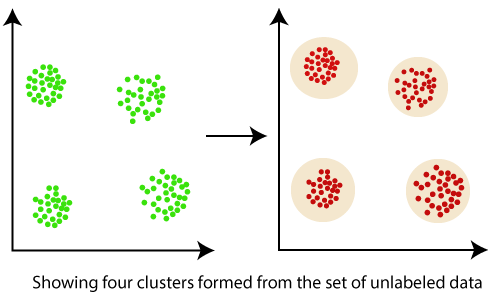
Clustering, falling under the category of unsupervised machine learning, is one of the problems that machine learning algorithms solve. Clustering only utilizes input data, to determine patterns, anomalies, or similarities in its input data. A good clustering algorithm aims to obtain clusters whose:
What is a Cluster?
What is clustering in Data Mining?
Important points:
Applications of cluster analysis in data mining:
Why is clustering used in data mining?Clustering analysis has been an evolving problem in data mining due to its variety of applications. The advent of various data clustering tools in the last few years and their comprehensive use in a broad range of applications, including image processing, computational biology, mobile communication, medicine, and economics, must contribute to the popularity of these algorithms. The main issue with the data clustering algorithms is that it cant be standardized. The advanced algorithm may give the best results with one type of data set, but it may fail or perform poorly with other kinds of data set. Although many efforts have been made to standardize the algorithms that can perform well in all situations, no significant achievement has been achieved so far. Many clustering tools have been proposed so far. However, each algorithm has its advantages or disadvantages and cant work on all real situations. 1. Scalability: Scalability in clustering implies that as we boost the amount of data objects, the time to perform clustering should approximately scale to the complexity order of the algorithm. For example, if we perform K- means clustering, we know it is O(n), where n is the number of objects in the data. If we raise the number of data objects 10 folds, then the time taken to cluster them should also approximately increase 10 times. It means there should be a linear relationship. If that is not the case, then there is some error with our implementation process. 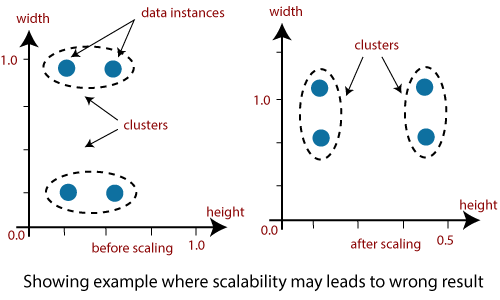
Data should be scalable if it is not scalable, then we can't get the appropriate result. The figure illustrates the graphical example where it may lead to the wrong result. 2. Interpretability: The outcomes of clustering should be interpretable, comprehensible, and usable. 3. Discovery of clusters with attribute shape: The clustering algorithm should be able to find arbitrary shape clusters. They should not be limited to only distance measurements that tend to discover a spherical cluster of small sizes. 4. Ability to deal with different types of attributes: Algorithms should be capable of being applied to any data such as data based on intervals (numeric), binary data, and categorical data. 5. Ability to deal with noisy data: Databases contain data that is noisy, missing, or incorrect. Few algorithms are sensitive to such data and may result in poor quality clusters. 6. High dimensionality: The clustering tools should not only able to handle high dimensional data space but also the low-dimensional space.
Next TopicText Data Mining
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








